大模型GUI系列论文阅读 DAY2续2:《使用指令微调基础模型的多模态网页导航》
摘要
自主网页导航的进展一直受到以下因素的阻碍:
- 依赖于数十亿次的探索性交互(通常采用在线强化学习),
- 依赖于特定领域的模型设计,难以利用丰富的跨领域数据进行泛化。
在本研究中,我们探讨了基于视觉-语言基础模型的数据驱动离线训练方法,以改进网页代理的性能。我们提出了一种名为 WebGUM 的指令跟随多模态代理,该代理能够同时观察网页截图和HTML 页面,并输出网页导航操作,例如点击和输入文本等。
WebGUM 通过联合微调一个指令微调的语言模型和一个视觉编码器进行训练,同时采用时间感知和局部感知,基于大量演示数据集实现学习。
实验结果表明,该方法显著提升了代理在以下方面的能力:
- 基于真实环境的多模态感知能力,
- HTML 理解能力,
- 多步推理能力。
与现有方法相比,WebGUM 在多个基准测试中取得了显著优势:
- 在 MiniWoB 基准测试中,我们相比之前最好的离线方法,性能提升了45.8% 以上,甚至超越了在线微调的 SoTA、真人以及基于 GPT-4 的代理。
- 在 WebShop 基准测试中,我们的 30 亿参数模型性能优于现有最先进模型 PaLM-540B。
- 在 Mind2Web 真实世界规划任务中,WebGUM 也表现出了强大的正迁移能力。
此外,我们使用训练好的模型收集了347,000 个高质量演示样本,规模是以往工作的38 倍,并公开这些数据以促进该领域的未来研究。
1 引言
网页导航是一类序列决策问题,其中代理根据用户指令与网页界面交互(Shi 等, 2017;Liu 等, 2018;Gur 等, 2019)。常见的网页导航任务包括:
- 表单填写(Diaz 等, 2013),
- 信息检索(Nogueira & Cho, 2016;Adolphs 等, 2022),
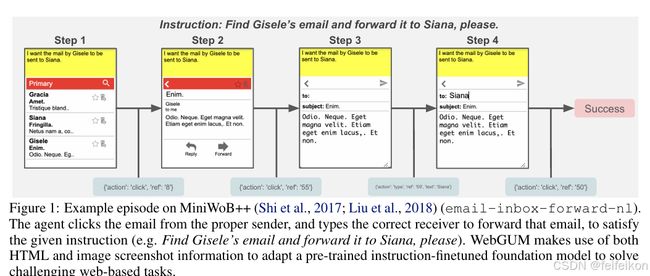
- 通过一系列点击或输入操作发送电子邮件(见图 1)。
近年来,越来越多的研究致力于开发自动化代理,以减少人类在这些重复交互中的工作量(Mazumder & Riva, 2020;Li 等, 2020;Shvo 等, 2021)。
现有研究的局限性
大多数现有研究将网页导航问题视为在线强化学习(RL),试图通过任务特定的模型从零开始学习最优的动作分布(Liu 等, 2018;Gur 等, 2019;Jia 等, 2019;Humphreys 等, 2022)。然而,在线强化学习面临诸多挑战:
- 需要进行大量的试错过程,在实际应用中往往不可行,
- 导航失败可能导致严重后果,例如:
- 错误输入密码可能导致账户冻结,
- 在商业场景中,错误发送邮件可能引发业务问题。
相较之下,基于静态数据集的离线训练为网页代理提供了安全的开发环境,但其性能往往低于在线强化学习的方法(Humphreys 等, 2022;Gur 等, 2022)。
此外,许多先前的研究无法充分利用丰富的跨领域数据来提高泛化能力。原因在于:
-
这些研究通常采用专门设计的模型来显式处理文档对象模型(DOM)的层次结构及其依赖关系,例如:
- 使用 LSTM 处理结构化数据(Gur 等, 2019;2021),
- 使用 自注意力机制(Self-Attention) 进行结构建模(Liu 等, 2018),
- 采用 图神经网络(GNN) 建模 DOM 依赖关系(Jia 等, 2019)。
-
许多方法仅输出一组固定的分类操作(如点击、输入等)(Humphreys 等, 2022),这在真实世界的开放式网页导航场景中并不理想,无法适应灵活多变的任务需求。
综上所述,本研究旨在探索新的方法,以克服当前网页导航领域的局限性,并提高代理在开放式网页环境中的泛化能力和安全性。
最近进展与本研究贡献
近年来,基础模型(Foundation Models)(Bommasani 等, 2021),特别是大语言模型(LLM)(Brown 等, 2020;Chowdhery 等, 2022)在常识推理、符号推理、算术推理和多步逻辑推理方面表现出卓越的性能(Wei 等, 2022b;c;Kojima 等, 2022)。
