Ubuntu环境下搭建Hadoop Eclipse开发环境
简介
本文介绍了在Ubuntu环境下,如何搭建Hadoop的Eclipse开发环境,并以实际的例子为例,演示应用具体的开发步骤。Hadoop伪分布式运行环境的配置,不算复杂,可以参考个人整理的在Ubuntu环境下搭建Hadoop伪分布式模式运行环境。
在安装插件、配置Hadoop的相关信息之后,如果用户创建Hadoop程序,插件会自动导入Hadoop编程接口的Jar文件,这样用户就可以在Eclipse的图形化界面中编写、调试、运行Hadoop程序,也可以在其中查看程序的实时状态、错误信息和运行结果,还可以查看、管理HDFS及文件,使用非常方便,提高了工作效率。
Eclipse及Hadoop插件安装
我个人使用的neon版本的Eclipse,可以去Eclipse官网下载eclipse-jee-neon-2-linux-gtk-x86_64.tar.gz。Hadoop的插件需要和运行版本保持一致,可以在网上找到2.7.3版本对应的插件hadoop-eclipse-plugin-2.7.3.jar。安装非常简单,只需要将tar.gz文件解压后,将hadoop-eclipse-plugin-2.7.3.jar拷贝到eclipse/plugins目录下,重新启动Eclipse。
Eclipse配置
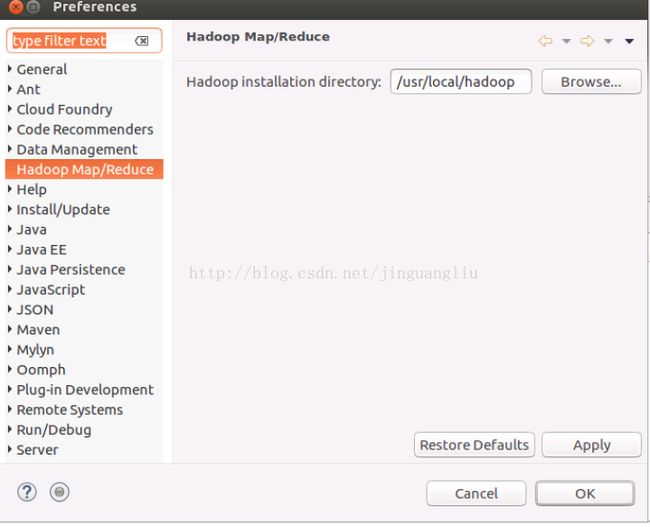
1. 配置Hadoop安装目录
Eclipse重新启动之后,在Eclipse中配置Hadoop安装目录。依次选择: Eclipse---> Window --->Preferences --->Hadoop Map/Reduce,在相应的界面中配置Hadoop安装目录。
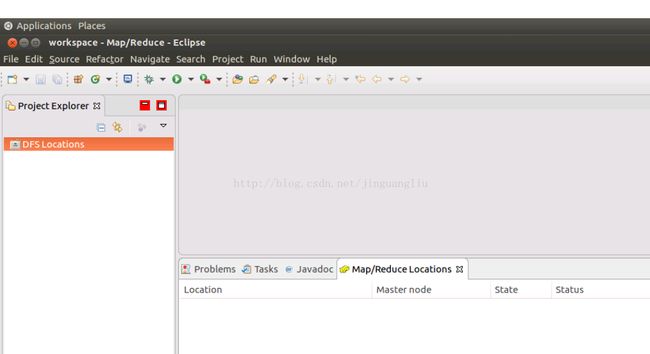
2. 在Eclipse中打开Hadoop试图。依次选择:Eclipse--->Window--->perspective--->other,然后选择Map/Reduced并点击OK。Eclipse会出现Hadoop视图。在左边Project Explorer会出现DFS Locations,下方选择项中会出现Map/Reduce Locations选项卡。
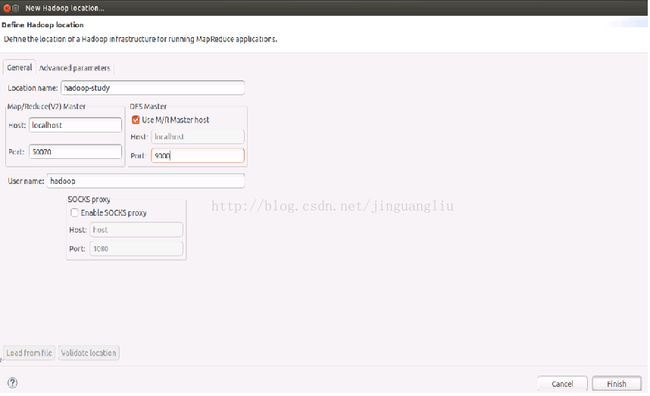
3. 在下方选项卡中选中Map/Reduce Locations,然后再出现的空白处右键点击选择New Hadoop location...,这时会弹出Hadoop Location的窗口。按照下图配置Hadoop:
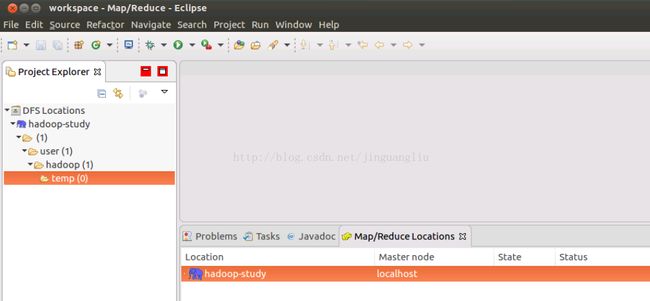
配置完成之后点击finish, Map/Reduce Locations下就会出现新配置的Map/Reduce location。Eclipse界面左边的DFS Locations下面也会出现新配置的DFS,点击"+"可以查看其结构,如下图所示:
我们建立起来了Eclipse的开发环境,接下来我们以一个具体的例子,来演示如何在Eclipse环境下开发Hadoop应用程序。
WordCount程序
使用Maven创建一个maven-archetype-quickstart类型的maven工程,pom.xml配置文件如下:
4.0.0
com.jliu
hadoopstudy
0.0.1-SNAPSHOT
jar
hadoopstudy
http://maven.apache.org
UTF-8
UTF-8
2.7.3
org.apache.hadoop
hadoop-common
${hadoop.version}
org.apache.hadoop
hadoop-hdfs
${hadoop.version}
org.apache.hadoop
hadoop-client
