CentOS7使用Docker安装hadoop集群
Docker安装hadoop集群步骤
- 1、安装Docker
- 1)下载docker
- 2)启动docker
- 3)添加用户权限
- 2、安装hadoop镜像
- 1)拉取镜像
- 2)创建hadoop容器
- 3)配置ssh生成密钥
- 3、配置hadoop
- 1)配置hadoop-env.sh和jdk
- 2)配置core-site.xml
- 3)配置hdfs-site.xml
- 4)配置 mapred-site.xml
- 5)配置yarn-site.xml
- 6)修改slaves文件
- 4、准备启动集群
- 1)格式化NameNode
- 2)启动集群
- 5、测试集群
1、安装Docker
先更新一下yum,确保yum是最新的
[hadoop@bogon ~]$ sudo yum update
1)下载docker
[hadoop@bogon ~]$ sudo yum install -y docker
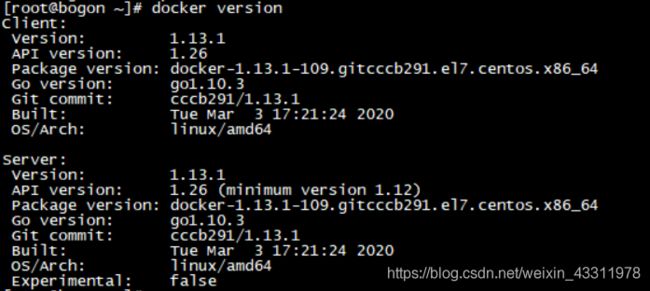
安装完成后,可以通过命令docker version查看
[root@bogon ~]# docker version
Client:
Version: 1.13.1
API version: 1.26
Package version:
Cannot connect to the Docker daemon at unix:///var/run/docker.sock. Is the docker daemon running?
2)启动docker
先切换到root来启动
[root@bogon ~]# service docker start
使用docker version验证是否安装成功,有client和service代表安装和启动都成功。
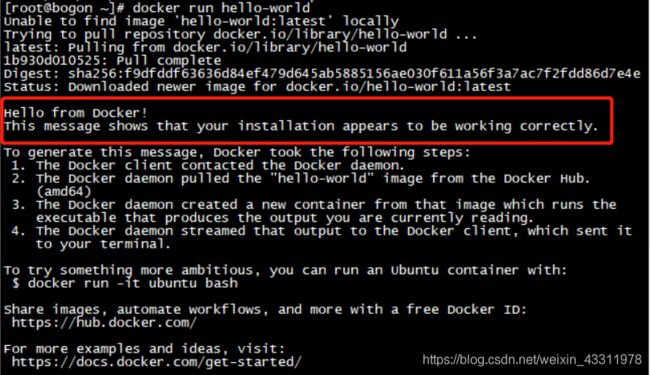
也可以运行Docker官方提供的hello-world程序检测Docker安装运行是否成功:
[root@bogon ~]# docker run hello-world
该命令会输出一大段文字,中间有一段文字是:
Hello from Docker!
This message shows that your installation appears to be working correctly.
代表安装成功!
第一次运行可能会失败,再运行一次就好了
需要的话可以设置开机自启动
[root@bogon ~]# systemctl enable docker
将enable改成disable即可关闭开机自启动
3)添加用户权限
docker默认是只有root才能执行Docker命令,因此我们还需要添加用户权限
创建docker用户组:
[root@bogon ~]# groupadd docker
添加用户到docker用户组:
(比如我这里要添加的是名为hadoop的用户)
[root@bogon ~]# gpasswd -a hadoop docker
重启Docker后台监护进程:
[root@bogon ~]# service docker restart
切换到刚才添加的用户,使用docker ps 测试:
[hadoop@bogon ~]$ docker ps
![]()
至此,Docker安装完成!
