LDA(线性判别式分析)以及与PCA降维之间的区别
reference:
http://blog.csdn.net/warmyellow/article/details/5454943
首先说一下协方差矩阵, 之前大家肯定都学过,忘了的可以稍微看一眼:
LDA是多个类的之前的判别,一个类之间的数据我们可以用方差或者标准差,但是多个类之间显然不能再用var or std-var, 这时候就要用到cov.
协方差: cov(X, Y) = i(1...n) (Xi - X_mean)(Yi - Y_mean) / (n-1)
if cov(X, Y) > 0: X 与 Y 正相关;
if cov(X, Y) < 0: X 与 Y 负相关;
if cov(X, Y) = 0: X 与 Y 不相关, 即相互独立;
现在我们看一个三维的协方差矩阵,表示两两类之间的关系, 看一下应该就能明白了:
协方差矩阵C = [[cov(x, x), cov(y, x), cov(z, x)], [cov(x , y), cov(y, y), cov(z,y)}, [cov(x, z), cov(y, z), cov(z, z)]]
可以看出协方差矩阵是一个对角矩阵, 而对角线则是各个维度的方差。
NOTE: 注意是各个维度之间的关系,在具体给出的矩阵中,看每一行是一个维度的所有样本还是每个维度的一个样本,再确定是按列取还是按行取。
下面开始说一下LDA, 下图来源:https://www.zhihu.com/question/34305879/answer/80372053
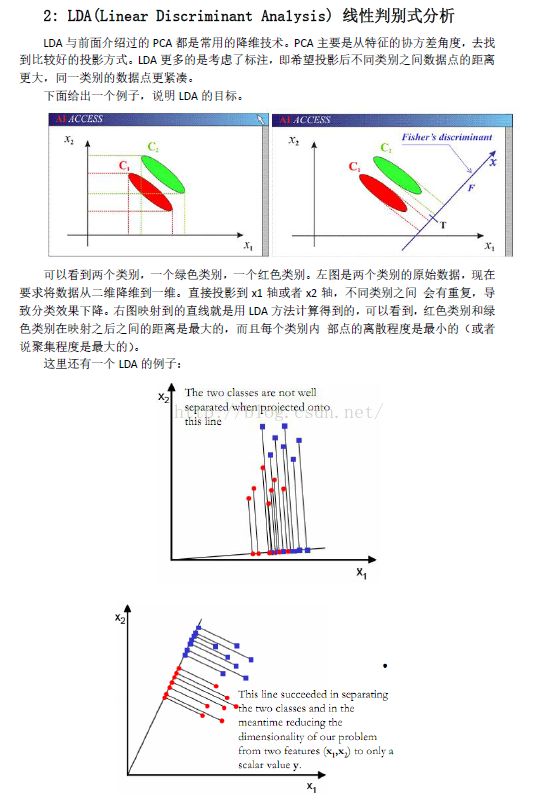
占坑
PCA算法: http://blog.csdn.net/xiaojidan2011/article/details/11595869 这个说的特别清楚,还可以补基础
占坑
区别:PCA是从特征的角度协方差角度: 求出协方差矩阵的特征值和特征向量,然后将特征向量按特征值的大小排序取出前K行组成矩阵P(这个P就是我们对角化协方差矩阵的时所使用的P, 具体的可以看看矩阵对角化的过程), 这个P就是一组正交变化基, 然后将原始的矩阵X,左乘P,也就是将X变换到P组成的正交基中,然后PX=Y就是降维后的矩阵。 而LDA则是在已知样本的类标注, 希望投影到新的基后使得不同的类别之间的数据点的距离更大,同一类别的数据点更紧凑。
当LDA作为一种信道补偿方法时,LDA试图找出一个新的方向能够最小化由信道效应产生的方差,同时最大化话者间的方差,使得变换后的特征减少信道信息(共性信息),增强话者信息(个性特征)。这一新方向必须满足最大化类间方差(Between-Class Variance)和最小化类内方差(Intra-Class Variance) 。
突然想起来,之前没写完存在草稿箱,今天逛知乎看到了,就再拿出来总结一下。