性能测试:3 jmeter参数化策略及关联
参数化策略
参数化取值策略,即压测时,以怎样的方式,从CSV文件中取值。
在什么情况下需要参数化?数据库校验数据的唯一性时,比如注册接口;另外为了消除数据库查询缓存对测试正确性的影响,如果查询走缓存和不走缓存,查询时间相差很大;还有业务功能的设计需要用到参数化,比如获取学生新名单接口。
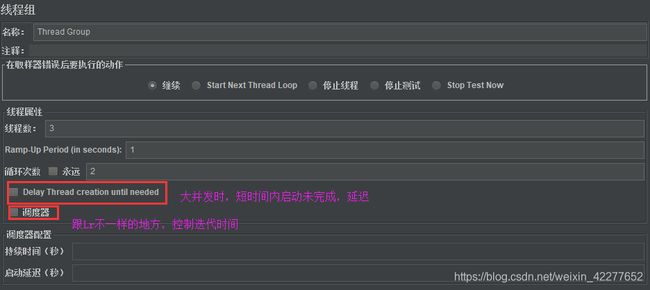



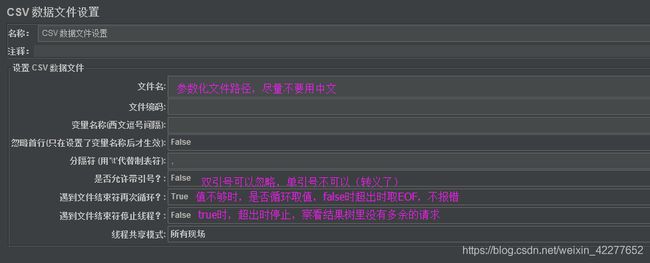

请求参数可抓包得到,或参考canshuhua-test.jmx文件
线程共享模式:
所有线程
测试计划下有两个线程组,一个CSV文件,每个线程组下设置线程数为3(用户数),循环次数为2
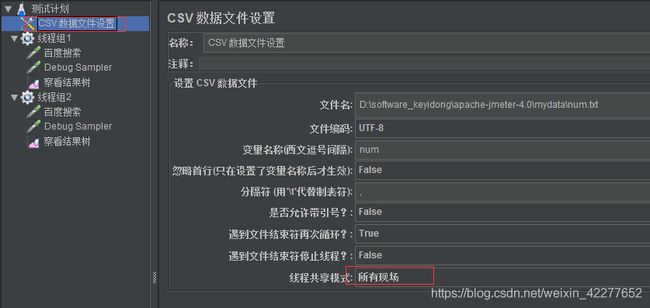
CSV文件中是从1到12的数字,压测时每个线程的取值如下
| 线程组1 |
线程组2 |
||||
| 线程1 |
线程2 |
线程3 |
线程1 |
线程2 |
线程3 |
| 2 |
3 |
5 |
1 |
4 |
6 |
| 7 |
9 |
12 |
8 |
10 |
11 |
即所有线程模式下,所有线程取值是不重复的,唯一取值
当前线程
测试计划下有两个线程组,一个CSV文件,每个线程组下设置线程数为3(用户数),循环次数为2
CSV文件中是从1到12的数字,压测时每个线程的取值如下
| 线程组1 |
线程组2 |
||||
| 线程1 |
线程2 |
线程3 |
线程1 |
线程2 |
线程3 |
| 1 |
1 |
1 |
1 |
1 |
1 |
| 2 |
2 |
2 |
2 |
2 |
2 |
即当前线程模式下,线程组1和2下的每个线程均按顺序取值。
当前线程组
测试计划下有两个线程组,一个CSV文件,每个线程组下设置线程数为3(用户数),循环次数为2
CSV文件中是从1到12的数字,压测时每个线程的取值如下
| 线程组1 |
线程组2 |
||||
| 线程1 |
线程2 |
线程3 |
线程1 |
线程2 |
线程3 |
| 1 |
2 |
3 |
1 |
2 |
3 |
| 4 |
5 |
6 |
4 |
5 |
6 |
即当前线程组模式下,线程组1和线程组2按照顺序取值,但线程组1和线程组2内的线程取值唯一。相当于将两个相同的CSV数据文件分别放在两个线程组下,取值模式均为所有线程。
关联
线程组内的值的传递,应用场景:一个请求的响应结果里的值,在下个请求里要用到。比如新建一个bug成功后会返回一个bug的id,在解决bug时需要用到这个id,即一个请求的返回结果的值作为下个请求的入参。
可参考jmeter调试待测接口里的JDBC请求,用正则表达式提取需要的值保存在一个变量里,在下个请求中用${变量名}引用这个变量。常见的需要关联的值有:各种id,session,token,以及特别的字符串。
线程组之间值的传递 ,应用场景:线程组A里的请求响应结果里的值,需要在线程组B里的请求中用到。添加一个后置处理器,将前面jmeter变量(提取到的值)添加到jmeter属性里,这样就可以在其他线程组里用这个jmeter属性。

