主题模型LDA理解与应用
本文主要用于理解主题模型LDA(Latent Dirichlet Allocation)其背后的数学原理及其推导过程。本菇力求用简单的推理来论证LDA背后复杂的数学知识,苦于自身数学基础不够,因此文中还是大量引用了各方大神的数学推导细节,既是为了方便自己以后回顾,也方便读者追本溯源,当然喜欢直接看应用的读者可直接翻到第二章~
基本目录如下:
-
LDA的原理
1.1 先导数学知识准备
1.2 文本模型 - Unigram Model
1.3 主题模型 - PLSA Model
1.4 主题模型 - LDA Model -
LDA的应用与扩展
2.1 LDA的Python实现
2.2 LDA模型中的主题个数
------------------第一菇 - LDA的原理------------------
1.1 先导数学知识准备
LDA之所以很难懂,跟其涉及大量的数学统计知识有关,因此,为了更好的理解LDA,还是先铺垫一些数学知识。本段力求少摆公式,用更通俗的话来阐述其背后的数学思想~
1.1.1 Gamma函数
认真学过高数的应该都对这个函数有印象,其基本公式如下:
再贴一张Gamma函数图,方便大家对其有一个概览性的认识:
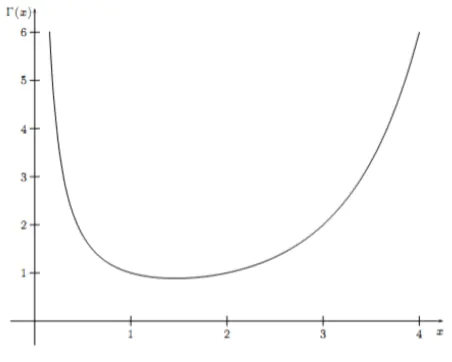
gamma函数
该函数有一个很好的递归性质(利用分步积分法可证)如下:
当然该函数还有更重要的一点,即其可以表述为阶乘在实数集上的延拓:
(PS.至于为何不定义一个函数满足,大家可以移步LDA数学八卦第一章,看完还蛮有趣的,顺便感叹一下伟大数学家们对完美数学公式的追求~)
1.1.2 二项分布
高中学概率论的时候,还记得抛硬币的例子么?每一次抛硬币都会有俩个结果,正面OR背面,那么抛一次硬币就满足伯努利分布(又叫0-1分布),是一个离散型的随机分布。二项分布无非就是重复N次的伯努利实验,其概率密度函数可以表示为:
其中
看到C(n,k)大部分人应该都能想起这个在高中就学过的式子的意思,最简单的排列组合,从n个事件中挑出k个事件的组合方式,因此上面的式子应该不难理解了。
1.1.3 多项分布
高中学习概率论的时候,我们除了仍硬币还仍什么?还会仍骰子哈哈~但这个时候仍一次骰子就不满足伯努利分布了,因为仍一次骰子会有6或更多种结果。因此,多项分布就是二项分布扩展到高维的情况,其概率密度函数可以表示为:
想细究该公式怎么来的,可以先移步这篇博文多项式分布的理解概率公式的理解,本质思想跟二项分布几乎没差,只不过涉及到了一些多项式定理。
1.1.4 Beta分布
通俗理解,当我们不知道一个概率是什么,但又有一些合理的猜测时,Beta分布能很好的作为一个表示概率的概率分布。举个例子,我们要统计预测一下窝火琦琦新赛季的三分投篮命中率,假如琦琦上赛季投了一个三分,命中一个,则按照我们熟悉的思路,我们可以预测琦琦新赛季命中率100%(想想美滋滋)!但仔细一想不对啊,就算是顶级的三分手(比如汤神)也就40%超一点,难道我大琦琦比汤神还牛了?显然这里大家的思考就会出现分歧,于是就引申出了一个统计学知识点,或者说是俩个学派 - 频率学派和贝叶斯学派!这俩个学派的思路差异体现在:
- 频率学派:他们把需要推断的参数(本例就是琦琦的三分命中率)看做是固定的未知常数,即虽然这个概率是未知的,但却是确定的一个值,同时,样本是随机的,因此频率学派重点研究样本空间,大部分的概率计算都是针对样本的分布!
