内存中inode与磁盘中inode
在容易引起混淆的地方我将把把内存中的inode结构称为VFS inode,而文件系统以EXT2为代表,把Ext2 inode作为磁盘上的inode代表。
首先需要分别对内存中的inode与磁盘上的inode做一下简单的描述:
<内存中的inode结构:>
VFS inode包含文件访问权限、属主、组、大小、生成时间、访问时间、最后修改时间等信息。它是linux管理文件系统的最基本单位,也是文件系统连接任何子目录、文件的桥梁。inode结构中的静态信息取自物理设备上的文件系统,由文件系统指定的函数填写,它只存在于内存中,可以通过inode缓存访问。虽然每个文件都有相应的inode结点,但是只有在需要的时候系统才会在内存中为其建立相应的inode数据结构,建立的inode结构将形成一个链表,我们可以通过遍历这个链表去得到我们需要的文件结点,VFS也为已分配的inode构造缓存和hash table,以提高系统性能。inode结构中的struct inode_operations *iop为我们提供了一个inode操作列表,通过这个列表提供的函数我们可以对VFS inode结点进行各种操作。每个inode结构都有一个i结点号i_ino,在同一个文件系统中每个i结点号是唯一的。
<磁盘上的inode:>
EXT2通过使用inode来定义文件系统的结构以及描述系统中每个文件的管理信息,每个文件都有一个inode且只有一个,即使文件中没有数据,其索引结点也是存在的。每个文件用一个单独的Ext2 inode结构来描述,而且每一个inode都有唯一的标志号。Ext2 inode为内存中的inode结构提供了文件的基本信息,随着内存中inode结构的变化,系统也将更新Ext2 inode中相应的内容。Ext2 inode对应的是Ext2_inode结构。
从上面的描述,我们可以对内存中inode与磁盘中inode做出比较:
位置:VFS inode结构位于内存中,而Ext2_inode位于磁盘。
生存期:VFS inode在需要时才会被建立,如果系统断电,此结构也随之消失。 而Ext2_inode的存在与系统是否上电无关,而且无论文件是否包含数据,Ext2_inode都是存在的。
唯一性:两者在自己的作用域中都是唯一的。
关系:VFS inode是Ext2 inode的抽象、映射与扩充,而后者是前者的静态信息部分,也是对前者的具体化、实例化和持久化。
操作:对VFS inode的操作具有通用性,对文件系统inode的操作则是文件系统相关的,依赖于特定的实现。
组织管理:系统通过VFS inode链表来对其进行组织,并且为了提高访问效率相应地构造了inode构造缓存和hash table。
Ext2 inode的信息位于EXT2文件系统的划分的块组中,在每个块组中包含相应的inode位图、inode表指定具体的inode信息,每个inode对应Ext2_inode结构。
上面是从原理上对内存中inode与磁盘中inode进行比较,实际上在代码上也体现出它们的不同。在下面我把在内核中两者对应的结构代码贴出来,虽然长了一些,但是对进一步的比较还是很有好处。
.....
....
从结构的定义中可以看出来inode(VFS inode)与ext2_inode的差别是很大的,怎么说呢,
除了相同的都是不同。它们都包含动态信息和静态信息,通过union指定的内容那一定
是动态的了。inode结构中的union u实际上反映了VFS支持的文件系统。
可以看出inode结构与ext2_inode结构有些内容是相似的,如inode定义的
深入理解磁盘文件系统之inode(转)
一、inode是什么
理解inode,要从文件储存说起。
文件储存在硬盘上,硬盘的最小存储单位叫做"扇区"(Sector)。每个扇区储存512字节(相当于0.5KB)。
操作系统读取硬盘的时候,不会一个个扇区地读取,这样效率太低,而是一次性连续读取多个扇区,即一次性读取一个"块"(block)。这种由多个扇区组成的"块",是文件存取的最小单位。"块"的大小,最常见的是4KB,即连续八个sector组成一个block。
文件数据都储存在"块"中,那么很显然,我们还必须找到一个地方储存文件的元信息,比如文件的创建者、文件的创建日期、文件的大小等等。这种储存文件元信息的区域就叫做inode,中文译名为"索引节点"。
每一个文件都有对应的inode,里面包含了与该文件有关的一些信息。
二、inode内容
inode包含文件的元信息,具体来说有以下内容:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 |
|
可以用stat命令,查看某个文件的inode信息:
stat example.txt

总之,除了文件名以外的所有文件信息,都存在inode之中。至于为什么没有文件名,下文会有详细解释。
三、inode结构
了解一下文件系统如何存取文件的:
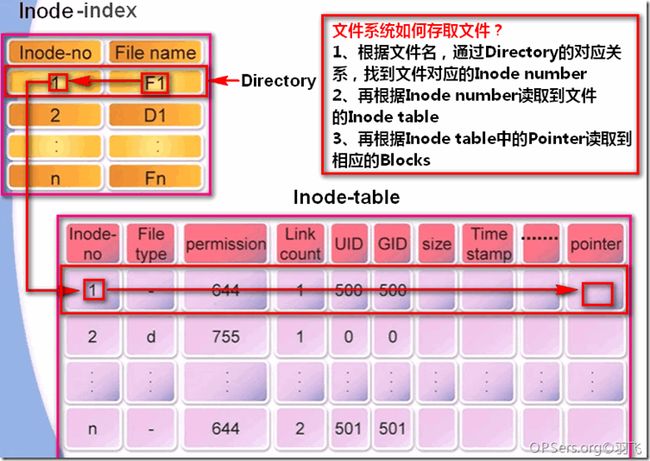
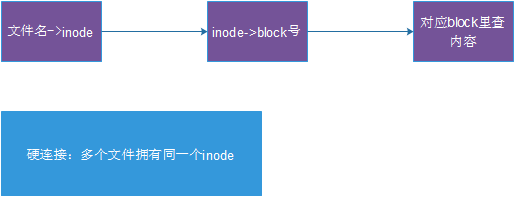
1、根据文件名,通过Directory里的对应关系,找到文件对应的Inode number
2、再根据Inode number读取到文件的Inode table
3、再根据Inode table中的Pointer读取到相应的Blocks
这里有一个重要的内容,就是Directory,他不是我们通常说的目录,而是一个列表,记录了一个文件/目录名称对应的Inode number。如下图:

四、inode大小
inode也会消耗硬盘空间,所以硬盘格式化的时候,操作系统自动将硬盘分成两个区域。一个是数据区,存放文件数据;另一个是inode区(inode table),存放inode所包含的信息。
每个inode节点的大小,一般是128字节或256字节。inode节点的总数,在格式化时就给定,一般是每1KB或每2KB就设置一个inode。假定在一块1GB的硬盘中,每个inode节点的大小为128字节,每1KB就设置一个inode,那么inode table的大小就会达到128MB,占整块硬盘的12.8%。
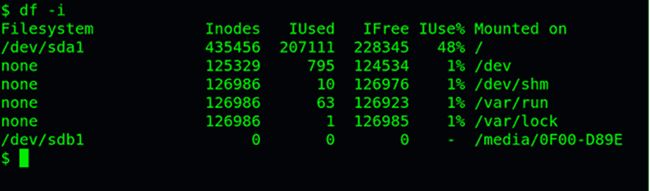
查看每个硬盘分区的inode总数和已经使用的数量,可以使用df命令。
df -i
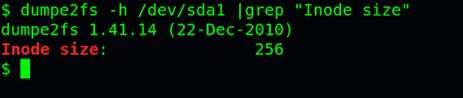
查看每个inode节点的大小,可以用如下命令:
sudo dumpe2fs -h /dev/hda | grep "Inode size"
由于每个文件都必须有一个inode,因此有可能发生inode已经用光,但是硬盘还未存满的情况。这时,就无法在硬盘上创建新文件。
五、inode号码
每个inode都有一个号码,操作系统用inode号码来识别不同的文件。
这里值得重复一遍,Unix/Linux系统内部不使用文件名,而使用inode号码来识别文件。对于系统来说,文件名只是inode号码便于识别的别称或者绰号。
表面上,用户通过文件名,打开文件。实际上,系统内部这个过程分成三步:
首先,系统找到这个文件名对应的inode号码;其次,通过inode号码,获取inode信息;最后,根据inode信息,找到文件数据所在的block,读出数据。
使用ls -i命令,可以看到文件名对应的inode号码:
ls -i example.txt

六、目录文件
Unix/Linux系统中,目录(directory)也是一种文件。打开目录,实际上就是打开目录文件。
目录文件的结构非常简单,就是一系列目录项(dirent)的列表。每个目录项,由两部分组成:所包含文件的文件名,以及该文件名对应的inode号码。
ls命令只列出目录文件中的所有文件名:
ls /etc

ls -i命令列出整个目录文件,即文件名和inode号码:
ls -i /etc

如果要查看文件的详细信息,就必须根据inode号码,访问inode节点,读取信息。ls -l命令列出文件的详细信息。
ls -l /etc
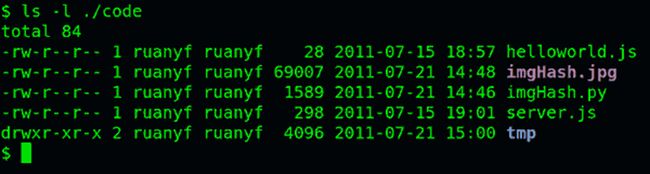
理解了上面这些知识,就能理解目录的权限。目录文件的读权限(r)和写权限(w),都是针对目录文件本身。由于目录文件内只有文件名和inode号码,所以如果只有读权限,只能获取文件名,无法获取其他信息,因为其他信息都储存在inode节点中,而读取inode节点内的信息需要目录文件的执行权限(x)。
七、硬链接
一般情况下,文件名和inode号码是"一一对应"关系,每个inode号码对应一个文件名。但是,Unix/Linux系统允许,多个文件名指向同一个inode号码。
这意味着,可以用不同的文件名访问同样的内容;对文件内容进行修改,会影响到所有文件名;但是,删除一个文件名,不影响另一个文件名的访问。这种情况就被称为"硬链接"(hard link)。
ln命令可以创建硬链接:
ln 源文件目标文件
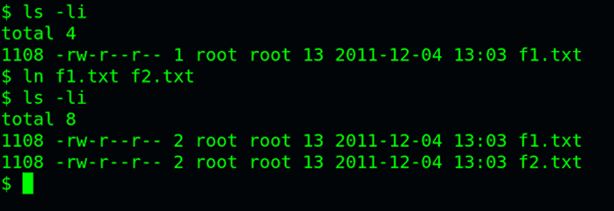
运行上面这条命令以后,源文件与目标文件的inode号码相同,都指向同一个inode。inode信息中有一项叫做"链接数",记录指向该inode的文件名总数,这时就会增加1。
反过来,删除一个文件名,就会使得inode节点中的"链接数"减1。当这个值减到0,表明没有文件名指向这个inode,系统就会回收这个inode号码,以及其所对应block区域。
这里顺便说一下目录文件的"链接数"。创建目录时,默认会生成两个目录项:"."和".."。前者的inode号码就是当前目录的inode号码,等同于当前目录的"硬链接";后者的inode号码就是当前目录的父目录的inode号码,等同于父目录的"硬链接"。所以,任何一个目录的"硬链接"总数,总是等于2加上它的子目录总数(含隐藏目录)。
八、软链接
除了硬链接以外,还有一种特殊情况。