${hadoop.version}
junit
junit
3.8.1
test
package com.jliu.examples;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class WordCount {
public static class TokenizerMapper extends Mapper {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
@Override
protected void map(Object key, Text value, Mapper.Context context)
throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer extends Reducer {
private IntWritable result = new IntWritable();
@Override
protected void reduce(Text key, Iterable values,
Reducer.Context context)
throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
String[] path = new String[2];
path[0] = new String("hdfs://localhost:9000/user/hadoop/wordcount/README.txt");
path[1] = new String("hdfs://localhost:9000/user/hadoop/wordcount/result");
String[] otherArgs = new GenericOptionsParser(conf, path).getRemainingArgs();
//create a new job
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
// specify various job-specific parameters
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
for (int i = 0; i < otherArgs.length - 1; i++) {
FileInputFormat.addInputPath(job, new Path(otherArgs[i]));
}
FileOutputFormat.setOutputPath(job, new Path(otherArgs[otherArgs.length - 1]));
//submit the job, them poll for progress until the job is complete
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
hadoop@bob-virtual-machine:~/hadoop-2.7.3$ hadoop fs -mkdir wordcount
hadoop@bob-virtual-machine:~/hadoop-2.7.3$ hadoop fs -put README.txt wordcount/README.txt
hadoop@bob-virtual-machine:~/hadoop-2.7.3$ hadoop fs -ls wordcount
Found 1 items
-rw-r--r-- 1 hadoop supergroup 1366 2017-01-31 21:22 wordcount/README.txt
这样我们的Eclipse开发环境就搭建好了,并通过了简单的验证。