EM,VB,Gibbs Sampling解高斯混合模型
高斯混合模型
假设数据产生过程如下:
z ∼ M u t ( π ) z \sim Mut(\pi) z∼Mut(π)
x ∣ z ∼ N ( μ z , σ z 2 ) x|z \sim N(\mu_z,\sigma_z^2) x∣z∼N(μz,σz2)
记 θ = { π , μ 1 , . . . , μ K , σ 1 , . . . , σ K } \theta = \{\pi,\mu_1,...,\mu_K,\sigma_1,...,\sigma_K\} θ={π,μ1,...,μK,σ1,...,σK}为这个模型的所有参数
观察数据为 D = { x i } N D=\{x_i\}_N D={xi}N
采用极大似然估计参数 θ \theta θ
l o g ( p ( D ; θ ) ) = ∑ i = 1 N l o g ( p ( x i ; θ ) ) log(p(D;\theta))=\sum_{i=1}^Nlog(p(x_i;\theta)) log(p(D;θ))=i=1∑Nlog(p(xi;θ))
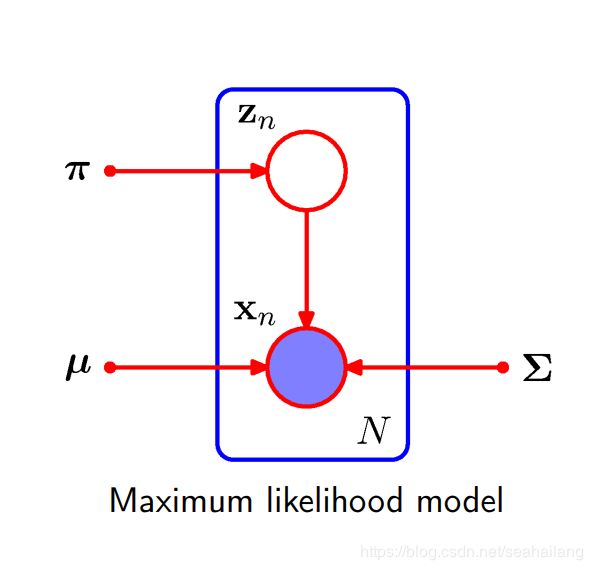
EM算法
直接对上述结果进行优化,由于高斯分布的参数形式比较复杂,并不是那么好计算。
注意到
l o g ( p ( D ; θ ) ) = ∑ i = 1 N l o g ( p ( x i ; θ ) ) = ∑ i = 1 N l o g ( ∑ z i = 1 K p ( x i , z i ; θ ) ) = ∑ i = 1 N l o g ( ∑ z i = 1 K Q ( z i ) p ( x i , z i ; θ ) Q ( z i ) ) ≥ ∑ i = 1 N ∑ z i = 1 K Q ( z i ) l o g ( p ( x i , z i ; θ ) Q ( z i ) ) log(p(D;\theta))=\sum_{i=1}^Nlog(p(x_i;\theta))\newline =\sum_{i=1}^Nlog\left (\sum_{z_i=1}^K {p(x_i,z_i;\theta)} \right)\newline =\sum_{i=1}^Nlog\left (\sum_{z_i=1}^K Q(z_i)\frac{p(x_i,z_i;\theta)}{Q(z_i)} \right)\newline \geq \sum_{i=1}^N\sum_{z_i=1}^K Q(z_i)log \left (\frac{p(x_i,z_i;\theta)}{Q(z_i)} \right) log(p(D;θ))=i=1∑Nlog(p(xi;θ))=i=1∑Nlog(zi=1∑Kp(xi,zi;θ))=i=1∑Nlog(zi=1∑KQ(zi)Q(zi)p(xi,zi;θ))≥i=1∑Nzi=1∑KQ(zi)log(Q(zi)p(xi,zi;θ))
最后一步就是Jenssen不等式
注意到,当Jenssen不等式取等号时:
p ( x i , z i ; θ ) Q ( z i ) = c for any z i \frac{p(x_i,z_i;\theta)}{Q({z_i})}=c \text{ \ \ \ \ for any $z_i$} Q(zi)p(xi,zi;θ)=c for any zi
只有 Q ( z i ) = p ( z i ∣ x i ; θ ) Q(z_i )=p(z_i|x_i;\theta) Q(zi)=p(zi∣xi;θ)时,这个式子才是成立的
这样可以采用坐标上升法去求得最优的 Q ( z i ) Q(z_i) Q(zi)和 θ \theta θ
E-step:
固定 θ ,最优化 Q ( z i ) : Q ( z i ) = p ( z i ∣ x i ; θ ) \text{固定$\theta$,最优化$Q(z_i)$ : }\\ Q(z_i)=p(z_i|x_i;\theta) 固定θ,最优化Q(zi) : Q(zi)=p(zi∣xi;θ)