文件A和文件B的inode号码虽然不一样,但是文件A的内容是文件B的路径。读取文件A时,系统会自动将访问者导向文件B。因此,无论打开哪一个文件,最终读取的都是文件B。这时,文件A就称为文件B的"软链接"(soft link)或者"符号链接(symbolic link)。
这意味着,文件A依赖于文件B而存在,如果删除了文件B,打开文件A就会报错:"No such file or directory"。这是软链接与硬链接最大的不同:文件A指向文件B的文件名,而不是文件B的inode号码,文件B的inode"链接数"不会因此发生变化。
ln -s命令可以创建软链接。
ln -s 源文文件或目录目标文件或目录

九、inode的特殊作用
由于inode号码与文件名分离,这种机制导致了一些Unix/Linux系统特有的现象:
(1) 有时,文件名包含特殊字符,无法正常删除。这时,直接删除inode节点,就能起到删除文件的作用。
(2) 移动文件或重命名文件,只是改变文件名,不影响inode号码。
(3) 打开一个文件以后,系统就以inode号码来识别这个文件,不再考虑文件名。因此,通常来说,系统无法从inode号码得知文件名。
第3点使得软件更新变得简单,可以在不关闭软件的情况下进行更新,不需要重启。因为系统通过inode号码,识别运行中的文件,不通过文件名。更新的时候,新版文件以同样的文件名,生成一个新的inode,不会影响到运行中的文件。等到下一次运行这个软件的时候,文件名就自动指向新版文件,旧版文件的inode则被回收。
通过inode查找到data block
较新的操作系统的文件除了文件的实际内容外,通常含有非常多的属性,例如Linux操作系统的文件权限(rwx)与文件属性(拥有者、群组、时间参数等)。 文件系统通常会将这两部份的资料分别存放在不同的区块,权限与属性放置到inode中,至于实际资料则放置到data block区块中。另外,还有一个超级区块(superblock)会记录整个档案系统的整体信息,包括inode与block的总量、使用量、剩余量等。每个inode 与block 都有编号,至于这三个结构体的意义可以简略说明如下:
- superblock:记录此filesystem 的整体信息,包括inode/block的总量、使用量、剩余量, 以及档案系统的格式与相关信息等;
- inode:记录文件的属性,一个文件占用一个inode,同时记录此文件信息所在的block 号码;(表示位数限制,多级查找)
- block:实际记录档案的内容,若档案太大时,会占用多个block 。
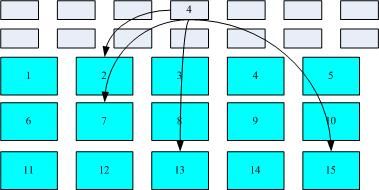
由于每个inode 与block 都有编号,而每个文件都会占用一个inode ,inode 内则有文件的block 号码。因此,我们可以知道的是,如果能够找到文件的inode 的话,那么自然就会知道这个文件所放置内容的block 号码, 当然也就能够读出该文件的实际内容了。这是个比较有效率的作法,因为如此一来我们的磁盘就能够在短时间内读取出全部的内容, 读写的效能比较好啰。
我们将inode 与block 区块用图解来说明一下,如下图所示,文件系统先格式化出inode 与block 的区块,假设某一个文件的属性与权限信息是放置到inode 4 号(下图较小方格内),而这个inode 记录了文件数据的实际放置点为2, 7, 13, 15 这四个block 号码,此时我们的操作系统就能够据此来排列磁盘的读取顺序,可以一口气将四个block 内容读出来!那么资料的读取就如同下图中的箭头所指定的模样了。
这种资料存取的方法我们称为索引式文件系统(indexed allocation)。那有没有其他的惯用文件系统可以比较一下啊?有的,那就是我们惯用的U盘(快闪记忆体),U盘使用的档案系统一般为FAT格式。FAT这种格式的档案系统并没有inode存在,所以FAT没有办法将这个档案的所有block在一开始就读取出来。每个block号码都记录在前一个block当中,他的读取方式有点像底下这样:
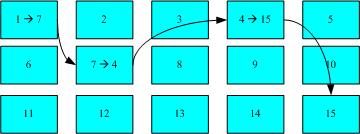
上图中我们假设文件的资料依序写入1->7->4->15号这四个block 号码中, 但这个档案系统没有办法一口气就知道四个block 的号码,他得要一个一个的将block 读出后,才会知道下一个block 在何处。如果同一个档案资料写入的block 分散的太过厉害时,则我们的磁盘读取头将无法在磁盘转一圈就读到所有的资料, 因此磁盘就会多转好几圈才能完整的读取到这个档案的内容!
常常会听到所谓的『碎片整理』吧? 需要碎片整理的原因就是文件写入的block太过于离散了,此时档案读取的效能将会变的很差所致。 这个时候可以透过碎片整理将同一个文件所属的blocks汇整在一起,这样资料的读取会比较容易啊! 想当然尔,FAT的档案系统需要三不五时的碎片整理一下,那么Ext2是否需要磁盘重整呢?
