NeurIPS 2019 少样本学习研究亮点全解析
作者:Angulia Chao
编辑:Joni Zhong
少样本学习(Few-Shot Learning)是近两年来非常有研究潜力的一个子方向,由于深度学习在各学科交叉研究与商业场景都有比较普遍的应用,然而训练出高精度模型的情况大部分来源于充足的训练数据,这一条件在很多实际应用场景中是比较难以满足的,同时刻意收集大量数据并且进行人为标记也对应较大的付出。
针对此类痛点,少样本学习被提出并进行了多个应用场景下的尝试。本届 NeurIPS 2019 也收录了近十篇关于少样本学习的文章,他们或是从数据增强的角度出发,或是从特征表征(Feature Representation)的加强提出了新的思路。本文涵盖了本届 NeurIPS 收录的少样本学习文章,着眼于工作的实用性,创新性以及延续性三个维度,详解分析了三篇笔者认为非常具有启发性和实用性的少样本学习文章,概述了其余几篇的贡献和亮点,以期给感兴趣的读者呈现关于该方向最新的研究进展,以及对后续研发的启示。
Few-shot Video-to-Video Synthesis
类比于 Image-to-Image, 将特定场景下的输入图像转换到另一场景生成新图,Wang et al 在 2018 提出的视频到视频的合成(Video-to-Video synthesis, 简称 vid2vid)将连续多帧图像构成的视频,转换到新场景下并生成新的语义场景下的视频。本文是作者在该文基础上做的扩展。参考下图,根据对应的人体关键点姿态运动视频(pose videos),模型相应合成真人的动作视频。之前提出 Vid2vid 文献的局限也非常明显:数据需求量太大,合成模型表达能力有限。首先,对于合成某人真人运动视频要求模型有大量目标对象的图像来完成训练,对数据量的要求巨大,其次单个姿态到真人视频合成 vid2vid 模型通常只能合成训练集里包括的人体个体,无法生成任何不处于训练集中的人的运动视频。
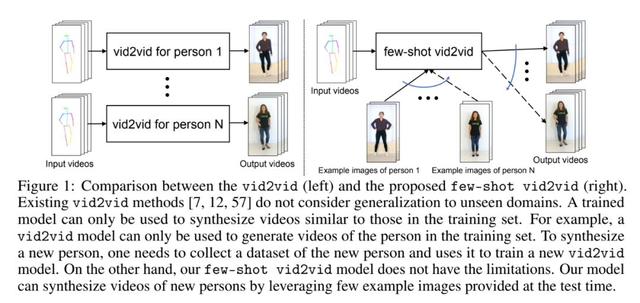
基于以上限制,few-shot vid2vid 方法提出在测试阶段喂给模型少量目标样本的图像,学习合成未见过的目标个体或者场景的对应视频。参考右图示意,不需要为每个人和每个特定场景都寻找大量的训练样本来合成视频,对于未知个体,可以通过 few-shot vid2vid 模型本身的场景泛化能力,使得测试阶段提供少量目标图像就可以合成同样的真人运动视频。相较于已有的 vid2vid 工作,few-shot vid2vid 工作的亮点集中于:1. 除了人体姿态的语义视频,额外增加了少量目标真人的图片作为模型测试阶段的额外输入。2. 使用了新颖的网络参数生成(Network Weight Generation)机制, 利用这少量的目标图片训练了一个模块来生成网络对应的参数。结合架构图,我们可以进一步了解 few-shot vid2vid 框架的详细设计:
