prometheus 企业监控常用函数,与简单的实际应用分析
prometheus 函数总结,附带一些实际应用
- 1、rate 函数
- 2、increase({}[time]) 增量函数
- 3、sum() 叠加函数
- 4、by () 拆分函数
- 5、topk() 函数
- 六、count() 函数
prometheus 函数官网:https://prometheus.io/docs/prometheus/latest/querying/functions/
1、rate 函数
rate 速率函数,prometheus 提供最重要的函数,只要碰上 counter 数据类型,直接套上 rate([m]) / increase([m])
rate() 是取一段时间增量的 平均每秒的增量数
rate( )专门配合 counter 类型数据使用的函数
它的功能是按照设置一个时间段,取 counter 这个时间段中的 平均每秒的增量。
例如:rate(node_network_receive_bytes[1m]) (用于监控主机上所有网卡每分钟的流量)
比如累积量从 440011229804456 --> 440011229805456,1分钟内增加了 1000bytes (假设)
比如累积量从 440011229805456 --> 440011229810456,5分钟之内增加了 5000 bytes(假设)
加入 rate(. [1m]) 之后,会把 1000bytes 除以1m =~ 16bytes
就是这样计算出在一分钟内,平均每秒增加 16bytes

同理 rate(.[5m]) ,会把 5000bytes 除以5m =~ 16bytes
也会同样计算出5分钟内,平均每秒增加 16bytes

rate(1m) 这样的取值方法 比起 rate(5m),因为它取得时间短,所以任何某一瞬间得突起或者降低会在成图得时候体现的更加细致、敏感。
而 rate(5m) 会把整个5分钟内得都一起平均了,当发生瞬间凸起得时候,会显得图平缓了一些 ( 因为取得时间段长 把波峰波谷 都给平均肖平了)
在工作当中,具体取 rate(1m) 还是 rate(5m) 决定于对监控数据得敏感程度来进行选择。
2、increase({}[time]) 增量函数
在prometheus 中,用来针对 Counter 这种持续增长的数值,截取其中一段时间的增量。配合时间使用
increase() 是 取一段时间增量的总量
例如:increase(node_network_receive_bytes_total{device=“ens33”}[1m])
获取了enss网卡在1分钟的增量总量
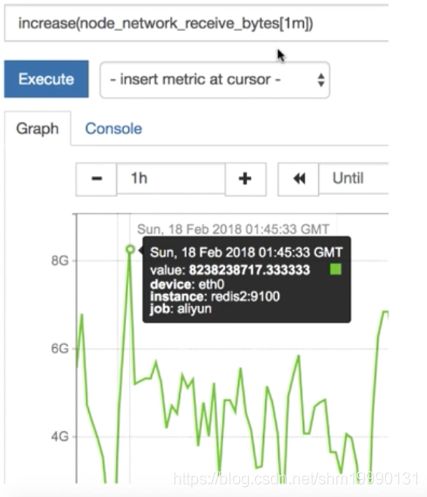
在企业监控实例时:
需要采集数据源,会牵扯到频率,如果采样频率比较粗糙,按照 5m 一次来取值,就比较适合用 increase() 函数
如果采样频率比较频繁,按照1m,秒级别采集数据 ( CPU / memory / disk / IO / netstat ) ,比较适合使用 rate() 函数。
3、sum() 叠加函数
可以将输出的内容进行合并,同by()一起使用才有意义
4、by () 拆分函数
by( ) 这个函数可以把 sum 合并到一起的数值,按照指定的方式进行拆分。( ) 内 填写它指定的方式
在当前案例,需要按照集群节点进行拆分。所以采用 instance=“机器名”,by(instance)。
by(cluster_name) 将服务器进行分组
例如:
用 sum() 提取了 20台 服务器的数据
其中 6台 属于 web_server ; 10台 属于 DB_server ; 4台 属于 nfs_server
这种时候就可以用 by(cluster_name) 实现集群分组,三条曲线进行输出
cluster_name这个标签,默认 node_exporter 是没有办法提供的, 需要自行定义
5、topk() 函数
定义:取前几位的最高值。格式:topk(number,key)

Gauge 类型的使用
topk(3,count_netstat_wait_connections)
Counter 类型的使用,必须加上 rate/increase 才有意义
topk(3,increase(node_cpu_seconds_total{mode=‘idle’}[1m]))
topk() 函数 ,在使用时,只适用于在 console 查看 graph 的意义不大。
如下图所示:
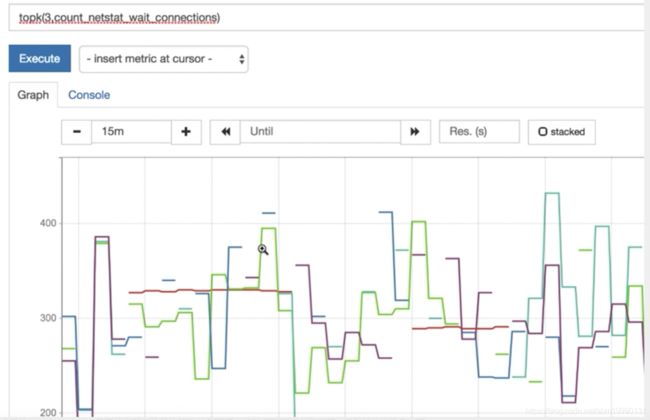
图形曲线都被截断了,因为对于每一个时间点来说,都只会取前三高的数值,那么必然会造成单个机器的采集数据不连贯。
实际使用的时候 ,一般用于 topk() 函数 进行瞬时报警,而不是为了观察曲线
六、count() 函数
定义:把数值符合条件的,输出数目进行加和
例:找出当前(或者历史)TCP 等待数大于200的 机器数量
count(count_netstat_wait_connections > 200)

实际应用:
一般用 count( ) 函数进行一些模糊的监控判断
比如说:企业中有100台服务器,那么当只有10台服务器 CPU 高于 80% 的时候,这个时候不需要报警,但是当符合 80% CPU 的服务器数量超过 30台 的时候,就会触发报警。