由于Ext2 是索引式文件系统,基本上不太需要常常进行碎片整理的。但是如果档案系统使用太久, 常常删除/编辑/新增档案时,那么还是可能会造成档案资料太过于离散的问题,此时或许会需要进行重整一下的。
Linux 的EXT2 文件系统(inode)
inode的内容在记录文件的权限与相关属性,至于block区块则是在记录文件的实际内容。而且文件系统一开始就将inode与block规划好了(hy:如mkfs.ext4 /dev/mmcblk0p2 -i 4096),除非重新格式化(或者利用resize2fs等指令变更文件系统大小),否则inode与block固定后就不再变动。但是如果仔细考虑一下,如果我的文件系统高达数百GB时,那么将所有的inode与block通通放置在一起将是很不智的决定,因为inode与block的数量太庞大,不容易管理。
为此,因此Ext2 文件系统在格式化的时候基本上是区分为多个区块群组(block group) 的,每个区块群组都有独立的 inode/block/superblock 系统。感觉上就好像我们在当兵时,一个营里面有分成数个连,每个连有自己的联络系统, 但最终都向营部回报连上最正确的信息一般!这样分成一群群的比较好管理啦!整个来说,Ext2 格式化后有点像底下这样:
 HY:左图表示磁盘-->inode table 在磁盘上存储
HY:左图表示磁盘-->inode table 在磁盘上存储
在整体的规划当中,文件系统最前面有一个开机磁区(boot sector),这个开机磁区可以安装开机管理程式,这是个非常重要的设计,因为如此一来我们就能够将不同的开机管理程式安装到个别的文件系统最前端,而不用覆盖整颗磁盘唯一的MBR,这样也才能够制作出多重开机的环境啊!至于每一个区块群组(block group)的六个主要内容说明如后:
data block
data block是用来放置文件内容的地方,在Ext2档案系统中所支持的block大小有1K, 2K及4K三种而已。在格式化时block的大小就固定了,且每个block都有编号,以方便inode的记录啦。不过要注意的是,由于block大小的差异,会导致该档案系统能够支持的最大磁盘容量与最大单一档案容量并不相同。因为block大小而产生的Ext2档案系统限制如下:
| Block 大小 | 1KB | 2KB | 4KB |
|---|---|---|---|
| 最大单一文件限制 | 16GB | 256GB | 2TB |
| 最大文件系统总容量 | 2TB | 8TB | 16TB |
除此之外Ext2 档案系统的block 还有什么限制呢?有的!基本限制如下:
- 原则上,block 的大小与数量在格式化完就不能够再改变了(除非重新格式化);
- 每个block 内最多只能够放置一个档案的资料;
- 承上,如果档案大于block 的大小,则一个档案会占用多个block 数量;
- 承上,若档案小于block ,则该block 的剩余容量就不能够再被使用了(磁盘空间会浪费)。
inode table
基本上,inode记录的文件资料至少有底下这些:
- 该文件的存取模式(read/write/excute);
- 该文件的拥有者与群组(owner/group);
- 该文件的容量;
- 该文件建立或状态改变的时间(ctime);
- 最近一次的读取时间(atime);
- 最近修改的时间(mtime);
- 定义文件特性的旗标(flag),如SetUID…;
- 该文件真正内容的指向(pointer);
inode 的数量与大小也是在格式化时就已经固定了,除此之外inode 还有些什么特色呢?
- 每个inode 大小均固定为128 bytes (新的ext4 与xfs 可设定到256 bytes);
- 每个档案都仅会占用一个inode 而已;
- 承上,因此文件系统能够建立的文件数量与inode 的数量有关;
- 系统读取文件时需要先找到inode,并分析inode 所记录的权限与使用者是否符合,若符合才能够开始实际读取 block 的内容。
我们粗略来分析一下EXT2 的inode / block 与文件大小的关系好了。inode 要记录的资料非常多,但偏偏又只有128bytes 而已, 而inode 记录一个block 号码要花掉4byte ,假设我一个档案有400MB 且每个block 为4K 时, 那么至少也要十万笔block 号码的记录呢!inode 哪有这么多可记录的信息?为此我们的系统很聪明的将inode 记录block 号码的区域定义为12个直接,一个间接, 一个双间接与一个三间接记录区。这是啥?我们将inode 的结构画一下好了。 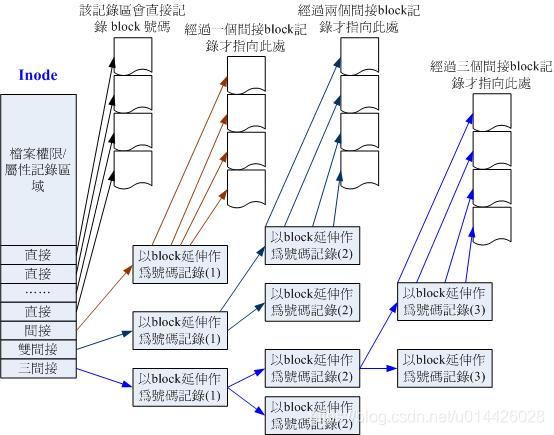
这样子inode 能够指定多少个block 呢?我们以较小的1K block 来说明好了,可以指定的情况如下:
- 12个直接指向: 12*1K=12K
由于是直接指向,所以总共可记录12笔记录,因此总额大小为如上所示; - 间接: 256*1K=256K
每笔block号码的记录会花去4bytes,因此1K的大小能够记录256笔记录,因此一个间接可以记录的档案大小如上; - 双间接: 256*256*1K=256 2 K
第一层block会指定256个第二层,每个第二层可以指定256个号码,因此总额大小如上; - 三间接: 256*256*256*1K=256 3 K
第一层block会指定256个第二层,每个第二层可以指定256个第三层,每个第三层可以指定256个号码,因此总额大小如上; - 总额:将直接、间接、双间接、三间接加总,得到12 + 256 + 256*256 + 256*256*256 (K) = 16GB
Superblock (超级区块)
记录的信息主要有:
- block 与inode 的总量;
- 未使用与已使用的inode / block 数量;
- block 与inode 的大小(block 为1, 2, 4K,inode 为128bytes 或256bytes);
- filesystem 的挂载时间、最近一次写入资料的时间、最近一次检验磁盘(fsck) 的时间等档案系统的相关信息;
- 一个valid bit 数值,若此文件系统已被挂载,则valid bit 为0 ,若未被挂载,则valid bit 为1 。
一般来说, superblock的大小为1024bytes。相关的superblock讯息我们等一下会以dumpe2fs指令来呼叫出来观察喔!
此外,每个block group 都可能含有superblock 喔!但是我们也说一个文件系统应该仅有一个superblock 而已,那是怎么回事啊?事实上除了第一个block group 内会含有superblock 之外,后续的block group 不一定含有superblock , 而若含有superblock 则该superblock 主要是做为第一个block group 内superblock 的备份咯,这样可以进行superblock的救援呢!