简化地说,vid2vid 任务的学习目标就是模拟一个映射函数 F(mapping function)将语义视频的输入序列 S 映射转换为合成视频输出序列 X』,同时合成结果 X』的条件分布(conditional distribution)令其跟真实目标 X 的条件分布尽可能接近(简单说输出目标视觉上应该与真实目标是一致的)。为了学习这个条件分布,现有工作通过一个简单的马尔科夫假设(Markov assumption),构建了一个序列生成模型 F(sequential generative model)来学习生成我们的目标输出序列, 生成模型 F 通常有几种不同的建模方式,在文章里沿用了大多数 vid2vid 工作 (Fig a) 采用的图像提取方程(image matting function):
![]()
作为进一步延伸,few-shot vid2vid 的合成函数多了图像样本(sample e)加上语义样本(semantic sample se)两个额外输入:
![]()
要得到目标输出的合成结果 X,函数计算的核心模块为软掩盖图 m(soft occlusion map),多帧图像构成的光流 w(optical flow),以及半合成图像 h(synthesized intermediate image),三个模块带入到深度学习,又可以被表示为一个个神经网络参数化后的计算函数(计算模块)为 M,W,H,其涉及的参数都可以被网络学习并且在完成训练之后固定:
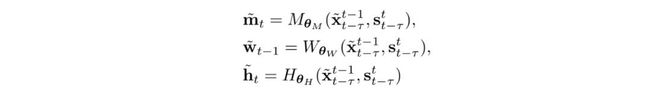
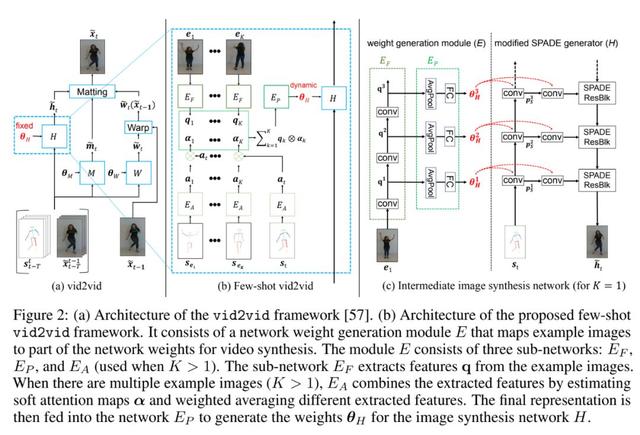
few-shot vid2vid 在整体框架上仍然沿用了目前的 SOTA 方法,保留了光流预测模块子网络 W 以及软掩盖图预测模块子网络 M。而考虑到我们的额外少量目标图片输入,few-shot vid2vid 集中优化了中间图像合成的模块 H(Fig b, c),用一个语义图像合成模型 SPADE 作为图片生成器取代了原先工作中的生成模型,SPADE 模型包含多个空间微调分支(spatial modulation branch)以及一个主要的图像合成分支,同时提出一个额外的网络参数生成模块 E(network weight generation module),使用该模块 E 作用于每个空间微调分支,来抽取一些视频内存在的有用模式,从而使得生成器能够合成未训练过的场景的视频结果。
参考上图中的 b,c 模块,E 分别由 EA,EP,EF 三个子网络模块构成,EF 由多个卷积层组织起来进行图像特征抽取,EA 模块则通过预测软注意力图(soft attention maps)和加权平均(weighted average)操作将多张图像抽得的特征进行糅合,最终得到的糅合表征输入到子网络 EP 当中,使得我们可以得出改良后的 SPADE 生成模块分支,产生生成模型需要学习到的参数Ɵ。
![]()
基于如上的整体网络结构,few-shot vid2vid 又包含了诸如基于注意力的聚合方法(attention-based aggregation),图像变形(example image warping),训练与推理过程调整等具体实现中的技巧,在 YouTube dancing videos,Street-scene videos,Face videos 三个公开数据集上做了方法的验证,都取得了目前最好的性能指标。
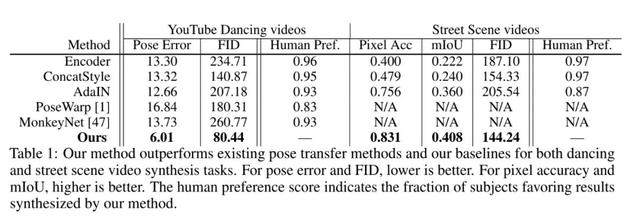