M-step:
固定 Q ( z i ) ,最优化 θ : θ = a r g m a x θ ∑ i = 1 N ∑ z i = 1 K Q ( z i ) l o g ( p ( x i , z i ; θ ) Q ( z i ) ) \text{固定$Q(z_i)$,最优化$\theta$:}\\ \theta=argmax_{\theta} \sum_{i=1}^N\sum_{z_i=1}^K Q(z_i)log \left (\frac{p(x_i,z_i;\theta)}{Q(z_i)} \right) 固定Q(zi),最优化θ:θ=argmaxθi=1∑Nzi=1∑KQ(zi)log(Q(zi)p(xi,zi;θ))
交替进行这两步,即可得到最优的 Q ( z i ) Q(z_i) Q(zi)和 θ \theta θ
贝叶斯高斯混合模型
采用极大似然估计不符合贝叶斯学派的一贯作风。我们需要对上述模型加各种先验,使其成为一个贝叶斯模型。
也就是是,对多项分布,我们加上一个共轭的Dirichlet分布作为先验,对于正态分布的,我们加一个共轭的Normal-Wishart 分布作为先验
π ∼ D i r ( α ) \pi \sim \mathcal{Dir}(\alpha) π∼Dir(α)
Λ = d i a g ( σ 1 2 , . . . , σ k 2 ) ∼ W ( W , ν ) \bold\Lambda= diag(\sigma_1^2,...,\sigma_k^2)\sim \mathcal{W}(\bold W,\nu) Λ=diag(σ12,...,σk2)∼W(W,ν)
μ ∼ N ( μ 0 , ( λ Λ ) − 1 ) \bold{\mu} \sim \mathcal{N}(\bold \mu_0,(\lambda\bold \Lambda)^{-1}) μ∼N(μ0,(λΛ)−1)
z ∼ M u t ( π ) z \sim \mathcal{Mut}(\pi) z∼Mut(π)
x ∣ z ∼ N ( μ z , σ z 2 ) x|z \sim \mathcal{N}(\mu_z,\sigma_z^2) x∣z∼N(μz,σz2)
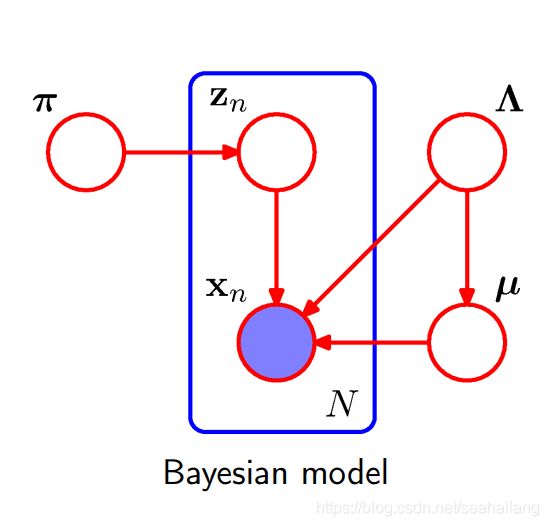
现在将先验参数视为超参数,接下来的过程中,我们认为超参数是固定的
将数据集记为 X = { x i } N \bold X = \{x_i\}_N X={xi}N,所有的隐变量记为 Z = { π , Λ , μ , z i } N \bold Z=\{\pi,\bold\Lambda,\mu,z_i\}_N Z={π,Λ,μ,zi}N
贝叶斯方法就是最大化后验概率
p ( Z ∣ X ) p(Z|X) p(Z∣X)
现在我们检查一下我们已知什么,我们已知 p ( Z ) , p ( X ∣ Z ) p(Z),p(X|Z) p(Z),p(X∣Z),而
p ( Z ∣ X ) = p ( X ∣ Z ) p ( Z ) p ( X ) p(Z|X)=\frac{p(X|Z)p(Z)}{p(X)} p(Z∣X)=p(X)p(X∣Z)p(Z)
p ( X ) = ∫ Z p ( X ∣ Z ) p ( Z ) d Z p(X) = \int_{Z}p(X|Z)p(Z)dZ p(X)=∫Zp(X∣Z)p(Z)dZ
这个积分显然是不易求得的。
变分推断
无法求出 p ( Z ∣ X ) p(Z|X) p(Z∣X),我们换一种思路,求出一个与 p ( Z ∣ X ) p(Z|X) p(Z∣X)接近的分布 q ( Z ) q(Z) q(Z),以后所有用到 p ( Z ∣ X ) p(Z|X) p(Z∣X)的地方,全部用 q ( Z ) q(Z) q(Z)代替
如何算是接近的分布呢,我们最小化Q和后验的KL距离
q ∗ ( Z ) = a r g m a x q D K L ( q ( Z ) ∣ ∣ p ( Z ∣ X ) ) q^*(Z) = argmax_q D_{KL}(q(Z)||p(Z|X)) q∗(Z)=argmaxqDKL(q(Z)∣∣p(Z∣X))