这些模型能够实现变革性的泛化能力,并可以在实际应用中解决多种交互式决策问题,包括但不限于:
- 机器人任务规划(Huang 等, 2022a;b;Shah 等, 2022;Ahn 等, 2022),
- 桌面游戏(Meta Fundamental AI Research Diplomacy Team 等, 2022),
- 网页检索和浏览器爬取(Nakano 等, 2021;Yao 等, 2022b;Zaheer 等, 2022)。
本研究方法
在本研究中,我们利用预训练的视觉-语言基础模型,提出了一种用于自主网页代理的高效离线学习方案。具体而言,我们的主要创新包括以下四个方面:
-
多模态感知的引入
- 我们假设,基于真实环境的空间理解对网页导航至关重要(Humphreys 等, 2022;Toyama 等, 2021)。
- 为此,我们将语言模型与视觉 Transformer(ViT)(Dosovitskiy 等, 2020)结合,形成具有局部和时序信息感知能力的语义丰富的多模态嵌入,使代理能够同时处理网页截图和 HTML 页面。
-
指令微调的语言模型
- 我们认为,网页导航本质上是指令跟随任务,因此采用指令微调的 LLM(Wei 等, 2022a;Chung 等, 2022;Ouyang 等, 2022;Iyer 等, 2022),而非像 Gur 等(2022)采用的自监督预训练模型(Raffel 等, 2020;Brown 等, 2020)。
-
大规模多模态数据集
- 我们收集了包含 HTML 和网页截图的大规模多模态数据集,用于对语言模型和 ViT 进行联合微调,以提高模型的泛化能力。
-
自由格式的文本输出
- 我们的模型以自由格式文本输出网页导航动作(例如点击、输入等),以提高操作的灵活性和适应性。
通过这四个关键要素,我们提出了基于真实环境理解模型的网页导航代理(Web navigation via Grounded Understanding Models, WebGUM)。
WebGUM 的工作流程
如图 1 所示,WebGUM 在网页任务中接收自然语言指令,例如:
"请在电子邮件客户端中查找 Gisele 的电子邮件,并将其转发给 Siana。"
模型通过多模态感知计算机界面(网页截图 + HTML 结构),并通过一系列计算机操作(如点击、输入)完成任务。
实验结果
-
MiniWoB++ 基准测试(Shi 等, 2017;Liu 等, 2018):
- 在此模拟网页导航环境下,WebGUM 在仅使用离线训练的情况下,性能较先前最优的基于 HTML 输入的离线方法(Gur 等, 2022)提高了45.8%,
- 甚至超越了在线强化学习(RL)方法(Humphreys 等, 2022)、人类,以及基于 GPT-4 的代理。
-
与人类和私有 LLM 代理对比(Kim 等, 2023;Sun 等, 2023):
- WebGUM 在多个基准测试上表现出色,证明其在多模态感知、HTML 理解、多步推理方面的优势。
WebGUM 的关键优势分析(详见第 5 节)
我们进行了深入的消融实验和分析,以验证 WebGUM 在以下方面的优势:
-
时序和局部多模态感知能力
- 结合视觉和 HTML,能够更好地理解网页的动态变化,例如航班预订(+50%)、形状识别(+22%)、社交媒体爬取(+21%)。
-
数据集和模型规模扩展能力
- 证明大规模数据集和更大的模型规模能显著提升性能。
-
更好的 HTML 理解能力
- 采用基于 HTML 结构的微调方法,使模型更适应复杂网页任务。
-
多步推理能力
- 使用指令微调的语言模型(如 Chung 等, 2022),与自监督预训练模型(如 Raffel 等, 2020)相比,MiniWoB++ 成功率提高了 25%。
- 特别是在处理任务的未知组合和跨分布 HTML 输入方面表现突出。