来源:https://blog.csdn.net/Ohmyberry/article/details/80427492
Linux文件访问流程及磁盘inode和block总结
Linux文件访问流程
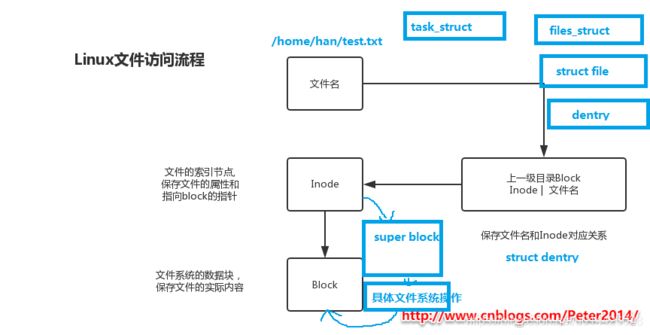
inode是文件的唯一标识,文件名和inode的对应关系存放在上一级目录的(hy:目录项 struct dentry)block中;inode里有指向文件block的指针和文件的属性,从而通过block获得文件数据。
磁盘的容量由inode和block共同决定

磁盘空间是否满了,是由两项参数决定的:
第一个是inode是否满了,第二是block是否满了,任何一个满了都不能存数据。
有关inode的总结
- 磁盘格式化创建文件系统时会生成一定数量的inode和block;
- inode称为索引节点,作用是存放文件的属性信息和指向block的指针;
- inode是磁盘上的一块存储空间,CentOS6默认inode大小为256字节;
- inode编号是唯一的,不同的文件有唯一的inode号;
- inode号相同的文件互为硬链接;
- 创建一个文件至少要占用一个inode和一个block;
- 查看inode总量和使用量 df -i;
- 查看文件的inode信息 ls -li 或 stat /etc/hosts;
- 生成指定的大小的inode mkfs.ext4 -b 2048 -I 256 /dev/sdb。
有关block的总结
- 磁盘存取文件是按block为单位存取的;
- 一个文件可能占用多个block,但是每读取一个block就会消耗一次磁盘I/O;
- 如果要提升磁盘IO性能,那么block应该大一点,从而能读取更多内容;
- block太大,存放小文件就会造成空间浪费;block太小,又会消耗磁盘IO;
- 要根据业务需求确定block大小,一般默认设置为4K;
- block大小也是格式化时确定的,命令是 mkfs.ext4 -b 2048 -I 256 /dev/sdb。
总的来说
- 磁盘格式化文件系统后,会分为inode和block两部分;
- inode存放文件属性和指向block的指针;
- 文件名和inode对应关系存放在上级目录里的block;
- inode默认256B,block默认4K;
- 通过df -i 查看inode数量及使用量;
- 查看 inode和block大小 dumpe2fs /dev/sda1 | egrep "Inode size|Block size";
- 一个文件至少占用一个inode和block,硬链接占用同一个inode;
- 一个block只能被一个文件使用,block太小,性能差,block太大,浪费空间;
- 通常,一块空间能放多少文件取决于inode和block的数量和大小,如果文件很小,那么block或inode就容易耗尽;如果文件很大,则应该用block的总数除以一个文件占用的block的数量得出存放文件的数目。
super_block
(1)super_block: 超级块
超级块就是对所有文件系统的管理机构,每种文件系统都要把自己的信息挂到super_blocks这么一个全局链表上。
超级块代表了整个文件系统,超级块是文件系统的控制块,有整个文件系统信息,一个文件系统所有的inode都要连接到超级块上,可以说,一个超级块就代表了一个文件系统。
注意:一个文件系统类型下可以包括很多文件系统即很多的super_block
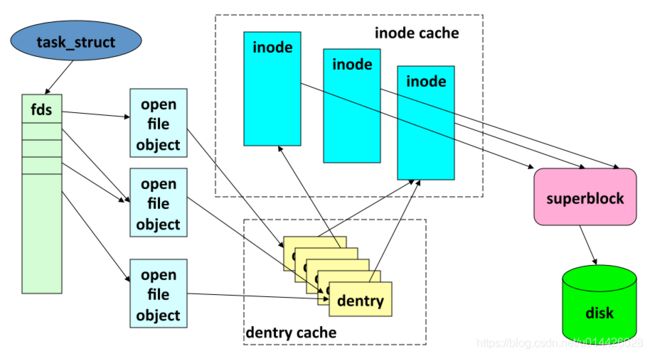
VFS,super_block,inode,dentry—结构体图解
总结:
VFS只存在于内存中,它在系统启动时被创建,系统关闭时注销。
VFS的作用就是屏蔽各类文件系统的差异,给用户、应用程序、甚至Linux其他管理模块提供统一的接口集合。
管理VFS数据结构的组成部分主要包括超级块和inode。
VFS是物理文件系统与服务之间的一个接口层,它对Linux的每个文件系统的所有细节进行抽象,使得不同的文件系统在Linux核心以及系统中运行的进程看来都是相同的。
严格的说,VFS并不是一种实际的文件系统。它只存在于内存中,不存在于任何外存空间。VFS在系统启动时建立,在系统关闭时消亡。
VFS使Linux同时安装、支持许多不同类型的文件系统成为可能。VFS拥有关于各种特殊文件系统的公共界面,当某个进程发布了一个面向文件的系统调用时,内核将调用VFS中对应的函数,这个函数处理一些与物理结构无关的操作,并且把它重定向为真实文件系统中相应的函数调用,后者用来处理那些与物理结构相关的操作。
下图就是逻辑上对VFS及其下层实际文件系统的组织图,可以看到用户层只能与VFS打交道,而不能直接访问实际的文件系统,比如EXT2、EXT3、PROC,换句话说,就是用户层不用也不能区别对待这些真正的文件系统,不过,SOCKET虽然也属于VFS的管辖范围,但是有其特殊性,就是不能像打开大部分文件系统下的“文件”一样打开socket,它只能被创建,而且内核中对其有特殊性处理。