KL距离为
D K L ( q ( Z ) ∣ ∣ p ( Z ∣ X ) = ∫ q ( Z ) l o g q ( Z ) p ( Z ∣ X ) d Z = − ∫ q ( Z ) l o g p ( Z , X ) p ( X ) q ( Z ) d Z = ∫ q ( Z ) p ( X ) d Z − [ ∫ q ( Z ) l o g p ( Z , X ) d Z − ∫ q ( Z ) l o g q ( Z ) d Z ] = p ( X ) − [ ∫ q ( Z ) l o g p ( Z , X ) d Z − ∫ q ( Z ) l o g q ( Z ) d Z ] = p ( X ) − E L O B D_{KL}(q(Z)||p(Z|X) \\= \int q(Z)log\frac{q(Z)}{p(Z|X)}dZ\\ =-\int q(Z)log\frac{p(Z,X)}{p(X)q(Z)}dZ\\ = \int q(Z)p(X)dZ -\\ \left[\int q(Z)log\ p(Z,X)dZ-\int q(Z)log \ q(Z)dZ\right]\\ =p(X)-\left[\int q(Z)log\ p(Z,X)dZ-\int q(Z)log \ q(Z)dZ\right]\\ =p(X)-ELOB DKL(q(Z)∣∣p(Z∣X)=∫q(Z)logp(Z∣X)q(Z)dZ=−∫q(Z)logp(X)q(Z)p(Z,X)dZ=∫q(Z)p(X)dZ−[∫q(Z)log p(Z,X)dZ−∫q(Z)log q(Z)dZ]=p(X)−[∫q(Z)log p(Z,X)dZ−∫q(Z)log q(Z)dZ]=p(X)−ELOB
由于p(X)是固定的,最小化KL距离,等价于最大化证据下界(evidence low bound)
E L O B = ∫ q ( Z ) l o g p ( Z , X ) d Z − ∫ q ( Z ) l o g q ( Z ) d Z ELOB=\int q(Z)log\ p(Z,X)dZ-\int q(Z)log \ q(Z)dZ ELOB=∫q(Z)log p(Z,X)dZ−∫q(Z)log q(Z)dZ
为了简化处理,我们对自己所用的q(Z)采用平均场假设:
q ( Z ) = ∏ j = 1 M q j ( z j ) q(Z) = \prod _{j=1}^Mq_j(z_j) q(Z)=j=1∏Mqj(zj)
那么 E L O B = ∫ . . . ∫ ∏ q j ( z j ) l o g p ( Z , X ) d z 0 . . . d z M − ∫ . . . ∫ ∏ q j ( z j ) ∑ l o g q ( z j ) d z 0 . . . d z M ELOB=\int ...\int \prod q_j(z_j)log \ p(Z,X)dz_0...dz_M - \int ...\int \prod q_j(z_j)\sum log \ q(z_j)dz_0...dz_M ELOB=∫...∫∏qj(zj)log p(Z,X)dz0...dzM−∫...∫∏qj(zj)∑log q(zj)dz0...dzM
注意到ELOB实际上是 q i ( z i ) q_i(z_i) qi(zi)的泛函
对任意i,
E L O B = ∫ q i ( z i ) E j ≠ i [ l o g p ( Z , X ) ] d z i − ∫ q i ( z i ) l o g q i ( z i ) d z i − ∑ j ≠ i ∫ q j ( z j ) l o g q i ( z j ) d z j ELOB = \int q_i(z_i)E_{j\ne i}[log\ p(Z,X)]dz_i-\int q_i(z_i)log \ q_i(z_i)dz_i-\sum_{j\ne i}\int q_j(z_j)log\ q_i(z_j)dz_j ELOB=∫qi(zi)Ej̸=i[log p(Z,X)]dzi−∫qi(zi)log qi(zi)dzi−j̸=i∑∫qj(zj)log qi(zj)dzj
