【医学图像分割网络】之ScSE U-Net网络PyTorch复现
【医学图像分割网络】之SCSE U-Net网络PyTorch复现
1.内容
U-Net网络算是医学图像分割领域的开山之作,我接触深度学习到现在大概将近大半年时间,看到了很多基于U-Net网络的变体,后续也会继续和大家一起分享学习。这次分享ScSE+U-Net的一个改进版。
[2018-MICCAI-Roy] Concurrent Spatial and Channel ‘Squeeze & Excitation’ in Fully Convolutional Networks
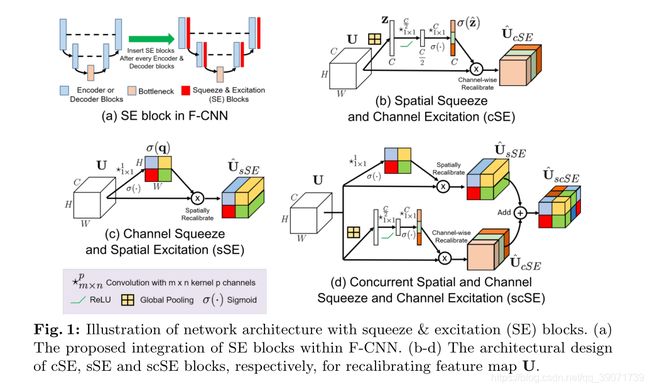
1)这篇文章是针对医学场景提出的,目前大部分网络都是改善空间编码或网络连接方式去解决分割精度。这篇文章提出了压缩与激励(SE)模块,SE块通过全局平均池来消除空间依赖性,以学习特定通道,该模块用于图像分类中特征映射的通道重新校准,(scSE)沿通道和空间分别重新校准特征图。2)给我的感觉极其类似后面出现注意力网络,有可能注意力网络参考了这样一个工作,都是利用空间或者信道方面对特征图进行重新校正,以强化需要重点学习的区域。
2.代码
"""
SCSE + U-Net
"""
import torch
from torch import nn
import torch.nn.functional as F
from torchsummary import summary
# SCSE模块
class SCSE(nn.Module):
def __init__(self, in_ch):
super(SCSE, self).__init__()
self.spatial_gate = SpatialGate2d(in_ch, 16) # 16
self.channel_gate = ChannelGate2d(in_ch)
def forward(self, x):
g1 = self.spatial_gate(x)
g2 = self.channel_gate(x)
x = g1 + g2 # x = g1*x + g2*x
return x
# 空间门控
class SpatialGate2d(nn.Module):
def __init__(self, in_ch, r=16):
super(SpatialGate2d, self).__init__()
self.linear_1 = nn.Linear(in_ch, in_ch // r)
self.linear_2 = nn.Linear(in_ch // r, in_ch)
def forward(self, x):
input_x = x
x = x.view(*(x.shape[:-2]), -1).mean(-1)
x = F.relu(self.linear_1(x), inplace=True)
x = self.linear_2(x)
x = x.unsqueeze(-1).unsqueeze(-1)
x = torch.sigmoid(x)
x = input_x * x
return x
# 通道门控
class ChannelGate2d(nn.Module):
def __init__(self, in_ch):
super(ChannelGate2d, self).__init__()
self.conv = nn.Conv2d(in_ch, 1, kernel_size=1, stride=1)
def forward(self, x):
input_x = x
x = self.conv(x)
x = torch.sigmoid(x)
x = input_x * x
return x
# 编码连续卷积层
def contracting_block(in_channels, out_channels):
block = torch.nn.Sequential(
nn.Conv2d(kernel_size=(3, 3), in_channels=in_channels, out_channels=out_channels, padding=1),
nn.BatchNorm2d(out_channels),
nn.ReLU(),
nn.Conv2d(kernel_size=(3, 3), in_channels=out_channels, out_channels=out_channels, padding=1),
nn.BatchNorm2d(out_channels),
nn.ReLU()
)
return block
# 解码上采样卷积层
class expansive_block(nn.Module):
def __init__(self, in_channels, mid_channels, out_channels):
super(expansive_block, self).__init__()
self.up = nn.ConvTranspose2d(in_channels, in_channels // 2, kernel_size=(3, 3), stride=2, padding=1,
output_padding=1, dilation=1)
self.block = nn.Sequential(
nn.Conv2d(kernel_size=(3, 3), in_channels=in_channels, out_channels=mid_channels, padding=1),
nn.BatchNorm2d(mid_channels),
nn.ReLU(),
nn.Conv2d(kernel_size=(3, 3), in_channels=mid_channels, out_channels=out_channels, padding=1),
nn.BatchNorm2d(out_channels),
nn.ReLU()
)
self.spa_cha_gate = SCSE(out_channels)