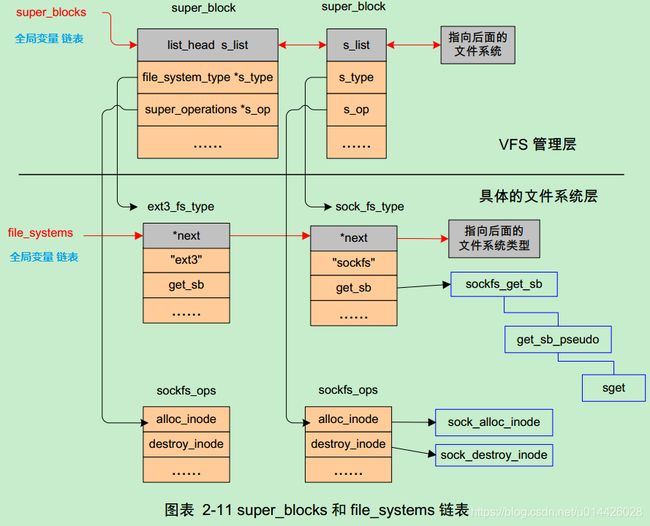
VFS描述文件系统使用超级块和inode 的方式,所谓超级块就是对所有文件系统的管理机构,每种文件系统都要把自己的信息挂到super_blocks这么一个全局链表上。
内核中是分成2个步骤完成:首先每个文件系统必须通过register_filesystem函数将自己的file_system_type挂接到file_systems这个全局变量上,然后调用kern_mount函数把自己的文件相关操作函数集合表挂到super_blocks上。每种文件系统类型的读超级块的例程(get_sb)必须由自己实现。
文件系统由子目录和文件构成。每个子目录和文件只能由唯一的inode 描述。inode 是Linux管理文件系统的最基本单位,也是文件系统连接任何子目录、文件的桥梁。
VFS inode的内容取自物理设备上的文件系统,由文件系统指定的操作函数(i_op 属性指定)填写。VFS inode只存在于内存中,可通过inode缓存访问。
1、super_block
- 相关的数据结构为:
struct super_block{struct list_head s_list;/* Keep this first */// 连接super_block的链表dev_t s_dev;/* search index; _not_ kdev_t */unsignedlong s_blocksize;unsignedlong s_old_blocksize;unsignedchar s_blocksize_bits;unsignedchar s_dirt;unsignedlonglong s_maxbytes;/* Max file size */struct file_system_type *s_type;// 所表示的文件系统的类型struct super_operations *s_op;// 文件相关操作函数集合表struct dquot_operations *dq_op;//struct quotactl_ops *s_qcop;//struct export_operations *s_export_op;//unsignedlong s_flags;//unsignedlong s_magic;//struct dentry *s_root;// Linux文件系统中某个索引节点(inode)的链接struct rw_semaphore s_umount;//struct semaphore s_lock;//int s_count;//int s_syncing;//int s_need_sync_fs;//atomic_t s_active;//void*s_security;//struct xattr_handler **s_xattr;//struct list_head s_inodes;/* all inodes */// 链接文件系统的inodestruct list_head s_dirty;/* dirty inodes */struct list_head s_io;/* parked for writeback */struct hlist_head s_anon;/* anonymous dentries for (nfs) exporting */struct list_head s_files;// 对于每一个打开的文件,由file对象来表示。链接文件系统中filestruct block_device *s_bdev;//struct list_head s_instances;//struct quota_info s_dquot;/* Diskquota specific options */int s_frozen;//wait_queue_head_t s_wait_unfrozen;//char s_id[32];/* Informational name */void*s_fs_info;/* Filesystem private info *//*** The next field is for VFS *only*. No filesystems have any business* even looking at it. You had been warned.*/struct semaphore s_vfs_rename_sem;/* Kludge *//* Granuality of c/m/atime in ns.Cannot be worse than a second */u32 s_time_gran;};
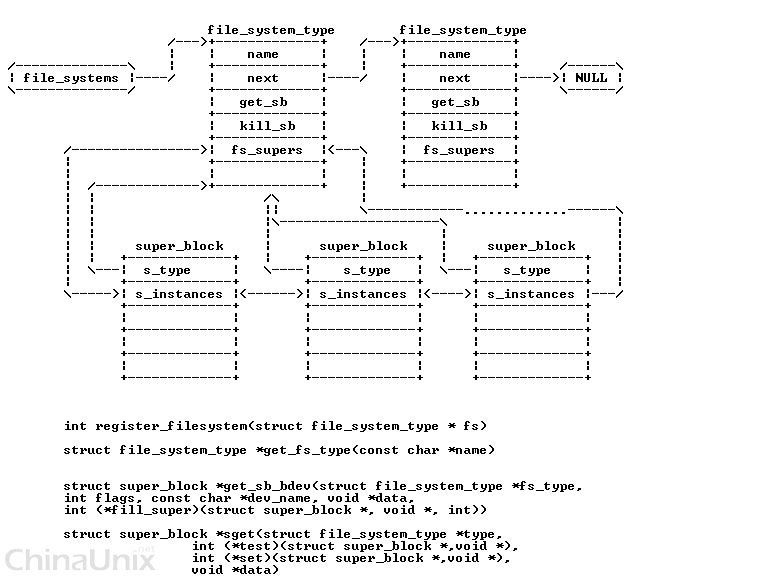
- super_block存在于两个链表中,一个是系统所有super_block的链表, 一个是对于特定的文件系统的super_block链表.