视觉合成效果上直观来看,无论是人体姿态动作和成,街道场景合成,或者人脸合成任务,few-shot vid2vid 都实现了一个直观而清晰的合成结果,对比其他方法,有比较高的准确度和辨识度。
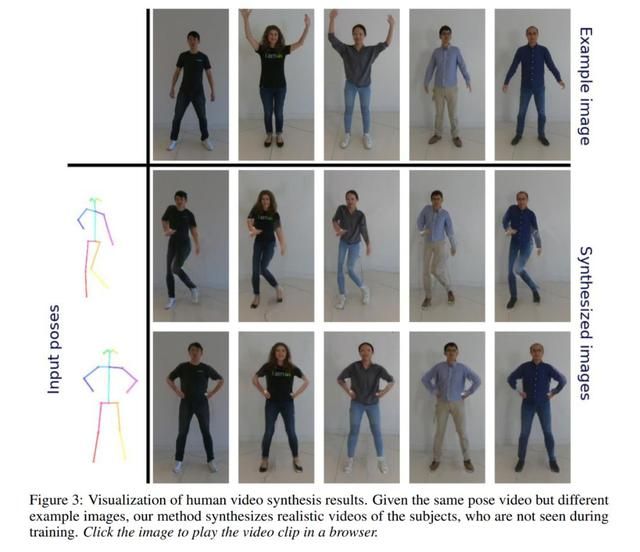
综合英伟达之前出的一系列生成模型相关论文,这篇 few-shot vid2vid 从少样本学习的角度切入,着眼于生成模型优化并巧妙加入少量目标图像为辅助信息学习条件分布,针对视频合成的高级视觉任务而非目前占比例较高的分类识别任务,最终在几个数据集上结果呈现很不错,作者同步还公开了代码以及一个三分钟的演示小视频,是一篇值得关注的好工作。
Paper: https://arxiv.org/pdf/1910.12713.pdfCode: https://github.com/NVlabs/few-shot-vid2vidVideo: https://www.youtube.com/watch?v=8AZBuyEuDqc
Incremental Few-Shot Learning with Attention Attractor Networks
这篇文章研究将少样本增量学习(Incremental Few-Shot Learning)应用到分类问题当中,增量学习(Incremental Learning)作为一种动态的机器学习方法,在不遗忘已学过的知识的同时,能够持续输入新的数据来扩展现有模型,对于增量学习陌生的读者可以参考我们之前的文章(https://www.jiqizhixin.com/graph/technologies/09134d6a-96cc-409b-86ef-18af25abf095)。
对于一般的深度分类模型来说,训练学习过程都是根据固定类别来进行的,然而实际的应用场景中随着业务的迭代,持续的新增学习类别是非常常见的,同时很难做到每个类别可用数据都充分且平衡,此时怎样固定记忆住已学会的种类,同时更好的识别新增的少样本类别,就是一个少样本增量学习问题。为了解决少样本增量学习的分类任务,文章提出一个基于元学习(meta learning)的注意力吸引网络(Attention Attractor Network,AAN),结合循环式反向传播,训练新增类别直到其收敛,之后在所有的分类类别(固有类别以及新增类别)的验证集上做分类性能评估。
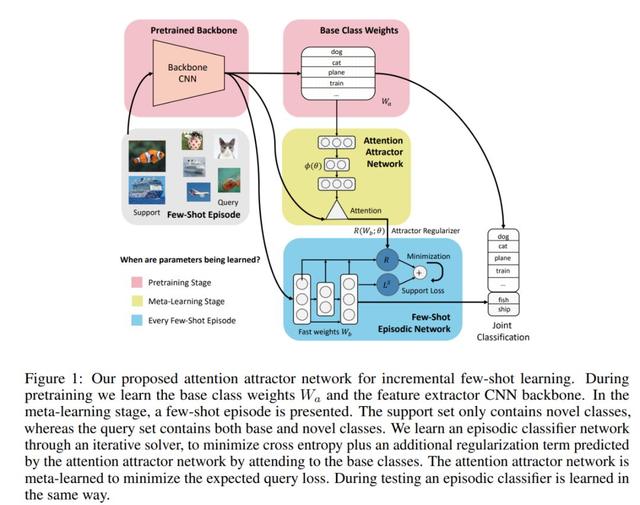
结合整个少样本增量学习的模型 AAN 模块图,我们来理解下其整体的一个计算流程:(1)首先用传统的监督学习在固有类别上训练出一个分类器,且学习到一个固定的特征表达,此阶段也可称为预训练阶段(Pretraining Stage),(2)在每个训练和测试的节点(episode),我们就结合元学习正则化矩阵(meta-learned regularizer)训练一个新类别分类器,(3)将新增类别和固有类别的分类结合起来,优化上一阶段的正则模块,使其能够在结合固有分类器之后一样发挥作用。
接下来我们将涉及到的每一个阶段结合优化公式展开来看:
预训练阶段:这一个阶段并没有额外的特殊操作,给定固有类别分类所有的数据和对应的类别标签,训练一个固有类别分类器,及其对应的特征表达,得到一个基本的分类模型即可。