2、安装hadoop镜像
先参考这篇文章配置
https://blog.csdn.net/weixin_43273168/article/details/90677478
1)拉取镜像
启动docker后,输入以下命令在docker中查找hadoop 镜像
docker search hadoop
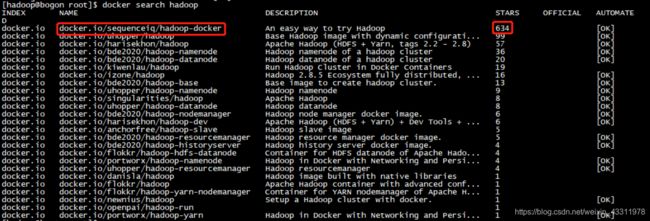
我们选择拉取star数量最多的镜像
docker pull docker.io/sequenceiq/hadoop-docker
等待拉取完成
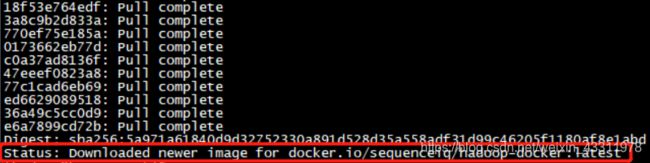
查看刚刚拉取的镜像
[hadoop@bogon root]$ docker images
![]()
2)创建hadoop容器
创建master节点
[hadoop@bogon root]$ docker run --name hadoop1 -d -h master docker.io/sequenceiq/hadoop-docker
参数说明:
-h 为容器设置主机名
–name 设置容器的名称
-d 在后台运行
![]()
同样的方法创建slave1和slave2节点
[hadoop@bogon root]$ docker run --name hadoop2 -d -h slave1 docker.io/sequenceiq/hadoop-docker
[hadoop@bogon root]$ docker run --name hadoop3 -d -h slave2 docker.io/sequenceiq/hadoop-docker
![]()
查看容器
[hadoop@bogon root]$ docker ps -s

3)配置ssh生成密钥
首先进入容器hadoop1
[hadoop@bogon root]$ docker exec -it hadoop1 bash
先将原有的公钥删除(如果有)
bash-4.1# rm /root/.ssh/authorized_keys
bash-4.1# rm /root/.ssh/id_rsa*
再输入下面两条命令
/etc/init.d/sshd start
ssh-keygen -t rsa
按三次回车即可
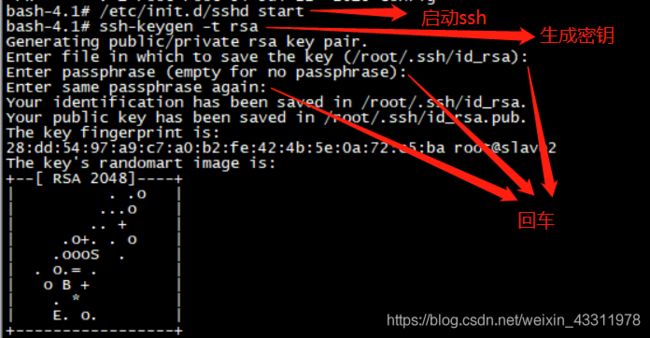
将公钥导入 authorized_keys文件
bash-4.1# cat /root/.ssh/id_rsa.pub >> /root/.ssh/authorized_keys
(注意:所有节点均要配置,方法同上,此处略)
然后将每个节点的公钥都复制到authorized_keys,也就是说每个节点的authorized_keys 文件中存储的公钥都是3个而且是一样的,可以采用下面的命令来进行复制,也可以自己手动复制
将三个容器中的文件复制到本地