所有的super_block都存在于 super_blocks(VFS管理层) 链表中:

- 对于特定的文件系统(文件系统层的具体文件系统), 该文件系统的所有的super_block 都存在于file_sytem_type中的fs_supers链表中.
而所有的文件系统,都存在于file_systems链表中.这是通过调用register_filesystem接口来注册文件系统的.
int register_filesystem(struct file_system_type * fs)
2、inode
inode(发音:eye-node)译成中文就是索引节点,它用来存放档案及目录的基本信息,包含时间、档名、使用者及群组等。
inode 是 UNIX 操作系统中的一种数据结构,其本质是结构体,它包含了与文件系统中各个文件相关的一些重要信息。在 UNIX 中创建文件系统时,同时将会创建大量的 inode 。
通常,文件系统磁盘空间中大约百分之一空间分配给了 inode 表。
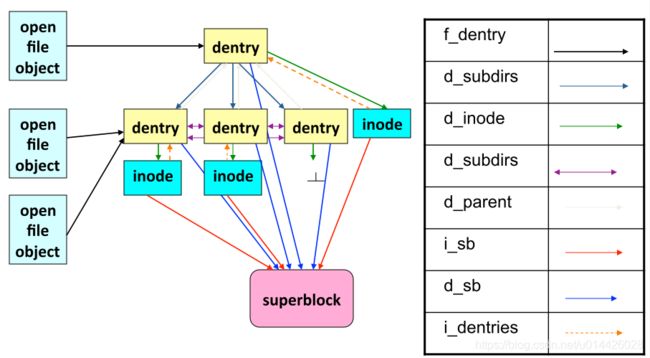
dentry的中文名称是目录项,是Linux文件系统中某个索引节点(inode)的链接。这个索引节点可以是文件的,也可以是目录的。
inode对应于物理磁盘上的具体对象,dentry是一个内存实体,其中的d_inode成员指向对应的inode。
相关的数据结构为:
/** Keep mostly read-only and often accessed (especially for* the RCU path lookup and 'stat' data) fields at the beginning* of the 'struct inode'*/struct inode{umode_t i_mode;unsignedshort i_opflags;kuid_t i_uid;kgid_t i_gid;unsignedint i_flags;#ifdef CONFIG_FS_POSIX_ACLstruct posix_acl *i_acl;struct posix_acl *i_default_acl;#endifconststruct inode_operations *i_op;struct super_block *i_sb;struct address_space *i_mapping;#ifdef CONFIG_SECURITYvoid*i_security;#endif/* Stat data, not accessed from path walking */unsignedlong i_ino;/** Filesystems may only read i_nlink directly. They shall use the* following functions for modification:** (set|clear|inc|drop)_nlink* inode_(inc|dec)_link_count*/union{constunsignedint i_nlink;unsignedint __i_nlink;};dev_t i_rdev;loff_t i_size;struct timespec i_atime;struct timespec i_mtime;struct timespec i_ctime;spinlock_t i_lock;/* i_blocks, i_bytes, maybe i_size */unsignedshort i_bytes;unsignedint i_blkbits;blkcnt_t i_blocks;#ifdef __NEED_I_SIZE_ORDEREDseqcount_t i_size_seqcount;#endif/* Misc */unsignedlong i_state;struct mutex i_mutex;unsignedlong dirtied_when;/* jiffies of first dirtying */unsignedlong dirtied_time_when;struct hlist_node i_hash;struct list_head i_wb_list;/* backing dev IO list */struct list_head i_lru;/* inode LRU list */struct list_head i_sb_list;union{struct hlist_head i_dentry;struct rcu_head i_rcu;};u64 i_version;atomic_t i_count;atomic_t i_dio_count;atomic_t i_writecount;#ifdef CONFIG_IMAatomic_t i_readcount;/* struct files open RO */#endifconststruct file_operations *i_fop;/* former ->i_op->default_file_ops */struct file_lock_context *i_flctx;struct address_space i_data;struct list_head i_devices;union{struct pipe_inode_info *i_pipe;struct block_device *i_bdev;struct cdev *i_cdev;};__u32 i_generation;#ifdef CONFIG_FSNOTIFY__u32 i_fsnotify_mask;/* all events this inode cares about */struct hlist_head i_fsnotify_marks;#endifvoid*i_private;/* fs or device private pointer */};
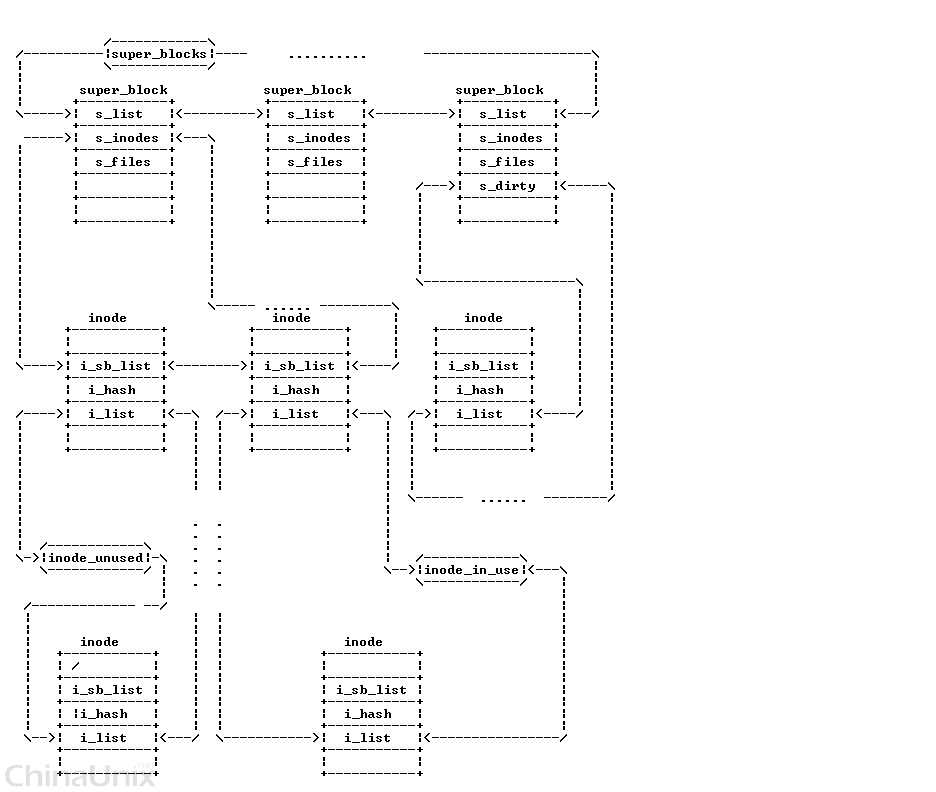
inode存在于两个双向链表中:
一个是inode所在文件系统的super_block的 s_inodes 链表中
一个是根据inode的使用状态存在于以下三个链表中的某个链表中:
- 未用的: inode_unused 链表
- 正在使用的: inode_in_use 链表
- 脏的: super block中的s_dirty 链表
另外,还有一个重要的链表: inode_hashtable(这个暂不介绍).