其他基准测试表现
-
WebShop 基准测试(Yao 等, 2022a)
- 结果表明,语言模型的多步推理能力使其优于现有的最先进模型,例如 PaLM-540B(Yao 等, 2022b;Chowdhery 等, 2022)。
- WebGUM 仅使用 30 亿参数,即可超越 PaLM-540B。
-
Mind2Web 基准测试
- WebGUM 在真实世界任务预测方面展现出良好的迁移能力,能够处理复杂的跨任务操作。
综上所述,WebGUM 通过多模态感知、HTML 理解和多步推理的结合,在网页自动化领域实现了显著突破,为未来更强大的自主网页代理奠定了基础。
GPT-4 及数据集贡献
最终,我们在 MiniWoB++ 上收集了 347,000 个多模态专家示范数据,比现有的单模态数据集(Liu 等, 2018)大 38 倍,并将其公开以促进未来研究【1】。
我们认为,利用基础模型(foundation models)进行高效的离线训练,是实现真实世界网页自动化的可扩展方案,尤其是在在线交互成本极高的情况下。
2 相关工作
网页导航
在自主网页导航领域,已经提出了多种基准测试(Toyama 等, 2021;Burns 等, 2022;Yao 等, 2022a),其中最具代表性和包容性的基准之一是 MiniWoB++(Shi 等, 2017;Liu 等, 2018)。
该基准测试由一组模拟网站组成,涉及从基础操作到复杂的多步决策任务,例如发送电子邮件或预订航班。
以往的研究尝试使用多种技术来解决该基准测试:
-
在线强化学习(RL)方法
- Liu 等(2018)和 Gur 等(2019;2021)使用高层工作流(Liu 等, 2018)或课程学习(curriculum learning)(Gur 等, 2019;2021)作为在线 RL 过程的指导。
- 但是,这些方法需要为每个任务单独设计,因此不具备可扩展性。
-
监督学习(SL)方法
- Humphreys 等(2022)采用大规模数据集进行监督学习,随后使用 RL 微调。
- Gur 等(2022)结合基于 LLM 的代理进行监督学习。
- 然而,离线监督学习代理通常表现不佳,而在线 RL 需要大量探索经验,虽然在网页导航中至关重要,但在真实网站上难以实施,因为通常没有奖励信号,且交互成本极高。
如附录 I 所示,许多现有方法依赖于基于任务的 DOM 层次结构(Jia 等, 2019;He 等, 2020),以及特定架构来编码依赖关系,例如:
- LSTM(Gur 等, 2019;2021),
- 自注意力机制(Self-Attention)(Liu 等, 2018),
- 图神经网络(GNN)(Jia 等, 2019)。
此外,现有方法往往使用基于任务的分类输出空间(Humphreys 等, 2022),这些方法无法处理真实世界中的开放式多任务场景,或无法充分利用预训练模型。
与此不同,我们提出了一种新的方法:
- 取消了这些特定于网页的架构,
- 将网页导航任务转化为**视觉问答(VQA)**问题,即 文本 + 图像 → 文本。
这种方法使我们能够充分利用预训练基础模型(如 Chung 等, 2022;Dosovitskiy 等, 2020),并即便通过离线训练也能学到强大的网页代理。
附录 B:额外的相关工作
在附录 B中,我们进一步探讨了关于多模态大规模模型和用于决策的基础模型的相关研究。
3 预备知识
我们将自主网页导航建模为确定性序列决策问题,其组成如下:
- 状态空间(State Space, S)
- 动作空间(Action Space, A)
- 确定性状态转移函数(Transition Function, T): T:S×A→ST: S \times A \rightarrow ST:S×A→S
- 指令空间(Instruction Space, G)
- 奖励函数(Reward Function, r)(或基于回合的成功标准): r:S×G×A→{0,1}r: S \times G \times A \rightarrow \{0,1\}r:S×G×A→{0,1}