[hadoop@bogon root]$ docker cp hadoop1:/root/.ssh/authorized_keys /home/hadoop/authorized_keys_master
[hadoop@bogon root]$ docker cp hadoop2:/root/.ssh/authorized_keys /home/hadoop/authorized_keys_slave1
[hadoop@bogon root]$ docker cp hadoop3:/root/.ssh/authorized_keys /home/hadoop/authorized_keys_slave2
将这三个文件整合成一个文件
[hadoop@bogon ~]$ cat authorized_keys_master authorized_keys_slave1 authorized_keys_slave2 > authorized_keys
再将整合后的文件复制到三个容器中
[hadoop@bogon ~]$ docker cp /home/hadoop/authorized_keys hadoop1:/root/.ssh/authorized_keys
[hadoop@bogon ~]$ docker cp /home/hadoop/authorized_keys hadoop2:/root/.ssh/authorized_keys
[hadoop@bogon ~]$ docker cp /home/hadoop/authorized_keys hadoop3:/root/.ssh/authorized_keys
进入hadoop1查看一下
[hadoop@bogon ~]$ docker exec -it hadoop1 bash
bash-4.1# cat root/.ssh/authorized_keys

接下来为每个节点设置ip地址
进入容器后使用 ip addr 或者 ifconfig 命令查看ip地址
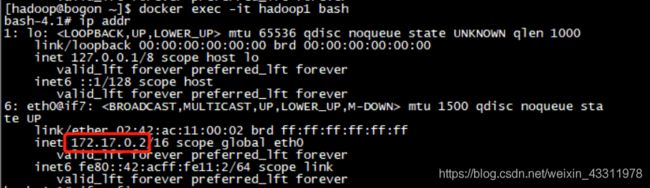
分别为三个容器设置ip地址
bash-4.1# vi /etc/hosts
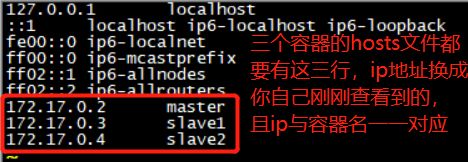
用 ssh 命令测试一下
bash-4.1# ssh master
bash-4.1# ssh slave1
bash-4.1# ssh slave2
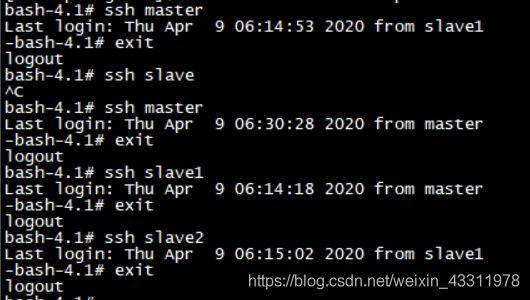
正常!
3、配置hadoop
这里hadoop容器很多都已经为我们配置好了
配置文件的目录一般是在 /usr/local/hadoop-2.7.0/etc/hadoop 下,如果路径不对的话就自己使用 find 命令查找一下
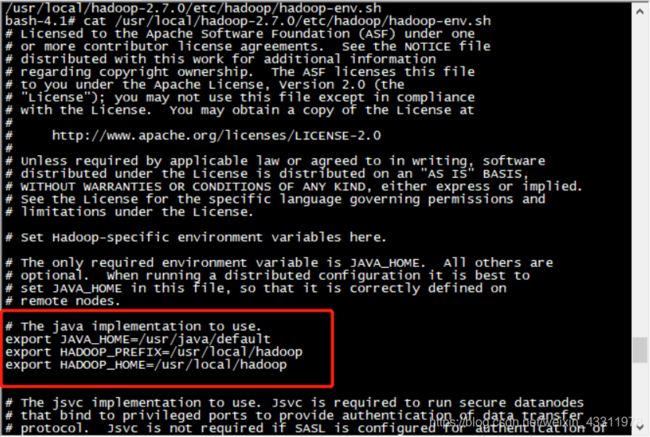
1)配置hadoop-env.sh和jdk
hadoop容器已为我们配好,不需要更改