- 贝叶斯学派:他们与频率学派认知刚好相反,他们认为参数都不是固定值,而是服从一个概率分布,样本却是固定的,因此他们重点研究的是参数的分布。
因此,回到琦琦的例子上来,用传统频率学派的观点,那琦琦的命中率确实就是100%,而用贝叶斯学派的观点,首先琦琦的命中率有一个先验分布,而根据样本信息,我们可以对其进行更新,得到后验分布。而数学家们为二项分布选取的先验分布就是Beta分布!
Beta分布在概率论中指一组分布在区间的连续概率分布,其中参数为, ,概率密度函数为:
其中,
至于代表的物理意义,可以简单理解这俩一起控制着Beta分布的形状,贴一张图方便理解:

不同取值的Beta分布.png
当然如果这个时候新赛季已经开打,那我们又会多得到一点信息,比如琦琦在揭幕战怒投5三分,并且命中2个,错失3个,那这个时候,揭幕战中投出的5个三分,肯定能为我所用(样本信息为二项分布),用于更新我对琦琦一开始命中率预测的分布。而这个时候就要用到Beta分布另一个重要的性质了,即Beta-Binomial共轭,对琦琦的预测分布可更新为。
先讲明,“共轭分布” 援引wiki的定义即为:在贝叶斯统计中,如果后验分布与先验分布属于同类,则先验分布与后验分布被称为共轭分布,而先验分布被称为似然函数的共轭先验【1】。参照定义,Beta-Binomial 共轭意味着,如果我们为二项分布的参数p选取的先验分布是Beta分布,那么以p为参数的二项分布用贝叶斯估计得到的后验分布仍然服从Beta分布,那么Beta分布就是二项分布的共轭先验分布,用数学公式表述就是:
这种形式不变的好处是,我们能够在先验分布中赋予参数很明确的物理意义,这个物理意义可以延续到后续分布中进行解释,同时从先验变换到后验过程中从数据中补充的知识也容易有物理解释【2】。另外再多说一点,关于Beta分布的期望可推导表示为:
不知大家能否一眼看出这俩个参数的物理意义,实际上就是琦琦三分投篮时候,命中与未命中的次数!(居然与频率学派对P值的估计统一起来了~妙!)
1.1.5 Dirichlet分布
终于涉及到本文的主角,Dirichlet分布了~灵光的读者研究到这应该大致能猜到该分布是干嘛的了。类比于多项分布是二项分布的推广,Dirichlet分布也确实是Beta分布的推广,其概率密度函数为:
其中
且类比于Beta分布,Dirichlet也是多项分布的共轭先验分布:
相对应于Beta的期望,Dirichlet分布的期望也可以如下:(其物理意义也就是每个参数的估计值是其对应事件的先验的参数(也叫伪计数)和数据中的计数的和在整体计数中的比例):
对以上俩个分布的推导过程感兴趣的可以移步LDA数学八卦。
1.2 文本模型 - Unigram Model
假设一篇文档由若干个词语构成,可以不考虑顺序,就你像看这句话的时候也没现发他序顺乱了~因此我们不妨就把一篇文章看作是一些词的集合。那么最简单的文本生成模型就是,确定文本的长度为N,然后选出N个词来。选词的过程与我们仍骰子一模一样,无非就是这个骰子的面比较多,但其仍然服从多项分布。这个简单的文本生成模型就叫做Unigram Model。当然少不了贝叶斯估计,每一个面朝上的概率也会有一个先验分布为Dirichlet分布,表示为,而我们也可以根据样本信息来估计后验分布,其概率图模型可以表示为:

Unigram Model 概率图模型
该记图方式为plate notation,有兴趣的可以了解一下。此时该文本的生成概率就等于:
我们推导可以计算得到:
1.3 主题模型 - PLSA Model
上面讲的文本生成模型足够简单,但是对文本的表达能力还是不够,且不太符合我们日常的写作习惯!试想,我们写一篇文章的时候,肯定都会事先拟定一个主题,然后再从这个主题中去寻找相应的词汇,因此这么来看,只扔一个有N面的骰子似乎还不够,我们似乎应该提前再准备m个不同类型的骰子,作为我们的主题,然后确定了主题以后,再选中那个骰子,来决定词汇。由此,便引申出了我们的主题模型!别急,还没轮到LDA登场,我们先介绍一个简单的PLSA模型!