泛函取极值的条件(欧拉-拉格朗日方程)为
∂ F ∂ q − d d z ∂ F ∂ q ′ = 0 \frac{\partial F}{\partial q}-\frac{d}{dz}\frac{\partial F}{\partial q'} = 0 ∂q∂F−dzd∂q′∂F=0
所以对任意i
E j ≠ i [ l o g p ( Z , X ) ] − l o g q i ( z i ) − c o n s t = 0 E_{j\ne i}[log \ p(Z,X)]-log\ q_i(z_i)-const=0 Ej̸=i[log p(Z,X)]−log qi(zi)−const=0
得到
q i ( z i ) = 1 C exp E j ≠ i [ l o g p ( Z , X ) ] q_i(z_i)=\frac{1}{C}\exp{E_{j\ne i}[log \ p(Z,X)]} qi(zi)=C1expEj̸=i[log p(Z,X)]
这样,变分推断的最优解也可以用坐标上升的方式解决:
依次去i = 1,…,M 固定住其他的j,取得最优的 q i ( z i ) q_i(z_i) qi(zi)
VBEM
我们把隐变量处理的更精细写
Z = ( z 1 , . . . , z n ) , Θ = ( π , μ , Λ ) \mathcal Z=(z_1,...,z_n),\mathcal {\Theta}=(\pi,\mu,\Lambda) Z=(z1,...,zn),Θ=(π,μ,Λ)
q ( Z ) = q z ( Z ) q θ ( Θ ) q(Z) = q_z(\mathcal Z)q_\theta(\Theta) q(Z)=qz(Z)qθ(Θ)
上述的变分推断可以分成两大部分:
VBE-step:
固定 q θ ( Θ ) q_\theta(\Theta) qθ(Θ),解最优 q z ( Z ) q_z(\mathcal Z) qz(Z)
q z ( Z ) = 1 C 1 e x p [ ∫ q θ ( Θ ) l o g ( p ( Z , Θ , X ) ) d Θ ] = 1 C 2 e x p [ ∫ q θ ( Θ ) l o g ( p ( Z , X ∣ Θ ) ) d Θ ] q_z(\mathcal Z)=\frac{1}{C_1}exp\left [{\int q_{\theta}(\Theta) log(p(\mathcal Z,\Theta,X))d\Theta}\right ] =\frac{1}{C_2}exp\left [{\int q_{\theta}(\Theta) log(p(\mathcal Z,X|\Theta))d\Theta}\right ] qz(Z)=C11exp[∫qθ(Θ)log(p(Z,Θ,X))dΘ]=C21exp[∫qθ(Θ)log(p(Z,X∣Θ))dΘ]
VBM-step
固定 q z ( Z ) q_z(\mathcal Z) qz(Z),解最优 q θ ( Θ ) q_\theta(\Theta) qθ(Θ)
q θ ( Θ ) = 1 C e x p [ ∫ q z ( Z ) l o g ( P ( Z , Θ , X ) ) d Z ] = 1 C p ( Θ ) e x p [ ∫ q z ( Z ) l o g ( p ( Z , X ∣ Θ ) ) d Z ] q_{\theta}(\Theta)=\frac{1}{C}exp\left [\int q_z(\mathcal Z) log(P(\mathcal Z,\Theta,X))d\mathcal Z\right] = \frac{1}{C}p(\Theta)exp\left[ \int q_z(\mathcal Z) log(p(\mathcal Z,X|\Theta))d\mathcal Z\right] qθ(Θ)=C1exp[∫qz(Z)log(P(Z,Θ,X))dZ]=C1p(Θ)exp[∫qz(Z)log(p(Z,X∣Θ))dZ]