增量少样本学习:提出少样本学习的增量类别数据集 D,用于该阶段的少样本节点学习。对于每个学习的 N-shot K』-way 节点,每次都分别选中不同于固有类别的 K』个新增类,每个新增类都分别有来自支撑集 S(Support Set)的 N 张图片,以及 M 张来自查询集 Q(Query Set)的图片。而提及的 S 和 Q 两个图片集合,可以被当做每个节点学习时候用到的训练集和验证集。每个节点都从训练集 S 学到一个新的分类器,同时分类器对应的学习参数 W 通常只有效作用于本节点,被称为速用参数(fast weights)。为了能够全面地衡量整体分类效果,训练算法过程中只允许接触新增类别的训练集 S,然而验证模型的时候采用了新增类别加固有类别合并的验证集 Q。
元学习正则约束:元学习的整体过程就是迭代地重复上一阶段中提到的训练过程,在新增分类训练集上得到新的分类器,同时在验证集 Q 上进行性能验证,结合交叉熵损失函数(Cross Entropy Loss)与额外引入的正则项 R(Ɵ)作为优化目标函数来学习更新速用参数 W, 其中Ɵ是元参数(meta-parameters),在本文中被结合嵌入到了注意力吸引网络(AAN)中。AAN
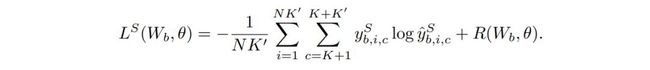
得到了整体的优化目标函数(文中 cheng 为 Episodic Objective,情节目标)。我们考虑在学习过程中,模型参数 W 的本质就是要最优化新增类别的预测,那么针对局部的每个节点训练后的验证过程,直接后果就是固有类别的性能无法保证,如果直接令上述优化目标函数的正则项 R 为 0 或者简单用权重衰减(weights decay)策略,那么就会造成灾难性的固有类别遗忘问题。基于此种考虑,上面提到的目标函数重要的一项,就是通过引入注意力吸引网络(AAN)作为优化的正则项 R,将固有类别的一些信息特征进行编码,之后参数化为恒用参数(low weights)存储使用,并通过整个 AAN 结构来最小化学习元参数Ɵ,
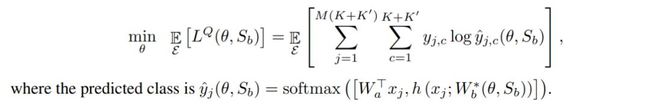
其中正则项 R(W,Ɵ)也正是 AAN 网络中的一个核心点,其公式如下:
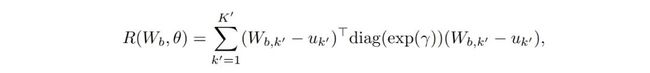
式子中的 u_k 也就是 AAN 中所谓的 attractor 部分,W 则是提过的权重参数,通过基于 Mahalanobis 距离平方和外加一个偏置项,我们的正则部分 R 就可以实现单一地从新类别中获取学习信息的这一过程,并且避免提到过的类别遗忘问题。
另一方面,由于节点式元学习的目标函数并不是闭式的(closed-form),参数更新和目标函数优化存在于每一个节点学习中,所以具体实现过程中该论文借鉴了时序性反传(Back-Propagation Through Time,BPTT)的思想,使用了递归反传算法(Recurrent Back-Propagation,RBP)做到有效的参数迭代学习。
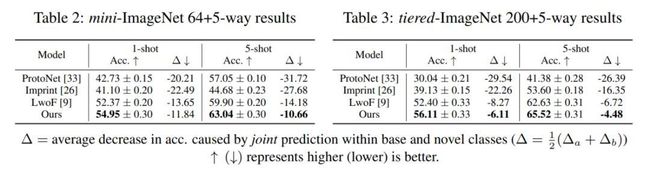
至于试验阶段,文章在少样本学习两个知名的 benchmark 数据集上 mini-ImageNet 与 tiered-ImageNet 上验证了提出算法的有效性,同其他方法类比达到了 SOTA 的效果。
文章整体算法流程的伪代码总结如下图:

总的来说,文章研究的增量学习面对少样本数据的情况是一个具有实际应用意义的问题,文章研究的对少样本的学习用增量迭代的方式递进也是非常有趣的一个思路。目前该工作的代码也已开源,除了在标准的给定数据集上跑分,感兴趣的读者也可以进一步考证其在实际场景应用下的实用性,与此同时受该工作启发,之后的相关工作是否能够结合类别之间的语义关联性,更有效地做少样本的递进增量学习或许也是我们值得期待的一个潜在方向。
Paper: https://papers.nips.cc/paper/8769-incremental-few-shot-learning-with-attention-attractor-networks.pdf_ _Code: https://github.com/renmengye/inc-few-shot-attractor-public
Adaptive Cross-Modal Few-shot Learning
基于度量的元学习(metric-based meta-learning)如今已成为少样本学习研究过程中被广泛应用的一个范式。这篇文章提出利用交叉模态信息(cross-modal information)来进一步加强现有的度量元学习分类算法。
在本文中,交叉模态是指视觉和语言的信息;结构定义上来说视觉信息和语义信息有截然不同的特征空间,然而在识别任务上二者往往能够相互辅助,某些情况下视觉信息比起语义文字信息更加直观,也更加丰富,利于分类识别,而另一些情况下则恰恰相反,比如可获得的视觉信息受限,那么语义表达自然是能够提供强大的先验知识和背景补充来帮助学习提升。
参考少样本学习时可能会遇到的困难样本如下图:左边示例的每对图片在视觉信息上非常类似,然而他们实际上归属语义相差很大的不同类别,右边示例的每对图片视觉信息差异较大,然而所属的语义类别都是同一个。这两组例子很好证明了当视觉信息或语义信息之一缺失的情况下,少样本分类学习由于样本数目的匮乏,提供到的信息很可能是有噪声同时偏局部的,很难区分类似的困难样本。

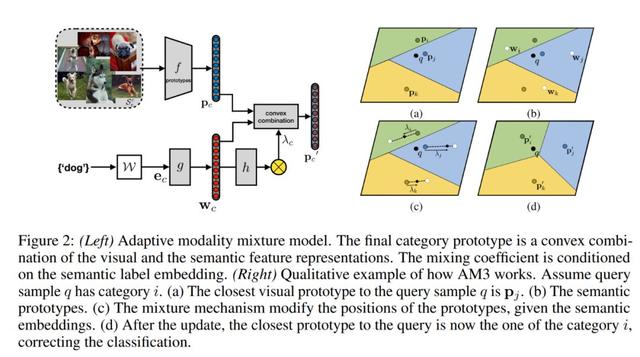
根据如上的场景假设,文章提出一个自适应交叉混合的机制(Adaptive Modality Mixture Mechanism,AM3):针对将要被学习的图像类别,自适应地结合它存在于视觉和语义上的信息,从而大幅提升少样本场景下的分类任务性能。具体来说,自适应的 AM3 方法并没有直接将两个信息模块对齐起来然后提供辅助,也没有通过迁移学习转化语义信息作为视觉特征辅助(类似视觉问答 VQA 任务那样),而是提出更优的方式为,在少样本学习的测试阶段独立地处理两个知识模块,同时根据不同场景区分适应性地利用两个模块信息。
比如根据图像所属的种类,让 AM3 能够采用一种自适应的凸结合(adaptive convex combination)方式糅合两个表征空间并且调整模型关注侧重点,从而完成更精确的少样本分类任务。对于困难样本,在上图左边不同类别视觉相似度高的情况下,AM3 侧重语义信息(Semantic modality)从而获得泛化的背景知识来区分不同类别;而上图右边同类别图片视觉差距大的情况下,AM3 模型侧重于视觉信息(Visual modality)丰富的局部特征从而更好捕捉同类图片存在的共性。