简单来说PLSA是用一个生成模型(生成模型与判别式模型的区别大家还是要懂的)来建模文章的生成过程!它有几个前提假设【3】如下:
- 一篇文章可以由多个主题构成
- 每一个主题由一组词的概率分布来表示
- 一篇文章中的每一个具体的词都来自于一个固定的主题
其概率图模型【4】可以表示为:
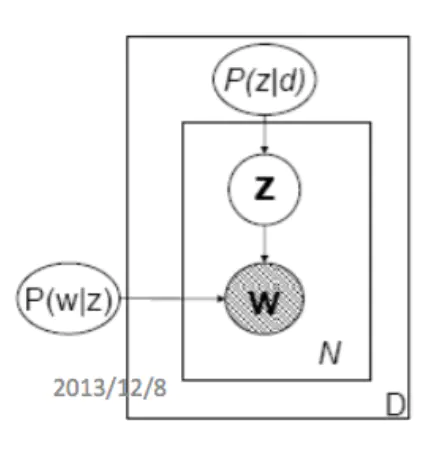
PLSA Model 概率图模型
用自己的话翻译一下上述过程就是:
- 按照概率选中一篇文档
- 从主题分布中按照概率选中一个主题
- 从词分布中按照概率选中一个词
则整个语料库中的文本生成概率可以用似然函数表示为:
其中表示单词在文档中出现的次数。
其对数似然函数可以写成:
其中主题分布和定义在主题上的词分布就是待估计的参数,一般会用EM算法(值得另开一篇来单独讲的机器学习基础算法)来求解。有兴趣考究推导细节的读者请移步July老师的博客
1.3 主题模型 - LDA Model
坚持看到这里的读者,其实内心应该对LDA也有了自己的猜想,看看PLSA漏了什么?没错,就是一个贝叶斯框架!如果我们给主题分布加一个Dirichlet分布,再给主题上的词分布再加一个Dirichlet分布,那就是LDA!因此实际上LDA就是PLSA的贝叶斯版本。我们直接来看模型图【4】:
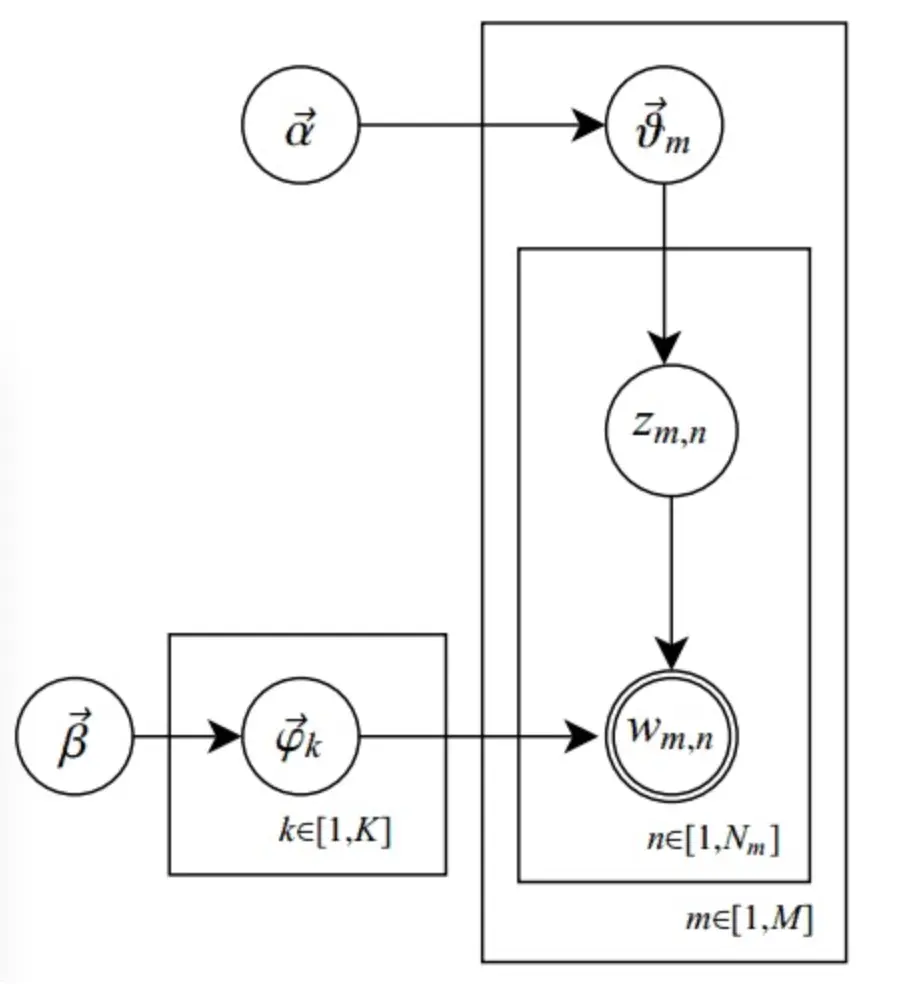
LDA Model 概率图模型
用自己的话翻译一下上述过程就是:
- 按照概率选中一篇文档
- 从Dirichlet分布中抽样生成文档的主题分布
- 从主题分布中抽取文档第j个词的主题
- 从Dirichlet分布中抽样生成主题对应的词分布
- 从词分布中抽样生成词
为了方便求解,我们通常会将上述过程顺序交换一下,即我们先生成完全部的主题,再由这些主题去生成完每一个词。这样,第一,二个过程的推导就可以用到Unigram Model的结论,即我们整个语料库下所有词的主题编号的生成概率为:
对于词的生成过程(主题编号的选择并不会改变K个主题下的词分布),即可表示为:
因此,LDA模型的语料库的生成概率可以表述为:
至此,整个LDA模型的文档生成过程介绍完了,而实际我们运用求解的时候,我们的任务也就是去估计隐含变量主题分布和词分布的值了。实际求解的时候,一般会采用Gibbis Sampleing (又是可以单独写一篇的MCMC采样的其中一种,详情可见我的另一篇文章)。这里简单介绍一下,就是首先随机给定每个单词的主题,然后在其他变量保持不变的情况下,根据转移概率抽样生成每个单词的新主题,反复迭代以后,收敛后的结果就是主题分布和词分布的期望。
写到这里,基本上整个LDA模型算是从最简单的二项分布到Dirichlet分布梳理明白了,对于不追求数学细节的读者来说,至少可以在实际运用中不像无头苍蝇一样当个“调包侠”,当然这些都还只是个入门基础,研究人员对LDA做了非常多的扩展应用(这里推荐一篇文章是专门讲当初三位大佬LDA论文的,看完也是收获颇多,推荐一波),而我们只有打好了扎实的基础,才能在实际应用中面对各种不同的变化得心应手!接下来,我就举几个实际的实战案例,让大家体验一把其实际的应用。
------------------第二菇 - LDA的应用与扩展------------------
2.1 LDA的Python实现
在实际的运用中,LDA可以直接从gensim调,主要的一些参数有如下几个:
- corpus:语料数据,需要包含单词id与词频
- num_topics:我们需要生成的主题个数(重点调节)
- id2word:是一种id到单词的映射(gensim也有包生成)
- passes:遍历文本的次数,遍历越多越准备
- alpha:主题分布的先验
- eta:词分布的先验
接下来,我们实战一把,直接用其官方的示例
from gensim.test.utils import common_texts
from gensim.corpora.dictionary import Dictionary
# Create a corpus from a list of texts
common_dictionary = Dictionary(common_texts)
common_corpus = [common_dictionary.doc2bow(text) for text in common_texts]