在每个时间步 ttt,代理遵循基于先前状态和动作的参数化策略:
π:S×...×St×A×...×At×G→A\pi : S \times ... \times S_t \times A \times ... \times A_t \times G \rightarrow Aπ:S×...×St×A×...×At×G→A
并转换到下一个状态:
st+1=T(st,at)s_{t+1} = T(s_t, a_t)st+1=T(st,at)
该过程持续进行,直到代理达到终止状态(例如点击“提交”按钮)或超过最大时间步数。
如果代理满足给定的指令 ggg(即 r(st,g,at)=1r(s_t, g, a_t) = 1r(st,g,at)=1),则视为成功;如果执行无效操作或到达错误的终止状态,则视为失败。
在自主网页导航中,状态 st∈Ss_t \in Sst∈S 由以下两个部分组成:
- 网页的原始 HTML(作为文本序列输入),
- 网页截图(作为图像输入)。
遵循先前的研究(Shi 等, 2017;Liu 等, 2018;Gur 等, 2019;2021),我们假设受限的动作空间,其格式如下:
function(selector, text)\text{function(selector, text)}function(selector, text)
- function:包括
"click"或"type"操作, - selector:一个唯一标识网页元素的整数索引,
- text:当执行
type操作时的文本输入。
图 1 展示了 MiniWoB(Shi 等, 2017)环境中的一个示例回合,涉及多步决策过程。代理需要点击正确的发件人电子邮件,并输入正确的接收人地址以转发该电子邮件。MiniWoB 还包括基础的行为任务,如点击按钮或输入文本。
关于 WebShop(Yao 等, 2022a)基准测试的示例,请参阅附录 L。
4 WebGUM
4.1 具有时序和局部感知能力的多模态 Transformer 模型
在本研究中,我们借鉴 Gur 等(2022)的研究,使用 T5(Raffel 等, 2020)作为网页导航的基础架构。
- T5 采用编码-解码(encoder-decoder)架构,其双向编码能力非常适合 HTML 的树状结构,
- 该架构已被证明具有良好的扩展性,能够处理大型文本数据。
为了增强模型的多模态能力,我们将 T5 与 视觉 Transformer(ViT)(Dosovitskiy 等, 2020)结合,如图 2 所示。
具体而言:
-
视觉 Transformer(ViT)
- 预训练于 ImageNet-21K 分类任务(Deng 等, 2009),
- 将网页截图(图像观察)映射为图像令牌(image tokens)。
-
T5 编码器
- 统一处理视觉令牌和HTML 令牌,形成一个融合的多模态表示,
- T5 解码器则以文本形式预测网页操作(如“点击”或“输入”)。
有关更详细的实现细节,请参见附录 C。
编码时序和局部视觉令牌
为了让语言模型了解任务的时序信息和局部场景识别,编码器会从历史截图中提取多模态令牌(历史步数 H=2)。
- 时序视觉令牌:有助于在多步任务中预测一致的动作。
- 局部视觉令牌:为更好地提取网站局部区域的空间和语义信息,我们的 ViT 对每个图像块(patch)生成一个局部令牌,而不是对整张图像生成一个全局令牌(如 CLS-token)。
具体实现:
- 将输入图像划分为 16×1616 \times 1616×16 的图像块,得到 14×14(图像块数)×2(时序窗口)=39214 \times 14 \text{(图像块数)} \times 2 \text{(时序窗口)} = 39214×14(图像块数)×2(时序窗口)=392 个视觉令牌。
- 对 MiniWoB++ 的截图进行裁剪,去掉顶部的黄色指令部分,将图像尺寸调整为 160×160160 \times 160160×160。