在对整个算法有初步印象之后,我们结合 AM3 模型示意图来观察更多细节:
首先少样本分类采用的学习方式仍然是 K-way N-shot 的节点学习(episodic training)过程,一方面是来自 N 个类别的 K 张训练图片 S 用作支撑集(Support Set),另一方面是来自同样 N 个类别的测试图片作为查询集 Q(Query Set),并根据分类问题损失定义得到如下参数化的方程为优化目标:
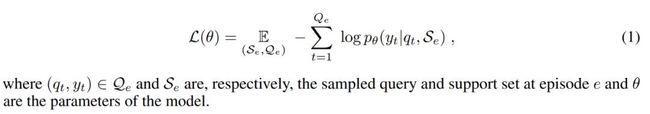
在基础模型网络方面,AM3 采用了一个比较简洁的 Prototypical Network 作为例子,但也可以延伸到其他网络使用:利用支撑集为每个类别计算一个类似于聚类一样的中心聚点(centroids),之后对应的查询集样本只需与每个中心点计算距离就可以得到所属类别。对于每一个节点 e(episode)都可以根据平均每个类别所属支撑样本的嵌入特征得到嵌入原型 Pc(embedding prototype)以及分布的函数 p:
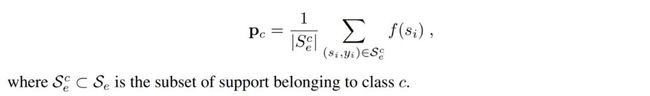
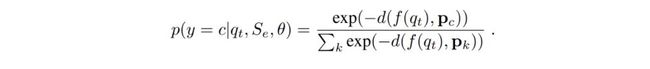
在 AM3 模型里,为了如之前说到的更灵活地捕捉语义空间的信息,文章在 Prototypical Network 的基础上进一步增加了一个预训练过的词嵌入模型 W(word embedding),包含了所有类别的标签词向量,同时修改了原 Prototypical Network 的类别表征,改为同时考虑视觉表达与语义标签表达的结合。而新模型 AM3 的嵌入原型 P』c 同学习函数,用类似正则项的更新方式得到为:
![]()
其中,$\lamda$是自适应系数,定义为下式,其中 h 作为自适应混合函数(adaptive mixing network),令两个模态混合起来如 Fig 2(a) 所示
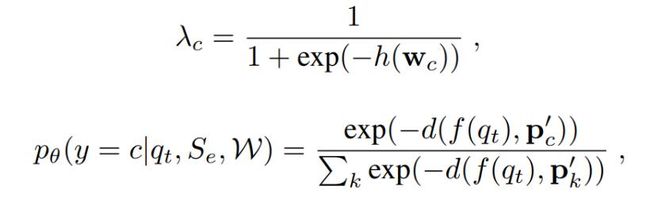
上式 p(y=c|q,S,Ɵ)是作为该节点在 N 个类别上由模型学习到的分布,整体来说是根据查询样本 q 的嵌入表达到嵌入原型直接的距离 d,最终做了一个 softmax 操作得到的。距离 d 在文章中简单地采用了欧氏距离,模型通过梯度下降算法(SGD)最小化学习目标损失 L(Ɵ)的同时,也不停地更新迭代相关参数集合。
基于并不复杂的模型,文章在少样本数据集 miniImageNet,tieredImageNet 以及零样本学习数据集上都验证了自己的方法,均取得了非常好的成绩
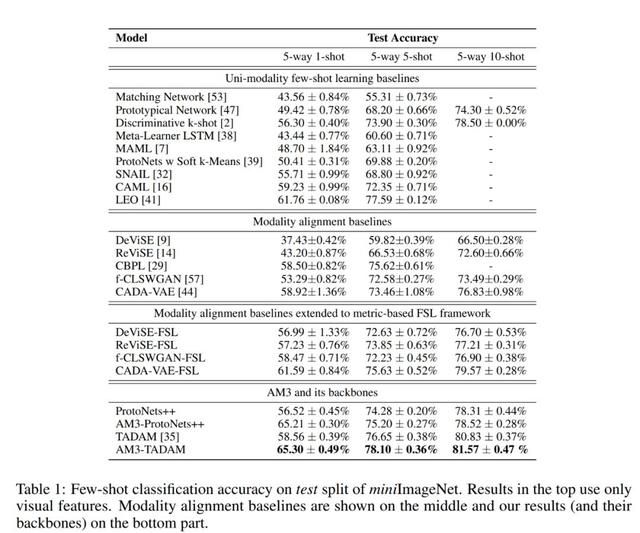
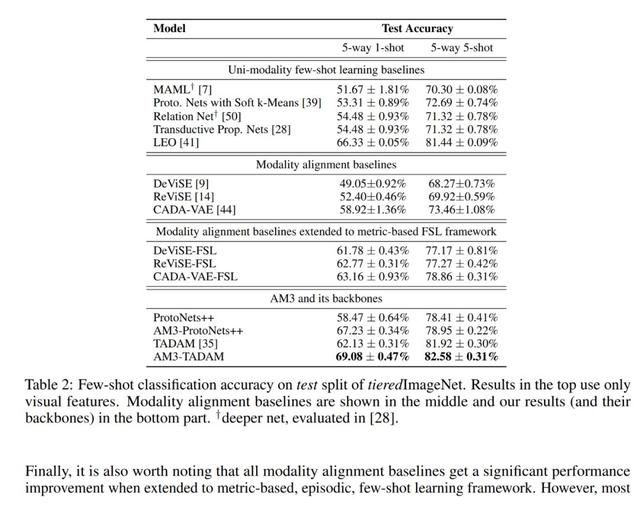
总的来看 AM3 这个工作也提出了一个非常有意思的少样本学习切入点,即多个空间的信息互相补足与制约,AM3 网络优越性体现在结构的简洁和理论的完整性,目前该工作的代码也已经开源,感兴趣的读者可以进一步探索:除了 Prototypical Network 以外,更复杂的网络以及包含更多的模态信息。