# Train the model on the corpus.
lda = LdaModel(common_corpus, num_topics=10)
一步步拆解来看,首先common_texts是list形式,里面的每一个元素都可以认为是一篇文档也是list结构:
>>> print type(common_texts)
>>> common_texts[0]
['human', 'interface', 'computer']
第二步,doc2bow这个方法用于将文本转化为词袋形式,看一个官方的示例大家应该就能明白了,
>>> from gensim.corpora import Dictionary
>>> dct = Dictionary(["máma mele maso".split(), "ema má máma".split()])
>>> dct.doc2bow(["this", "is", "máma"])
[(2, 1)]
>>> dct.doc2bow(["this", "is", "máma"], return_missing=True)
([(2, 1)], {u'this': 1, u'is': 1})
初始化的时候对每一个词都会生成一个id,新的文本进去的时候,返回该文本每一个词的id,和对应的频数,对于那些不存在原词典的,可以控制是否返回。此时生成的corpus就相当于是LDA训练模型的输入了,让我们检查一下:
>>>common_corpus[0]
[(0, 1), (1, 1), (2, 1)]
# human单词的id为0,且在第一个文档中只出现了一次
最后一步,我们只需调用LDA模型即可,这里指定了10个主题。
from gensim.models import LdaModel
lda = LdaModel(common_corpus, num_topics=10)
让我们检查一下结果(还有很多种方法大家可以看文档),比如我们想看第一个主题由哪些单词构成:
>>>lda.print_topic(1, topn=2)
'0.500*"9" + 0.045*"10"
可以看出第一个模型的词分布,9号10号占比较大(这里topn控制了输出的单词个数,对应的单词可以通过之前生成dict找出)
我们还可以对刚才生成的lda模型用新语料去进行更新,
# 能更新全部参数
lda.update(other_corpus)
#还能单独更新主题分布, 输入为之前的参数,其中rho指学习率
lda.update_alpha(gammat, rho)
#还能单独更新词分布
lda.update_eta(lambdat, rho)
大家可以根据自己的实际业务需求,来具体查验所需函数,这里就不一一展开了,官方文档上也写的比较细,总的来说,感谢大神们把轮子都造好了,我们只要会用即可,最好还能参透一点其背后的原理。
2.2 LDA模型中的主题个数
这里扩展开来谈一点,我们如何确定LDA模型中的主题个数,因为这也是我们调参的重点,该参数选取的恰当,那我们模型的效果往往会变好。首先还是熟悉的套路,交叉验证,28,37分看数据量,而我们的评估指标,我翻了一圈,大家都是用的困惑度(perplexity),其定义为:
其中为文档的总数,为文档中单词所组成的词袋向量,为模型所预测的文档的生成概率,为文档中单词的总数。简单理解一下就是,对于一篇文章,我们的模型有多不确定它是属于哪一个主题的。很自然,主题越多,肯定困惑度越小,但是不要忘了,计算性能也扛不住啊,因此,一般也是会在合理的主题范围内去挑选一个最佳的主题个数,比如画topic_number-perplexity曲线(跟K-means)去找最佳的K一样的理念吧。还有其他大佬,融入了分层狄利克雷过程(HDP),构成一种非参数主题模型,好处就是不需要预先指定个数,模型可以随着文档的变化而自动的对主题个数进行调整(复杂程度有点高,本菇还未深入涉足这一块)。这里还要再提醒一点,也是看知乎上小伙伴上提醒的,千万不要用gensim中的log_perplexity()计算的perplexity指标来比较topic数量的好坏!因为这个函数没有对主题数目做归一化,因此不同的topic数目不能直接比较!【5】(然后发现一票人最后说,都是自己拍的一个主题个数哈哈哈)
至此运用这一块也算是简单的,大家还是需要根据自己的业务再做调整~毕竟也是一门实验学科,大家多做实验,多试验试验自然经验就有了。
简单总结一下本文,先是介绍了一些LDA背后的统计分布,重点有Beta分布,及Beta-Binomial 共轭,然后引出了Dirichlet分布,最后引出了LDA模型,虽然省略了一些数学推导细节,但基本不影响读者理解。最后还附上了一些Python的实战应用,并重点讨论了一下如何选取合适的主题数目。希望大家读完本文后对机器学习主题模型这一块有全新的认识。有说的不对的地方也请大家指出,多多交流,大家一起进步~?
