花书+吴恩达深度学习(二十)构建模型策略(超参数调试、监督预训练、无监督预训练)
目录
0. 前言
1. 学习率衰减
2. 调参策略
3. 贪心监督预训练
4. 贪心逐层无监督预训练
如果这篇文章对你有一点小小的帮助,请给个关注,点个赞喔~我会非常开心的~
花书+吴恩达深度学习(十八)迁移学习和多任务学习
花书+吴恩达深度学习(十九)构建模型策略(训练模型顺序、偏差方差、数据集划分、数据不匹配)
花书+吴恩达深度学习(二十)构建模型策略(超参数调试、监督预训练)
0. 前言
构建模型的策略:
- 观察损失函数,不断在此模型上调整参数,或增加优化算法
- 同时训练多个不同的模型,选择模型中较好的一个
有时先训练一个较简单的模型,然后使模型更复杂会更有效。
超参数是指在开始学习的时候设置的参数,而不是通过训练得到的参数。
调参的重要性,通常可以按照下面排列:
- 学习率
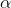
- 优化算法的
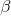 ,隐藏单元数量,mini-batch 大小
,隐藏单元数量,mini-batch 大小 - 神经网络层数
1. 学习率衰减
因为 MBGD 和 SGD 的波动特性,即使接近最小值,也在一个范围内波动,不会收敛。
如果随着迭代次数而减小学习率 ![]() ,就可使得梯度下降更接近最小值。
,就可使得梯度下降更接近最小值。
学习率 ![]() 可以每个 epoch 衰减一次,有多种衰减的方式:
可以每个 epoch 衰减一次,有多种衰减的方式:
![]()
![]()
![]()
![]()
2. 调参策略
如果只有时间调节一个超参数,那么就调节学习率。
各种超参数对模型的影响,如下图所示(图源:深度学习):

调参有多种策略。
坐标下降:固定一个或几个参数,调整另一个参数,处于最佳值后再交替的固定别的参数调整不同的参数。这种方法的问题是无法提前知道哪个参数比较重要,可能会导致很多无用的搜索。如果一个参数值很大程度影响另一个参数,那么就不是一个很好的方法。
网格搜索:当有 3 个或更少的超参数时,宜采用网格搜索,但是计算代价会随着超参数的数量呈指数型增长。
随机搜索:在参数的多维空间中,随机的搜索参数。当几个超参数对性能度量没有显著影响时,随机搜索指数级高效于网格搜索。
在参数的多维空间中,发现某一子空间的普遍效果比较好,则重点搜索这片子空间。
有时候搜索需要使用 ![]() ,例如对于一个参数的取值是 0.1,0.01,0.001,如果线性搜索,则大部分值都会较大。
,例如对于一个参数的取值是 0.1,0.01,0.001,如果线性搜索,则大部分值都会较大。
3. 贪心监督预训练
贪心算法将问题分解成许多部分,然后独立的在每个部分求解最优值。
贪心监督预训练是指,将监督学习问题分解成简化的监督学习问题,提高寻找到最优解的质量。
例如,先预训练一个浅层的神经网络,然后使用该网络的某一层,初始化为更深的网络,再继续训练。
其有助于更好的指导深层结构的中间层的学习,预训练对于优化和泛化都有帮助。
FitNets(Romero et al, 2015)方法,通过训练一个足够低足够宽的,容易训练的网络,作为教师网络。然后训练一个更深更窄的学生网络,更深更窄导致很难用 SGD 训练。学生网络不仅需要预测原任务的输出,还需要预测教师网络中间层的值,这样使得训练学生网络更加容易。
尽管一个窄而深的网络似乎比宽而浅的网络更难训练,但是窄而深的网络的泛化能力可能更好。
4. 贪心逐层无监督预训练
贪心逐层无监督预训练依赖于单层表示学习算法,每一层使用无监督学习预训练,将前一层的输出作为输入,输出数据的新的表示。
算法流程如下图所示(图源:深度学习):

被称为逐层的,是因为独立的解决方案是网络层。
被称为无监督的,是因为每一层用无监督表示学习算法训练。
被称为预训练的,是因为它只是在联合训练算法精调所有层之前的第一步。
贪心逐层无监督预训练结合了两种想法:
- 深度神经网络初始化参数的选择对其性能具有很强的正则化效果
- 学习算法可以使用无监督阶段学习的信息,在监督学习的阶段表现的更好
贪心逐层无监督预训练的优点是:预训练的网络越深,测试误差的均值和方差下降的越多。
贪心逐层无监督预训练的缺点是:有许多超参数,但其效果只能之后度量,难以提前预测。且两个单独的阶段都有各自的超参数,第二阶段的性能通常不能在第一阶段期间预测。
如果这篇文章对你有一点小小的帮助,请给个关注,点个赞喔~我会非常开心的~