LDA主题模型学习总结
本篇主要总结隐含狄利克雷分布(Latent Dirichlet Allocation,以下简称LDA)
1.贝叶斯定理
贝叶斯定理是关于随机事件A和B的条件概率的定理。
![]()
在贝叶斯定理中:
P(A|B)是在事件B发生的条件下事件A发生的条件概率,也由于得自B的取值而被称作A的后验概率。
P(A)是A的先验概率(或边缘概率)。之所以称为"先验"是因为它不考虑任何B方面的因素。
P(B|A)是在事件A发生的条件下事件B发生的条件概率,也由于得自A的取值而被称作B的后验概率。
P(B)是B的先验概率或边缘概率。
理解:为什么称P(B|A)为B事件的后验概率?
例子:假设高中学校男女比例1:1,我们看到从校园出来10人7男3女,再来估计这所高中的男女比例。
首先B事件为男生,P(B)为先验概率,先验概率即我们先验知识的估计,当我们不知道学校男女比例的时候,我们假设男女比例是相等的,即先验概率P(B)为0.5,事件A是我们看到的从校园走出来的10人7男3女,P(B|A)是在事件A发生的条件下,即当事件A发生后我们再去估计P(B|A)的概率值,即后验概率,即观察到事件A的7男3女事实后(即我们的训练集数据)我们就会感觉这个学校的男生比女生的人数多,所以P(B|A)就会偏向于男生多的概率即后验概率。我们观察到的事件A,就认为男女的概率分布应该是偏向于A事件发生的概率,P(B)为男生概率设为 ,观察到事件A即似然函数是
,观察到事件A即似然函数是![]() ,即先验概率+观察到数据=后验概率
,即先验概率+观察到数据=后验概率![]() 。
。
按这些术语,叶斯定理可表述为:
后验概率 = (似然性*先验概率)/标准化常量
后验概率与先验概率和相似度的乘积成正比。
另外,P(B|A)/P(B)也有时被称作标准似然度(standardised likelihood),贝叶斯定理可表述为:
后验概率 = 标准似然度*先验概率
举例:
假设高中学校里男女比例1:1,女生中文科比例为0.8,男生中文科生比例为0.2,计算随机一个学生是文科生则该生是女生的概率。
分析:
A1为学生为女生,A2表示学生是男生,B1表示学生是文科生,B2表示学生为理科生。
P(A1|B1)即为学生为文科生下为女生的概率。
已知:
P(A1) = 0.5, P(A2) = 0.5, P(B1|A1) = 0.8, P(B1|A2) = 0.2
则:p(B1) = P(B1|A1)*P(A1)+P(B1|A2)*P(A2) = 0.5
P(A1|B1) = P(B1|A1)*P(A1)/p(B1) = 0.8
2.二项式分布和共轭分布
2.1 二项式分布
二项分布(Binomial Distribution),即重复n次的伯努利实验。二项分布公式如果事件发生的概率是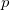 ,则不发生的概率
,则不发生的概率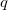 =1-,N次独立重复实验中发生K次的概率是
=1-,N次独立重复实验中发生K次的概率是
![]()
二项式分布用来估计观察到的事实的概率为观察到事件A即为似然函数,为男生的比例,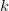 为观察事件中男生的个数,
为观察事件中男生的个数,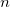 为观察到的人数总数。
为观察到的人数总数。
2.2 共轭分布
当先验分布和后验分布为同一分布时,先验分布(后验分布)与似然分布为共轭分布。
二项式分布的共轭分布是Beta分布,Beta分布概率密度函数表达式为:
![]()
其中![]() 是Gamma函数,是阶乘函数在实数与复数上的扩展表达式:
是Gamma函数,是阶乘函数在实数与复数上的扩展表达式:
![]()
![]() (推导过程)
(推导过程)
![]() (