参考文献:
【1】https://zh.wikipedia.org/wiki/%E5%85%B1%E8%BD%AD%E5%85%88%E9%AA%8C
【2】https://zhuanlan.zhihu.com/p/31470216
【3】http://aroslin.com/2017/11/07/LDA-From-Zero/
【4】https://clyyuanzi.gitbooks.io/julymlnotes/content/lda.html
【5】https://www.zhihu.com/question/32286630
原文:https://www.jianshu.com/p/74ec7d5f6821
135、怎么确定LDA的topic个数?
pLSA建模与求参
-
pLSA
LSA(隐性语义分析)的目的是要从文本中发现隐含的语义维度-即“Topic”或者“Concept”。尽管基于SVD的LSA取得了一定的成功,但是其缺乏严谨的数理统计基础,而且SVD分解非常耗时。Hofmann在SIGIR'99上提出了基于概率统计的PLSA模型,并且用EM算法学习模型参数。PLSA的概率图模型如下
image.png
pLSA是一种词袋方法:

image.png
-
几个定义:

image.png
-
pLSA建模目标:根据文档反推其主题分布
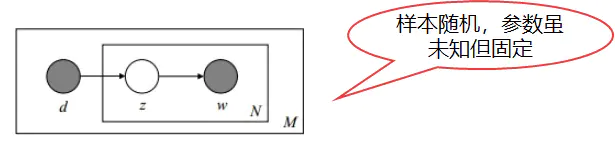
image.png
图中被涂色的d、w表示可观测变量,未被涂色的z表示未知的隐变量,N表示一篇文档中总共N个单词,M表示M篇文档。
已知:
image.png
问题: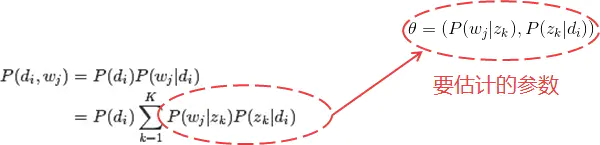
image.png
-
pLSA求参数:EM算法
基本思想是:
image.png

image.png
关键:找到?(?)的一个下界,然后maxmize这个下界,逼近求解的似然函数?(?)。

image.png
-
pLSA求参数:两未知参数矩阵化

image.png
-
pLSA求参数:两未知参数

image.png
-
pLSA求参数:E-step
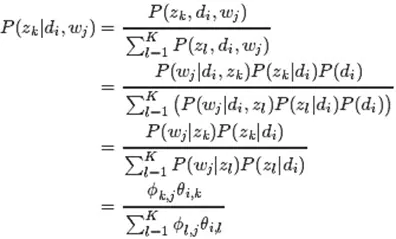
image.png
假定参数已知,计算此时引变量的后验概率。
-
pLSA求参数:M-step
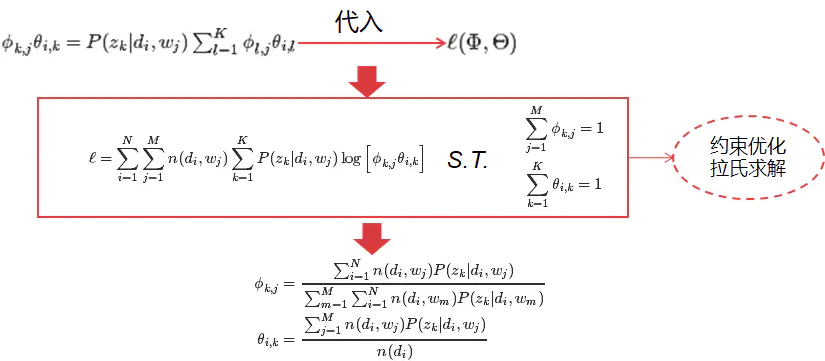
image.png
带入隐变量的后验概率,最大化样本分布的对数似然函数,求解相应的参数。
原文:https://www.jianshu.com/p/5de4d11bb045