def forward(self, d, e=None):
d = self.up(d)
# d = F.interpolate(d, scale_factor=2, mode='bilinear', align_corners=True)
# concat
if e is not None:
cat = torch.cat([e, d], dim=1)
out = self.block(cat)
else:
out = self.block(d)
out = self.spa_cha_gate(out)
return out
# 输出层
def final_block(in_channels, out_channels):
block = nn.Sequential(
nn.Conv2d(kernel_size=(1, 1), in_channels=in_channels, out_channels=out_channels),
# nn.BatchNorm2d(out_channels),
# nn.ReLU()
)
return block
# SCSE U-Net
class SCSEUnet(nn.Module):
def __init__(self, in_channel, out_channel):
super(SCSEUnet, self).__init__()
# Encode
self.conv_encode1 = nn.Sequential(contracting_block(in_channels=in_channel, out_channels=32), SCSE(32))
self.conv_pool1 = nn.MaxPool2d(kernel_size=2, stride=2)
self.conv_encode2 = nn.Sequential(contracting_block(in_channels=32, out_channels=64), SCSE(64))
self.conv_pool2 = nn.MaxPool2d(kernel_size=2, stride=2)
self.conv_encode3 = nn.Sequential(contracting_block(in_channels=64, out_channels=128), SCSE(128))
self.conv_pool3 = nn.MaxPool2d(kernel_size=2, stride=2)
self.conv_encode4 = nn.Sequential(contracting_block(in_channels=128, out_channels=256), SCSE(256))
self.conv_pool4 = nn.MaxPool2d(kernel_size=2, stride=2)
# Bottleneck
self.bottleneck = torch.nn.Sequential(
nn.Conv2d(kernel_size=3, in_channels=256, out_channels=512, padding=1),
nn.BatchNorm2d(512),
nn.ReLU(),
nn.Conv2d(kernel_size=3, in_channels=512, out_channels=512, padding=1),
nn.BatchNorm2d(512),
nn.ReLU(),
SCSE(512)
)
# Decode
self.conv_decode4 = expansive_block(512, 256, 256)
self.conv_decode3 = expansive_block(256, 128, 128)
self.conv_decode2 = expansive_block(128, 64, 64)
self.conv_decode1 = expansive_block(64, 32, 32)
self.final_layer = final_block(32, out_channel)
def forward(self, x):
# set_trace()
# Encode
encode_block1 = self.conv_encode1(x)
encode_pool1 = self.conv_pool1(encode_block1)
encode_block2 = self.conv_encode2(encode_pool1)
encode_pool2 = self.conv_pool2(encode_block2)
encode_block3 = self.conv_encode3(encode_pool2)
encode_pool3 = self.conv_pool3(encode_block3)
encode_block4 = self.conv_encode4(encode_pool3)
encode_pool4 = self.conv_pool4(encode_block4)
# Bottleneck
bottleneck = self.bottleneck(encode_pool4)
# Decode
decode_block4 = self.conv_decode4(bottleneck, encode_block4)
decode_block3 = self.conv_decode3(decode_block4, encode_block3)
decode_block2 = self.conv_decode2(decode_block3, encode_block2)
decode_block1 = self.conv_decode1(decode_block2, encode_block1)
final_layer = self.final_layer(decode_block1)
out = torch.sigmoid(final_layer) # 可注释,根据情况
return out