- 使用白色像素填充裁剪后的图像,调整为 224×224224 \times 224224×224(ViT 默认输入大小)。
4.2 指令微调的大语言模型
我们基于 Flan-T5(Chung 等, 2022),一个经过指令微调的 T5,而不是像 Gur 等(2022)那样使用原始预训练的 T5。
- Flan-T5 通过大规模的指令跟随任务和多领域的链式推理示例(包括推理和编程任务)进行微调。
- 鉴于网页导航本质上是一个指令跟随任务,我们假设经过精心微调的指令模型能够很好地泛化,增强与用户指令的对齐能力,以及在网页导航和交互式决策中的零样本推理能力。
此外,这些高性能的指令微调模型可以提高样本效率和下游任务性能,非常适合离线学习。
我们进一步联合微调了 Flan-T5 语言模型和 ViT 视觉编码器(见图 2),使用大量指令跟随的多模态网页导航数据集进行训练(详见第 4.3 节)。
在第 5 节的实验中,我们实证表明,这种指令微调方法显著改善了 HTML 理解、多步推理和决策能力。
4.3 使用语言模型代理的大规模数据收集
基础模型的成功在很大程度上得益于互联网规模的数据(Brown 等, 2020;Radford 等, 2021;Chen 等, 2022;Wang 等, 2023)。尽管大量数据是关键,但在网页导航领域,公开数据集非常有限,例如 MiniWoB++ 只有 12K 个由人类演示的数据(Liu 等, 2018)。
- 此外,该数据集仅包含 DOM 观察结果,缺乏任何视觉特征,这限制了对网页元素精确空间感知的能力。
- 因此,需要一个包含网页截图在内的大规模多模态数据集,以构建更强大的导航策略。
为在 MiniWoB++ 上收集大规模的多模态行为数据集,我们使用了 Gur 等(2022) 提出的微调后的 LLM 策略,而不是依赖于人类演示者(Liu 等, 2018;Humphreys 等, 2022)。这种方法显著降低了构建新数据集的成本,同时利用了自主代理的成功经验。
具体过程:
- 初始数据生成
- 我们为每个任务运行 100 个回合的 LLM 策略,生成 2.8K 个成功的回合数据。
- 模型微调与扩展
- 使用这个小数据集微调 Flan-T5-XL 模型,并对每个任务运行 10,000 个回合。
- 额外示范数据收集
- 最后收集了额外的 54K 个演示数据。
这种方法结合了自主代理与大语言模型的能力,大大扩展了现有的多模态网页导航数据集规模。
与 Synapse 代理的结合与数据集扩展
我们将 WebGUM 与 Synapse(Zheng 等, 2023)相结合,后者是一种基于私有大语言模型(LLM)并依赖提示工程的代理,主要用于那些微调 LLM 无法很好完成的任务。
这一方法的努力最终构建了一个多任务数据集,包含 401K(347K + 54K) 个回合,每个步骤均包含 HTML 和网页截图。有关详细信息,请参阅附录 F。
5 结果
我们在 MiniWoB++(Shi 等, 2017;Liu 等, 2018)上对所提出的方法进行了测试,每个任务评估 100 个回合,最终结果取自 Gur 等(2022)提供的 56 个任务的平均成功率。
表 1 结果显示:
- WebGUM 在仅使用2.8K 数据集和Base 级别模型(310M 参数)的情况下,显著优于先前所有离线网页导航方法(Humphreys 等, 2022;Gur 等, 2022)。
- 相比之下,先前的方法使用了 240 万回合或30 亿参数,而 WebGUM 通过更高效的数据和参数利用,达到了更优越的离线性能。
这一成就得益于我们提出的网页导航问题简化,充分利用了时序-局部视觉感知和指令微调 LLM,在网页环境中提供了强大的归纳偏差。
此外,随着数据集和模型规模的扩展,WebGUM 达到了 94.2% 的成功率,相较于先前最优的离线模型 WebN-T5(Gur 等, 2022),提高了45.8%,甚至超过了在线 RL 微调的 SOTA 方法 CC-Net(Humphreys 等, 2022),超出 0.7%,尽管我们采用的是完全离线训练且数据量更少。