bash-4.1# cat /usr/local/hadoop-2.7.0/etc/hadoop/hadoop-env.sh
2)配置core-site.xml
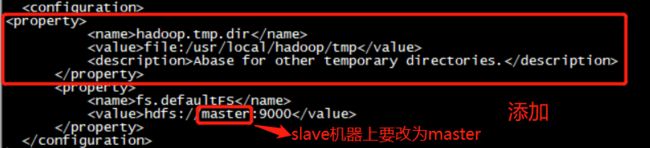
修改core-site.xml
bash-4.1# vi /usr/local/hadoop-2.7.0/etc/hadoop/core-site.xml
添加以下配置
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
3)配置hdfs-site.xml
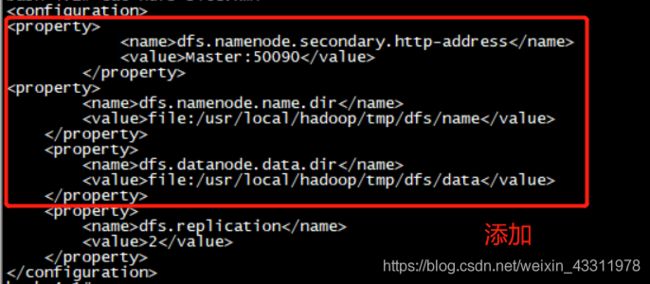
修改hdfs-site.xml
bash-4.1# vi /usr/local/hadoop-2.7.0/etc/hadoop/hdfs-site.xml
添加以下配置
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>Master:50090</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>
4)配置 mapred-site.xml
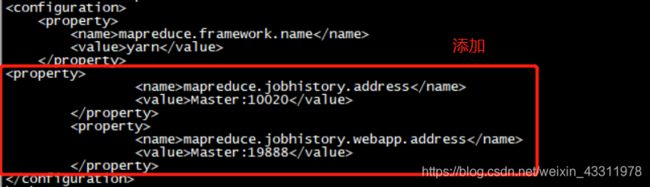
修改mapred-site.xml
bash-4.1# cat /usr/local/hadoop-2.7.0/etc/hadoop/mapred-site.xml
添加以下配置
<property>
<name>mapreduce.jobhistory.address</name>
<value>Master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>Master:19888</value>
</property>
5)配置yarn-site.xml
修改yarn-site.xml
bash-4.1# vi/usr/local/hadoop-2.7.0/etc/hadoop/yarn-site.xml
添加以下配置
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>

以上配置文件三台机都要修改且内容均一样!
6)修改slaves文件
bash-4.1# vi /usr/local/hadoop-2.7.0/etc/hadoop/slaves
将localhost替换成两个slave的主机名

OK!hadoop集群已配置完成,接下来启动集群
4、准备启动集群
1)格式化NameNode
首次启动需要先在 master 节点执行 NameNode 的格式化,之后不需要
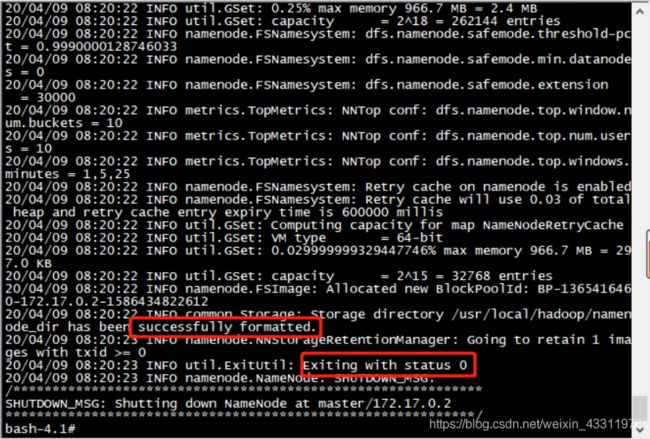
bash-4.1# /usr/local/hadoop/bin/hdfs namenode -format