Paper: https://papers.nips.cc/paper/8731-adaptive-cross-modal-few-shot-learning.pdfCode: https://github.com/ElementAI/am3
Cross Attention Network for Few-shot Classification
该文提出了一个名为交叉注意力网络(Cross Attention Network)的模型,一方面通过注意力机制建立待分类类别特征与查询样本之间的联系,并且突出目标个体所在区域,同时建立一种名为直推式学习(transductive learning)的半监督推理来解决少样本的数据缺乏困境,最终同样是在两个少样本的标准数据集上取得了性能的提升。
Paper: https://papers.nips.cc/paper/8655-cross-attention-network-for-few-shot-classification
Meta-Reinforced Synthetic Data for One-Shot Fine-Grained Visual Recognition
针对少样本细粒度识别分类(one-shot fine-grained visual recognition)任务下缺乏数据的问题,该文提出了用生成网络合成图像数据,利用元学习的方法将其于真实数据混合,放进名为 MetaIRNet(Meta Image Reinforcing Network) 的网络模型训练,最终达到识别效果的提升。
Paper: https://papers.nips.cc/paper/8570-meta-reinforced-synthetic-data-for-one-shot-fine-grained-visual-recognition
Dual Adversarial Semantics-Consistent Network for Generalized Zero-Shot Learning
该文针对泛化零样本学习问题(generalized zero-shot learning, GZSL)开创性地提出了一个双重对抗式语义连续网络(Dual Adversarial Semantics-Consistent Network, DASCN),在一个统一的 GZSL 问题框架下,用其学习原生 GAN 与其对偶的 GAN 网络,从而达到更好的任务识别效果。
Paper: https://papers.nips.cc/paper/8846-dual-adversarial-semantics-consistent-network-for-generalized-zero-shot-learning
Unsupervised Meta-Learning for Few-Shot Image Classification
这篇文章同样是针对少样本的分类学习问题,提出一种无监督式的元学习模型 UMTRA,并在两个数据集上取得了非常优秀的分类效果。
Paper: https://papers.nips.cc/paper/9203-unsupervised-meta-learning-for-few-shot-image-classification.pdf
Transductive Zero-Shot Learning with Visual Structure Constraint