其他关键结果:
- WebGUM 的性能超越了人类以及最近的基于大语言模型的代理,例如 RCI(Kim 等, 2023)和 AdaPlanner(Sun 等, 2023),甚至在 GPT-4(OpenAI, 2023)的对比下依然表现优异。
- 任务级别的对比和错误分析(详见附录 G 和 L)表明,在需要记忆能力的复杂推理任务(如猜数字游戏)中,仍存在改进空间。
消融实验与改进来源分析
在接下来的部分,我们将对 WebGUM 进行广泛且精确的消融实验,以明确性能提升的来源。
我们重点关注以下方面:
-
时序与局部多模态感知能力(第 5.1 节)
- 研究架构、预训练模型对感知能力的贡献。
-
数据集与模型规模扩展(第 5.2 节)
- 分析如何扩大数据集和模型提高导航性能。
-
更好的 HTML 理解能力(第 5.3 节)
- 通过指令微调改进网页元素解析能力。
-
多步推理能力(第 5.4 节)
- 研究指令微调的 LLM 在复杂任务中的效果。
-
在真实世界任务中的可迁移性(第 5.5 节)
- 证明 WebGUM 能够推广到实际网页自动化任务。
5.1 时序与局部视觉感知在网页导航中的作用
为了验证图像模态的重要性,我们设计了以下三类消融实验:
-
输入替换(Input Replacement)
- 将真实图像观察替换为纯白图片,
- 或在测试时随机使用 MiniWoB++ 初始状态的截图。
-
去除视觉感知令牌(Removing Visual Tokens)
- 研究去除视觉输入对性能的影响。
-
不同预训练 ViT 模型的比较(Employing Different Pre-trained ViT)
- 采用多种预训练权重,包括:
- ImageNet-21K + AugReg(Steiner 等, 2022),
- JFT-300M(Sun 等, 2017),
- JFT-3B(Zhai 等, 2022)。
- 采用多种预训练权重,包括:
此外,我们评估了基于以下自监督学习目标的模型:
- CLIP(Radford 等, 2021),
- MAE(Masked Autoencoder)(He 等, 2021),
- DINO(Self-supervised Vision Representation)(Caron 等, 2021)。
在消融实验中,我们微调了Base 级别的模型,以作为更大规模模型的代理,以减少计算成本(Hoffmann 等, 2022)。
这些实验有助于识别 WebGUM 关键改进的来源,并提供有价值的见解,说明如何在网页导航任务中高效利用视觉感知和指令微调的 LLM。
视觉模态对模型性能的影响
在图 3(左)中,使用纯白图像的模型性能与单模态模型相当。这表明图像信息在某些情况下可能不是决定性因素。然而,当模型使用随机截取的网页截图时,性能略优于纯白图像的版本,可能是因为某些随机截图偶然包含了目标任务相关的图像信息。
这些结果证明,WebGUM 通过利用时序和局部视觉感知,成功获得了扎实的视觉和 HTML 理解能力。
在视觉令牌消融实验中,图 4(左)显示,同时结合时序和局部视觉令牌的模型(成功率 66.1%)比仅使用时序令牌(64.2%)或局部令牌(64.0%)的模型表现更好。
此外,与视觉令牌相比,不同预训练 ViT(视觉 Transformer)的影响较小,这进一步突出了我们在多模态网页导航架构设计方面的贡献。
在任务级别的分析中(图 3 右):
- 在多步任务(如“预订航班”任务,+50% 成功率提升)或需要视觉上下文理解的任务(如“点击形状”任务,+22% 成功率提升)中,WebGUM 通过视觉输入获得了显著改进(详见附录 G 和 L)。
5.2 数据集和模型规模的扩展效应
本节探讨 WebGUM 数据集和模型规模扩展的重要性,这与语言和视觉领域的研究观察一致(Shoeybi 等, 2019;Kaplan 等, 2020;Rae 等, 2021;Wei 等, 2022b;Chowdhery 等, 2022)。