需要注意到是这个结果不过是把上一张的结论给重新表达了一下,本质上没有什么不同
变分EM(VEM)
我们比较一下EM和变分推断,发现他们采取的解法都是一样的,固定其他参数,求其中一个参数的最优值。
不同的是EM算法中,最优的 Q ( z i ) Q(z_i) Q(zi)就是后验分布,变分推断中最优的 q ( Z ) q(Z) q(Z)是通过变分法求出来的,EM中关于 θ \theta θ就是一个函数,而变分推断中全部是泛函。
我们的变分推断中还有超参数,一般是假设不变的,但其实也可以在变分推断的过程中使用EM算法
记 F ( q , θ ) = E L O B θ ( q ) = ∫ q ( Z ) l o g p ( Z , X ; θ ) d Z − ∫ q ( Z ) l o g q ( Z ) d Z F(q,\theta) = ELOB_{\theta}(q)=\int q(Z)log\ p(Z,X;\theta)dZ-\int q(Z)log \ q(Z)dZ F(q,θ)=ELOBθ(q)=∫q(Z)log p(Z,X;θ)dZ−∫q(Z)log q(Z)dZ
VE-step:
固定超参数,计算最优的 q ( Z ) q(Z) q(Z)
q i ( z i ) = 1 C exp E j ≠ i [ l o g p ( Z , X ) ] q_i(z_i) =\frac{1}{C}\exp{E_{j\ne i}[log \ p(Z,X)]} qi(zi)=C1expEj̸=i[log p(Z,X)]
VM-step:
固定 q ( Z ) q(Z) q(Z),最优化超参数 θ \theta θ
θ ∗ = a r g m a x θ F ( q , θ ) \theta^* = argmax_\theta F(q,\theta) θ∗=argmaxθF(q,θ)
其实我们再给超参数一个先验,VEM算法和变分推断是完全一样的。
Gibss Sampling
注意到我们有两组隐变量 Z = ( z 1 , . . . , z n ) , Θ = ( π , μ , Λ ) \mathcal Z=(z_1,...,z_n),\mathcal {\Theta}=(\pi,\mu,\Lambda) Z=(z1,...,zn),Θ=(π,μ,Λ),
p ( X ) = p ( X ∣ Z , μ , Λ ) p ( Z ∣ π ) p ( π ) p ( μ , λ ) p(X)=p(X|\mathcal Z,\mu,\Lambda)p(\mathcal Z|\pi)p(\pi)p(\mu,\lambda) p(X)=p(X∣Z,μ,Λ)p(Z∣π)p(π)p(μ,λ)
我们想求的是 p ( π , μ , λ ∣ X ) p(\pi,\mu,\lambda|X) p(π,μ,λ∣X)
p ( π , μ , Λ ∣ X ) = ∫ Z p ( π , μ , Λ , Z ∣ X ) d Z = ∫ p ( π ∣ Z ) p ( μ , Λ ∣ Z , X ) p ( Z ∣ X ) d Z p(\pi,\mu,\Lambda|X)=\int_{\mathcal Z}p(\pi,\mu,\Lambda, \mathcal Z|X)d\mathcal Z\\ =\int p(\pi|\mathcal Z)p(\mu,\Lambda|\mathcal Z,X)p(\mathcal Z|X)d\mathcal Z p(π,μ,Λ∣X)=∫Zp(π,μ,Λ,Z∣X)dZ=∫p(π∣Z)p(μ,Λ∣Z,X)p(Z∣X)dZ
我们只要知道P(Z|X),就可以将这个积分算出来
很遗憾,我们没有办法知道。
但是如果我们能够采样出P(Z|X) 的样本,就可以使用蒙特卡洛模拟的方法将这个积分算出来。想要对这个分布采样,我们使用Gibbs 采样,Gibbs采样只需要知道
p ( z i ∣ z − i , X ) for any i p(z_i|z_{-i},X) \text{\ for any i} p(zi∣z−i,X) for any i
而
