手把手教你批量读取数据文件
曾经有网友问我如何读取磁盘中数个文件的数据,并把这些数据合并到一张数据表中。这期就跟大家讲讲如何完成如下四种情况的文件批量读取:
1、对于文件名有规律的情况
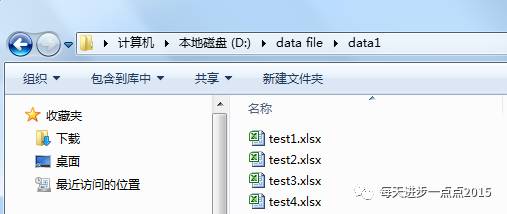
解决方案:
# 设置R的工作空间
setwd('D:\\data file\\data1')
#res <- NULL
# 初始化数据框,用于后面的数据合并
data1 <- data.frame()
#通过循环完成数据合并
for (i in 1:4){
# 构造数据路径
path <- paste0(getwd(),'\\','test',i,'.xlsx')
#res <- c(res,path)
# 读取并合并数据
data1 <- rbind(data1,read_excel(path = path))
}
2、对于文件名没有规律的情况
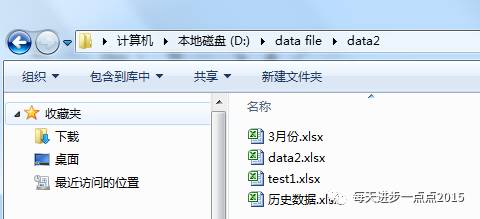
解决方案:
# 设置工作空间
setwd('D:\\data file\\data2')
# 读取该工作空间下的所有文件名
filenames <- dir()
# 初始化数据框,用于后面的数据合并
data2 <- data.frame()
#通过循环完成数据合并
for (i in filenames){
# 构造数据路径
path <- paste0(getwd(),'\\',i)
#res <- c(res,path)
# 读取并合并数据
data2 <- rbind(data2,read_excel(path = path))
}
3、对于文件名没有规律的情况,并且只读取某做后缀的文件
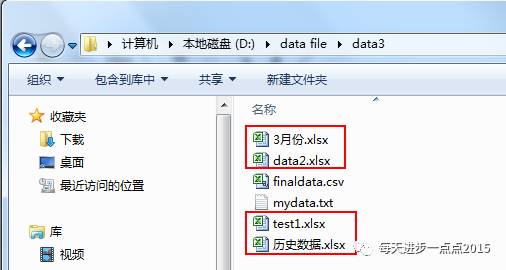
解决方案:
# 设置工作空间
setwd('D:\\data file\\data3')
# 读取该工作空间下的所有文件名
filenames <- dir()
# 通过正则,获取所有xlsx结尾的文件名
filenames2 <- grep('\\.xlsx', filenames, value = TRUE)
# 初始化数据框,用于后面的数据合并
data3 <- data.frame()
#通过循环完成数据合并
for (i in filenames2){
# 构造数据路径
path <- paste0(getwd(),'\\',i)
#res <- c(res,path)
# 读取并合并数据
data3 <- rbind(data3,read_excel(path = path))
}
4、文件内容结构不一致,但变量名称一致
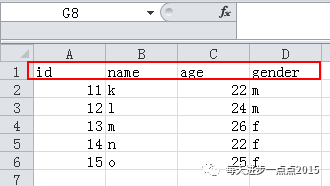
解决方案
# 加载第三方扩展包,用于编写SQL语句
library(sqldf)
# 设置工作空间
setwd('D:\\data file\\data4')
# 读取该工作空间下的所有文件名
filenames <- dir()
# 通过正则,获取所有xlsx结尾的文件名
filenames2 <- grep('\\.xlsx', filenames, value = TRUE)
# 初始化数据框,用于后面的数据合并
data4 <- data.frame()
#通过循环完成数据合并
for (i in filenames2){
# 构造数据路径
path <- paste0(getwd(),'\\',i)
#res <- c(res,path)
# 使用read_excel函数读取xlsx文件
data <- read_excel(path = path)
# 使用sqldf函数编写SQL语句,并把结果合并起来
data4 <- rbind(data4, sqldf("select id,name,gender,age from data"))
}
以上四种情况是日常工作中最为常见的,这里通过R语言完成了这几种批量读取数据的落地,希望可以帮助到需要的朋友。
下期预告:SVM理论与实战
每天进步一点点2015
学习与分享,取长补短,关注小号!

长按识别二维码 马上关注