该文提出一般的零样本学习方法都容易在数据分布的原生域(source domain)到目标域(target domain)的映射过程中出现局部偏移(domain shift)导致学习效果不尽如人意。文章借此提出一种新的视觉结构限制(visual structure constrain)来提升映射函数的泛化性,从而避免上述提到的偏移缺点,文章采用了新的训练策略,应用了提出的限制模块,在标准数据集上取得了不错的效果。
Paper: https://papers.nips.cc/paper/9188-transductive-zero-shot-learning-with-visual-structure-constraint
Order Optimal One-Shot Distributed Learning
文章提出了一种名为多分辨率预计(Multi-Resolution Estimator, MRE)的新算法,将其应用于少样本学习过程里的分布式统计优化。
Paper: https://papers.nips.cc/paper/8489-order-optimal-one-shot-distributed-learning 总的来说,本届 NeruIPS 收录的数篇少样本学习文章在学习任务上来说,大部分仍然集中于分类任务,并在几个标准数据集(benchmark dataset)如 miniImagenet 上进行算法性能验证。所以我们首先挑选的是一篇针对少样本视频合成的工作进行详解,少样本学习目前在视频领域的尝试并不多,few-shot vid2vid 利用生成模型的辅助以及自身设计的参数共享机制,将该任务在之前的 vid2vid 上做了进一步扩展,得到了更近一步贴合实际应用的一篇工作,可以说在任务内容上是非常有启发性的,同时合成效果性能方面也非常不错,使其在少样本任务扩展方面能给相关的科研业界工作者不少启发。
因为是针对生成模型的少样本学习,所以文章着重应用不同学习技巧,调整不同样本数据集的参数。另外两篇精讲的文章则都是基于分类任务来展开的,两者都调整了目标函数,增加了一个相似的 regularized 项,但用了两个不同的解决方案:AAN 这一篇工作使用了视觉任务常用的注意力机制(attention),结合增量学习的相关概念,巩固了少样本学习语境下,新类别学习同时常有的固有类别遗忘问题,利用 AAN 加入 regularized 项,从而减少灾难性遗忘的问题。再到 AM3 这篇工作,则是进一步地探索少样本分类中语义信息,视觉信息在不同类别下并不平衡的问题,并且提出了自己的自动纠偏机制,从而使得少样本分类器针对此类困难样本学习的情况,可以有更加鲁棒的性能。除此之外,其余概略提到的其他几篇文章,任务也大多仍集中在少样本分类问题或者零样本分类问题的范式下,都有各自独特的角度和切入点,有的从强化学习切入,有的借助了 GAN,注意力机制的辅助。
总的来说,在本届 NeurIPS 收录的少样本学习工作中,大都还是针对元学习(Meta-Learning)作为基本的学习范式展开自己的角度,注意力机制,生成模型,额外语义信息加成,都是本届收录文章中着眼引入的亮点,相信也会给之后少样本学习扩展到其他任务更多启发,我们也期待看到少样本学习与已有的增量学习、强化学习等概念做结合后产出的更多新思路。