成功的话,会看到 “successfully formatted” 和 “Exitting with status 0” 的提示,若为 “Exitting with status 1” 则是出错
2)启动集群
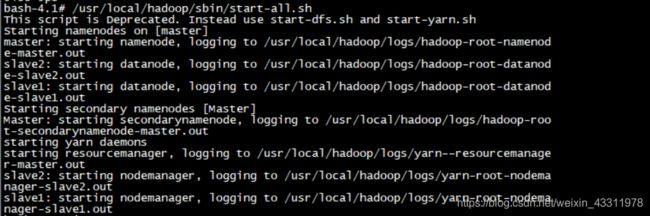
bash-4.1# /usr/local/hadoop/sbin/start-all.sh
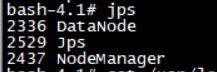
分别在master,slave1和slave2上用jps命令查看运行结果
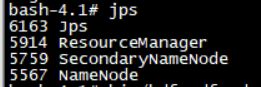
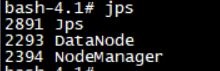
bash-4.1# jps
可以看到master上有ResourceManager,SecondaryNameNode和NameNode
两台slave机上有DataNode和NodeManager
在master上运行下面命令查看 DataNode 是否正常启动,如果 Live datanodes 不为 0 ,则说明集群启动成功
bash-4.1# /usr/local/hadoop/bin/hdfs dfsadmin -report
可以看到 Live datanodes 的数量为2
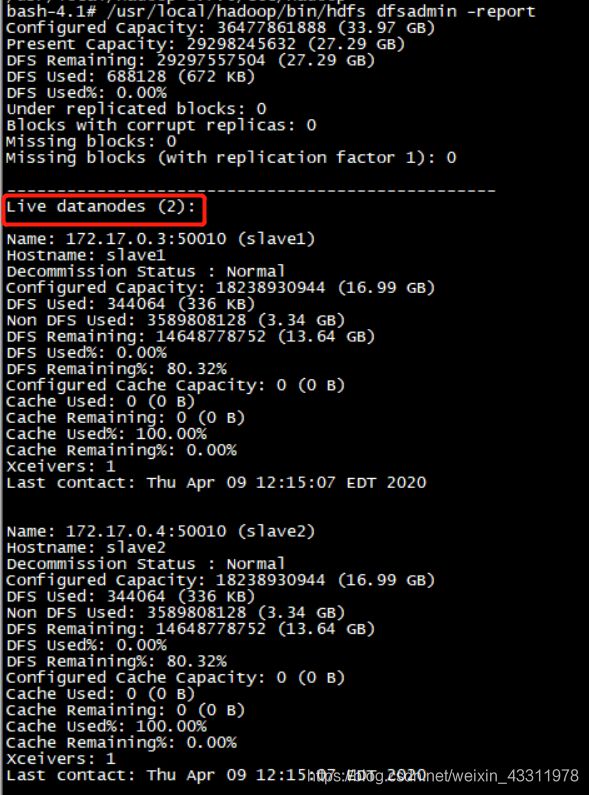
集群启动成功!
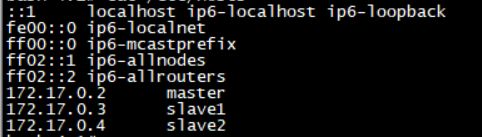
如果datanode启动失败,检查一下三台机的 /etc/hosts 文件,将第一行localhost 整行删掉,变成如下,再重新启动
如果还有问题,可以试着将所有节点的 /usr/local/hadoop/tmp 文件夹删除,再重新格式化NameNode,再重新启动
rm -r /usr/local/hadoop/tmp/
5、测试集群
执行实例,运行计算pi值程序
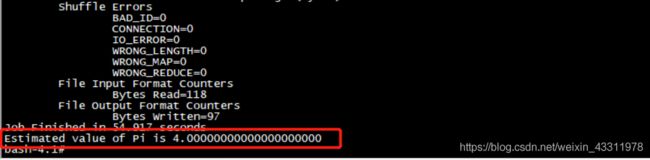
bash-4.1# /usr/local/hadoop/bin/hadoop jar /usr/local/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.0.jar pi 1 1
最后两个参数可以自己设置,我们这里只是测试集群,因此参数设置的较小,最后可以看到计算的pi值结果为4.0000000,集群正常工作!
在master上的 /etc/profile/ 文件中添加
export PATH=$PATH:/usr/local/hadoop/bin:/usr/local/hadoop/sbin
然后让更改生效
bash-4.1# source /etc/profile
即可在任何目录使用start-all.sh来启动集群
至此,已完成使用docker安装hadoop集群!