( 为正整数)
为正整数)
beta分布可以看作一个概率的概率分布,它可以给出了所有概率出现的可能性大小。
后验概率![]() 推导如下:
推导如下:
![]() ∝
∝![]()
![]()
∝![]()
归一化后,得到后验概率:
Beta分布的期望:
![]()
![]()
![]()
![]()
![]()
![]()
Beta分布的方差:
![]()
2.3 延伸多项式和Dirichlet分布
上面的例子中只有男生女生两类分类,如果我们要分类出文科生,理科生和艺术生三类呢,那么就是三项式,现实中存在根据多维的分类,那么我们就能得到多项式分布,而多项的共轭分布则称为Dirichlet分布。
根据二项式我们可以推出多项式分布为k时,表达式为:
![]()
其中![]() ,
, ![]()
k维多项式分布的共轭分布为k维Dirichlet分布:
![]()
其中 ![]()
Dirichlet分布的期望为:
![]()
3. LDA主题模型
已知条件:我们有M篇文档,对应第d个文档中有![]() 个词。如图:
个词。如图:
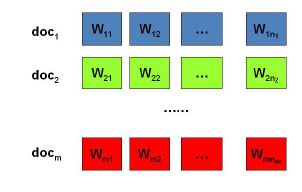
问题:找到每一篇文档的主题分布和每一个主题中词的分布。
首先我们假设主题模型的个数K,那么LDA模型的解决方案为如下图:
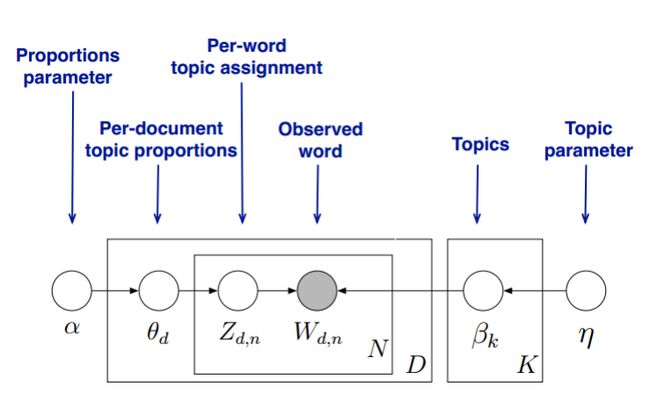
每一篇文档的主题分布和每一个主题中词的分布是两个独立的分布,我们可以分别假设。
Dirichlet分布是多项式的概率分布,我们目的是得到文档在各个主题的分布概率,所以对任意一文档 ,我们可以使用Dirichlet分布作为主题分布
,我们可以使用Dirichlet分布作为主题分布![]() 的先验分布:
的先验分布:
![]()
其中,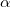 为分布的超参数,是一个K维向量,
为分布的超参数,是一个K维向量,![]() 为K维向量是文档在属于K个主题的概率,
为K维向量是文档在属于K个主题的概率,![]() 。
。
对于任意一篇文档的多项式分布(似然函数),根据这篇文档的各个词的主题分布,修正主题分布,我们可以使用多项式分布来从主题分布![]() 中得到这篇文档主题
中得到这篇文档主题![]() 的分布为:
的分布为:
![]()
如果在第个文档中标记为第k个主题的词中个数为![]() ,对应k个主题的个数表示为:
,对应k个主题的个数表示为:
![]()
根据Dirichlei共轭分布的特性可以推出:
![]()
其中,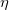 为分布的超参数,是个V维向量,V是所有文档中的所有词的个数,
为分布的超参数,是个V维向量,V是所有文档中的所有词的个数,![]() 是V维向量是主题对应所有词的概率,
是V维向量是主题对应所有词的概率,![]() 。
。
对于任意一个主题,其词分布我们也可以假设为Dirichlet分布:
![]()
我们看到的词![]() 的多项式分布:
的多项式分布:
![]()
我们记第k个主题中第v个词的个数为![]() ,则主题k中含全部词的分别得个数为:
,则主题k中含全部词的分别得个数为:
![]()
利用共轭性质,得到![]() 后验分布:
后验分布:
![]()
首先![]() ,
,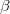 是我们先验分布的超参数,即是根据先验知识决定,选择合适的主题数K,然后根据数据文档,不断更新
是我们先验分布的超参数,即是根据先验知识决定,选择合适的主题数K,然后根据数据文档,不断更新![]() ,超参数。
,超参数。
参考资料:
https://www.zhihu.com/question/30269898
https://www.cnblogs.com/pinard/p/6831308.html