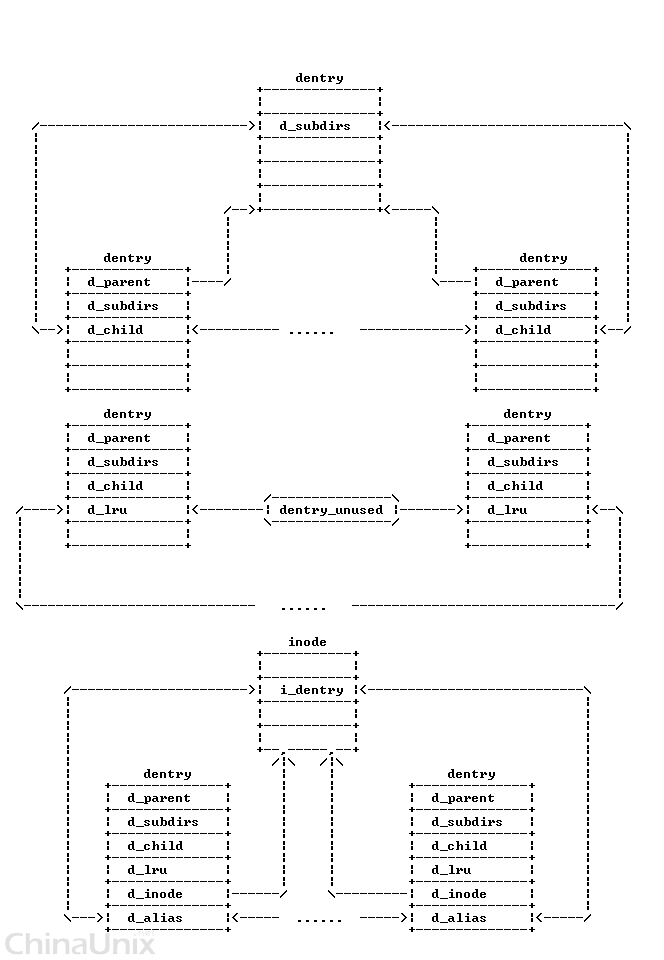
3、dentry
struct dentry{/* RCU lookup touched fields */unsignedint d_flags;/* protected by d_lock */seqcount_t d_seq;/* per dentry seqlock */struct hlist_bl_node d_hash;/* lookup hash list */struct dentry *d_parent;/* parent directory */struct qstr d_name;struct inode *d_inode;/* Where the name belongs to - NULL is* negative */unsignedchar d_iname[DNAME_INLINE_LEN];/* small names *//* Ref lookup also touches following */struct lockref d_lockref;/* per-dentry lock and refcount */conststruct dentry_operations *d_op;struct super_block *d_sb;/* The root of the dentry tree */unsignedlong d_time;/* used by d_revalidate */void*d_fsdata;/* fs-specific data */struct list_head d_lru;/* LRU list */struct list_head d_child;/* child of parent list */struct list_head d_subdirs;/* our children *//** d_alias and d_rcu can share memory*/union{struct hlist_node d_alias;/* inode alias list */struct rcu_head d_rcu;} d_u;};
dentry对象存在于三个双向链表中:
- 所有未用的目录项: dentry_unused 链表
- 正在使用的目录项: 对应inode的 i_dentry 链表
- 表示父子目录结构的链表
另外,还有一个重要的链表: inode_hashtable(这个暂不介绍).

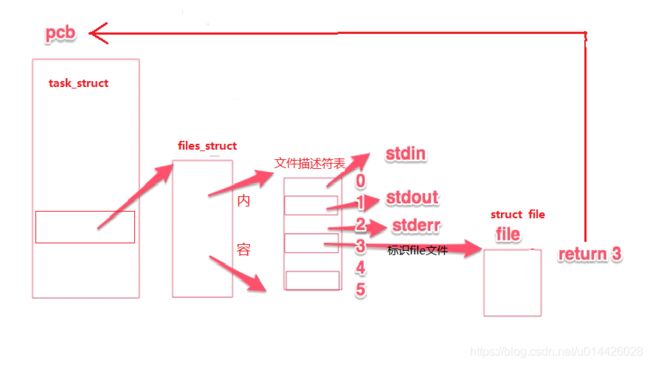
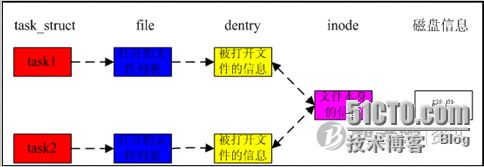
下图为多个进程打开同一文件的情况:
https://www.cnblogs.com/volcanorao/p/5992071.html