在Debug Sampler响应结果里查看,JMeterProperties中是否有stu_mobile这个jmeter属性。

在另一线程组下新建http请求,并在http请求下添加一个前置处理器, 这样线程组1里的手机号就可以在线程组2中使用了。
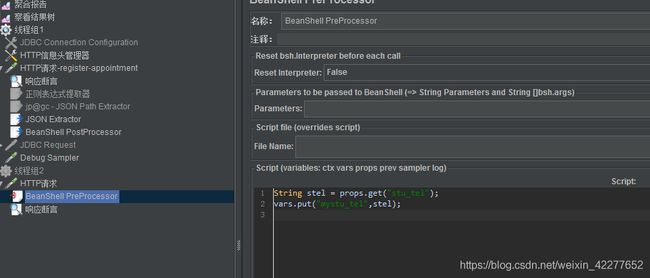
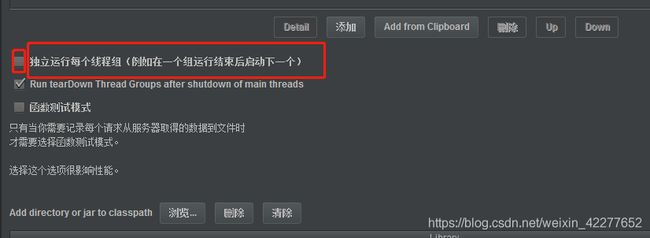
有时候取不到手机号 ,因为线程组是一起运行的,需要在测试计划里改成按顺序运行,即独立运行线程组。
================================================================================================
三、监控工具的使用
1、jmeter 插件
将两个jar包(JMeterPlugins-Extras.jar JMeterPlugins-Standard.jar)放到jmeter安装目录/lib/ext下,并将ServerAgent-2.2.1.zip上传到被测服务器,unzip 解压后启动
sh startAgent.sh
jmeter线程组下添加jp@gc - PerfMon Metrics Collector,设置IP,Port,Metric to collect
压侧时就可以看到被测服务器的相关资源使用情况

2、nmon
Centos测试服务器安装yum install nmon
实时查看常用命令nmon 进入监控界面输入cmdnt查看
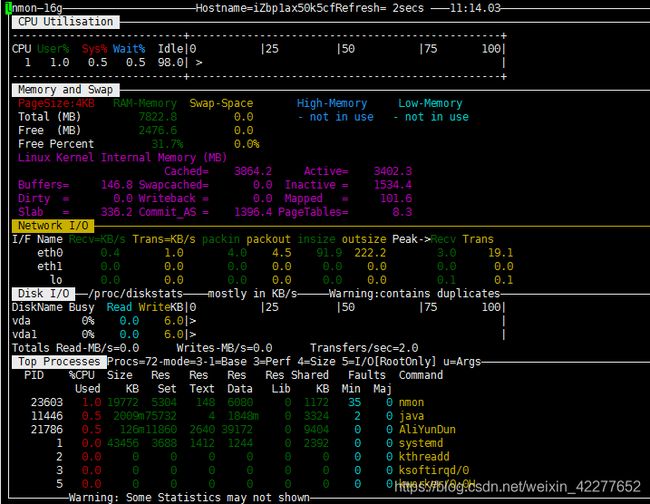
收集监控数据常用命令: nmon -s1 –c300 –f –m .
(每秒1次,取样300次,标准格式输出文件到当前目录下)
将文件下载到本地,用nmon analyser工具生成图表,图表中字段说明见文件 nmon分析文件指标详解
3、数据库分析工具percona-toolkit
yum install percona-toolkit
安装文档https://www.cnblogs.com/zishengY/p/6852280.html
设置慢查询日志sql
set global slow_query_log=on;#打开慢查询日志
set global long_query_time=1;#设置记录查询超过多长时间的sql
set global slow_query_log_file='/tmp/slow_query.log';#设置mysql慢查询日志路径,此路径需要有写权限
set global log_queries_not_using_indexes=ON; #设置没有使用索引的sql记录下来
查看重复索引, 使用pt-duplicate-key-checker -uroot -p密码 -h其他服务器Ip -d 数据库名;
查看不用或少用的索引,使用pt-index-usage –uroot –p密码 慢查询日志路径;
查看最近12小时的,使用pt-query-digest -- since=12h slow.log路径
查看汇总报告 , 用pt-query-digest 慢查询日志路径 > slow.report
4、JProfiler (见jprofiler定位性能问题)
5、内存分析工具mat,jconsole,VisualVM(略)
四、常见问题分析
1、内存泄漏
内存一直增加,发生FGC时,死掉的对象,无法通过垃圾回收器进行自动回收。
内存上的问题(内存泄漏,内存溢出,频繁FGC,FGC时间长),主要看堆,其他问题主要看栈。
ps –ef | grep java 查进程id
jmap –heap
jmap –histo
若用jmap –histo
jmap -dump:format=b,file=mem.bin
jhat mem.bin 浏览器访问IP:7000查看(消耗被测服务器资源,不常用)
将mem.bin文件下载到本地,用MAT工具打开,查看报告中的Problem Suspect
2、CPU冲高
压测时cpu高,top看一下,user cpu高,找到最耗CPU的pid
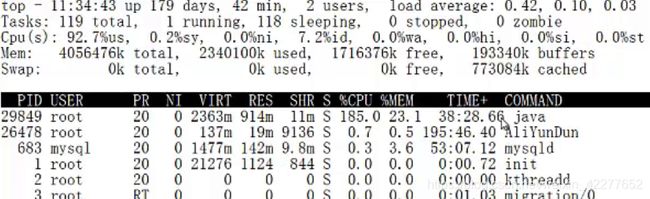
通过pid 找 具体耗CPU的线程
![]()

将线程pid, 10进制转成16进制,并用jstack命令查看Java线程的调用堆栈的信息,可以用来分析线程问题


GC线程是非应用程序调用的线程,GC任务,看GC 的情况.
用jstat 命令统计堆使用百分比、YGC和FGC次数和时间
jstat –gcutil

一直在进行 FGC,很耗CPU,导致CPU高的原因是频繁FGC,修改代码或JVM配置.
个人博客: http://weikeu.com