实验过程:
- 我们准备了三种不同规模的数据集:
- 2.8K 个示范样本(最小数据集),
- 347K 个示范样本(完整数据集),
- **68K
5.4 交互式决策中的多步推理能力
WebGUM 仅使用 30 亿参数,但由于其一致的推理能力和对用户意图的增强对齐,能够在产品比较过程中进行回溯搜索,并选择最佳选项(详见附录 L)。
这些结果表明,Flan-T5 具备的多步推理能力在下游决策任务中可以作为强大且可迁移的先验知识。
5.5 强大的迁移能力:从模拟环境到真实世界的行动预测
我们进一步验证了 WebGUM 在真实世界问题中的适用性。
我们在 Mind2Web(Deng 等, 2023)上测试了 WebGUM,该数据集包含来自 137 个网站的大约 2000 条真实网页导航指令。
实验过程:
- 首先,使用在 MiniWoB++ 上微调的 WebGUM(训练于 401K 数据集)。
- 然后,在 Mind2Web 训练集上进行进一步微调,以适应真实世界任务。
在行动预测任务中,WebGUM 采用以下输入信息:
- 前 50 个最相关的 HTML 片段,
- 用户指令,
- 历史操作记录。
模型的输出包括:
- 目标元素 ID,
- 操作类型(如点击、输入),
- 操作值。
结果(见表 3):
- 迁移自 MiniWoB++ 的 WebGUM 在所有评估类别(跨任务、跨网站、跨领域)中,表现均优于 MindAct-Large/XL,甚至超越了 GPT-4。
- 由于 MindAct 和 WebGUM 均基于 Flan-T5,这些结果进一步支持了 WebGUM 在真实世界任务中的强迁移能力。
6 讨论与局限性
在本文中,我们提出了一种高效且实用的方法,将网页导航简化为离线训练,以充分利用指令微调 LLM 的网页环境归纳偏差。
尽管 WebGUM 在 Mind2Web 上表现出了良好的迁移能力,但我们仍需在未来的工作中扩展多模态基础模型,以实现真实世界网页导航的实际部署(Gur 等, 2023)。
当前工作局限性:
-
数据规模不足:
- 我们在 MiniWoB++ 上收集并发布了 347K 个多模态专家示范数据,尽管该数据规模已是此前的 38 倍,但仍远未达到支持通用模型所需的互联网规模数据。
- 未来工作应结合迭代数据收集和自动化部署(Ghosh 等, 2021;Matsushima 等, 2021;Li 等, 2022a),以推动更大规模的行为数据采集。
-
架构适应性:
- 由于我们的框架仅假设以原始 HTML 和截图作为输入,并以文本形式预测可解析的操作,因此可适用于更先进的 LLM或开放场景。
-
泛化能力:
- 虽然 WebGUM 可以在分布外(OOD)组合任务和扰动任务中展现鲁棒性,但实现真正的人类级泛化,以适应多样化的真实网站和复杂指令,仍是尚待解决的难题。
7 结论
我们提出了 WebGUM(Web navigation via Grounded Understanding Models),这是一种基于指令微调的视觉-语言基础模型,专为网页导航任务而设计。
主要成就:
- 在 MiniWoB++ 上,WebGUM 将先前离线训练 SOTA 的成功率从 48.4% 提升至 94.2%,实现了显著改进。
- 详细的消融实验表明,时序和局部视觉令牌能够捕获页面的动态转换和视觉上下文,
- 指令微调的语言模型显著提升了网页导航性能,主要体现在:
- 更强的 HTML 理解能力,
- 更优秀的多步推理能力。
多步推理能力使 WebGUM 在分布外任务中具有更强的泛化能力,并在 WebShop 上超越了 PaLM-540B。
WebGUM 还在 Mind2Web 的真实世界行动预测任务中展现了强大的正向迁移能力。
此外,我们将现有的 MiniWoB++ 数据集扩展至 347K 多模态专家示范数据,约为原始规模的 38 倍。
未来展望:
我们相信,WebGUM 是迈向更强大、可扩展的自主网页导航模型的重要一步。