p ( z i ∣ z − i , X ) = p ( z i , x i ∣ z − i , x − i ) p ( x i ∣ z − i , x − i ) p(z_i|z_{-i},X)=\frac{p(z_i,x_i|z_{-i},x_{-i})}{p(x_i|z_{-i},x_{-i})} p(zi∣z−i,X)=p(xi∣z−i,x−i)p(zi,xi∣z−i,x−i)
分母只是一个常数,只关注分子
p ( z i , x i ∣ z − i , x − i ) = p ( x i ∣ z i , x − i ) p ( z i ∣ z − i ) = ∫ ∫ p ( x i , μ , Λ ∣ z i ) d μ d Λ ∫ p ( z i , π ∣ z − i ) d π = ∫ ∫ p ( x i ∣ z i , μ , Λ ) p ( μ , Λ ) d μ d Λ ∫ p ( z i ∣ π ) p ( π ∣ z − i ) d π p(z_i,x_i|z_{-i},x_{-i}) =p(x_i|z_i,x_{-i})p(z_i|z_{-i})\\ =\int\int p(x_i,\mu,\Lambda|z_i)d\mu d\Lambda\int p(z_i,\pi|z_{-i})d\pi\\ =\int\int p(x_i|z_i,\mu,\Lambda)p(\mu,\Lambda)d\mu d\Lambda\int p(z_i|\pi)p(\pi|z_{-i})d\pi\\ p(zi,xi∣z−i,x−i)=p(xi∣zi,x−i)p(zi∣z−i)=∫∫p(xi,μ,Λ∣zi)dμdΛ∫p(zi,π∣z−i)dπ=∫∫p(xi∣zi,μ,Λ)p(μ,Λ)dμdΛ∫p(zi∣π)p(π∣z−i)dπ
由于我们采用了共轭的先验,所以上述积分都是可以计算的
前者是个t分布(Gelman et al. [1995] pg. 88)
后者是个多项分布
得到了所有的条件概率后,就可以用Gibbs 采样获得符合分布样本,然后就可以计算出 p ( π , μ , Λ ∣ X ) p(\pi,\mu,\Lambda|X) p(π,μ,Λ∣X)
VB 与Gibbs的联系
要求 p ( Z ∣ X ) p(Z|X) p(Z∣X)
VB的思想是,用 q ( Z ) = ∏ i p i ( z i ) q(Z) = \prod_ip_i(z_i) q(Z)=∏ipi(zi)来近似。
每次迭代,用变分法求出最优的 q i ( z i ) q_i(z_i) qi(zi)
当迭代轮数到一定数量后,就得到了最优的 q ( Z ) q(Z) q(Z)
Gibss Sampling的思想是
先求 p ( z i ∣ z − i , X ) p(z_i|z_{-i},X) p(zi∣z−i,X)
每次迭代,从上述概率中采样出一个样本出来
当迭代轮数到一个数量后,就采样出了 p ( Z ∣ X ) p(Z|X) p(Z∣X),再用MC的思想进行后续处理。
VB在后验概率部分使用了近似,在得到最优结果时使用的是精确结果
Gibbs Sampling 在后验概率部分使用精确结果,在最后应用时,使用蒙特卡洛的近似
VB每轮迭代,得到的是一个近似的后验分布
Gibbs每轮迭代,是根据准确的后验分布得到一个样本
Ref
https://www-users.cs.york.ac.uk/adrian/Papers/Journals/TSMC-B06.pdf
https://www.doc.ic.ac.uk/~dfg/ProbabilisticInference/IDAPISlides17_18.pdf
https://chrischoy.github.io/research/Expectation-Maximization-and-Variational-Inference/
http://www.robots.ox.ac.uk/~fwood/teaching/C19_hilary_2013_2014/gmm.pdf
https://cse.buffalo.edu/faculty/mbeal/papers/beal03.pdf