SAC(Soft Actor-Critic)
Hi,这是第三篇算法简介呀
论文链接:Soft Actor-Critic:Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor,2018,ICML
文章概述
强化学习的两个主要挑战是高样本复杂性和收敛性脆弱。在这篇文章中,提出了一个基于最大熵框架的actor-critic离线策略的深度强化学习算法SAC(Soft Actor-Critic)。在DDPG中,policy和Q-value之间相互作用,使得其不稳定,容易受超参数影响。在SQL中,将actor网络作为近似采样器,而不是actor-critic算法中真正的actor,收敛取决于采样值和真实后验值的近似程度。
最大熵强化学习是将最大熵项加在reward上,其目的是鼓励探索环境,希望学到的策略在优化目标的同时尽可能地随机,同时保持在各个有希望的方向上的可能性,而不是很快收敛到一个局部最优。使用温度参数 α \alpha α来决定熵对reward的影响,当 α \alpha α趋近于0时,则reward退化为传统强化学习reward。
第一个在最大熵框架下,使用off-policy更新策略的算法。
总共包含四个网络:策略网络( ϕ \phi ϕ),value网络和对应的目标网络( ψ \psi ψ和 ψ ‾ \overline \psi ψ),Q-value网络( θ \theta θ)。
公式理解
J ( π ) = ∑ t = 0 T E ( s t , a t ) ∼ ρ π [ r ( s t , a t ) + α H ( π ( ⋅ ∣ s t ) ) ] J(\pi)=\sum_{t=0}^{T} \mathbb{E}_{\left(\mathbf{s}_{t}, \mathbf{a}_{t}\right) \sim \rho_{\pi}}\left[r\left(\mathbf{s}_{t}, \mathbf{a}_{t}\right)+\alpha \mathcal{H}\left(\pi\left(\cdot | \mathbf{s}_{t}\right)\right)\right] J(π)=t=0∑TE(st,at)∼ρπ[r(st,at)+αH(π(⋅∣st))]
T π Q ( s t , a t ) ≜ r ( s t , a t ) + γ E s t + 1 ∼ p [ V ( s t + 1 ) ] where V ( s t ) = E a t ∼ π [ Q ( s t , a t ) − log π ( a t ∣ s t ) ] \begin{array}{l}{\qquad \mathcal{T}^{\pi} Q\left(\mathbf{s}_{t}, \mathbf{a}_{t}\right) \triangleq r\left(\mathbf{s}_{t}, \mathbf{a}_{t}\right)+\gamma \mathbb{E}_{\mathbf{s}_{t+1} \sim p}\left[V\left(\mathbf{s}_{t+1}\right)\right]} \\ {\text { where }} \\ {\qquad V\left(\mathbf{s}_{t}\right)=\mathbb{E}_{\mathbf{a}_{t} \sim \pi}\left[Q\left(\mathbf{s}_{t}, \mathbf{a}_{t}\right)-\log \pi\left(\mathbf{a}_{t} | \mathbf{s}_{t}\right)\right]}\end{array} TπQ(st,at)≜r(st,at)+γEst+1∼p[V(st+1)] where V(st)=Eat∼π[Q(st,at)−logπ(at∣st)]
π new = arg min π ′ ∈ Π D K L ( π ′ ( ⋅ ∣ s t ) ∣ ∣ exp ( Q π old ( s t , ⋅ ) ) Z π old ( s t ) ) \pi_{\text {new }}=\arg \min _{\pi^{\prime} \in \Pi} \mathrm{D}_{\mathrm{KL}}\left(\pi^{\prime}\left(\cdot | \mathbf{s}_{t}\right)| | \frac{\exp \left(Q^{\pi_{\text {old }}}\left(\mathbf{s}_{t}, \cdot\right)\right)}{Z^{\pi_{\text {old }}}\left(\mathbf{s}_{t}\right)}\right) πnew =argπ′∈ΠminDKL(π′(⋅∣st)∣∣Zπold (st)exp(Qπold (st,⋅)))
J V ( ψ ) = E s t ∼ D [ 1 2 ( V ψ ( s t ) − E a t ∼ π ϕ [ Q θ ( s t , a t ) − log π ϕ ( a t ∣ s t ) ] ) 2 ] J_{V}(\psi)=\mathbb{E}_{\mathbf{s}_{t} \sim \mathcal{D}}\left[\frac{1}{2}\left(V_{\psi}\left(\mathbf{s}_{t}\right)-\mathbb{E}_{\mathbf{a}_{t} \sim \pi_{\phi}}\left[Q_{\theta}\left(\mathbf{s}_{t}, \mathbf{a}_{t}\right)-\log \pi_{\phi}\left(\mathbf{a}_{t} | \mathbf{s}_{t}\right)\right]\right)^{2}\right] JV(ψ)=Est∼D[21(Vψ(st)−Eat∼πϕ[Qθ(st,at)−logπϕ(at∣st)])2]
∇ ^ ψ J V ( ψ ) = ∇ ψ V ψ ( s t ) ( V ψ ( s t ) − Q θ ( s t , a t ) + log π ϕ ( a t ∣ s t ) ) \hat{\nabla}_{\psi} J_{V}(\psi)=\nabla_{\psi} V_{\psi}\left(\mathbf{s}_{t}\right)\left(V_{\psi}\left(\mathbf{s}_{t}\right)-Q_{\theta}\left(\mathbf{s}_{t}, \mathbf{a}_{t}\right)+\log \pi_{\phi}\left(\mathbf{a}_{t} | \mathbf{s}_{t}\right)\right) ∇^ψJV(ψ)=∇ψVψ(st)(Vψ(st)−Qθ(st,at)+logπϕ(at∣st))
J Q ( θ ) = E ( s t , a t ) ∼ D [ 1 2 ( Q θ ( s t , a t ) − Q ^ ( s t , a t ) ) 2 ] J_{Q}(\theta)=\mathbb{E}_{\left(\mathbf{s}_{t}, \mathbf{a}_{t}\right) \sim \mathcal{D}}\left[\frac{1}{2}\left(Q_{\theta}\left(\mathbf{s}_{t}, \mathbf{a}_{t}\right)-\hat{Q}\left(\mathbf{s}_{t}, \mathbf{a}_{t}\right)\right)^{2}\right] JQ(θ)=E(st,at)∼D[21(Qθ(st,at)−Q^(st,at))2] 其中, Q ^ ( s t , a t ) = r ( s t , a t ) + γ E s t + 1 ∼ p [ V ψ ‾ ( s t + 1 ) ] \hat{Q}\left(\mathbf{s}_{t}, \mathbf{a}_{t}\right)=r\left(\mathbf{s}_{t}, \mathbf{a}_{t}\right)+\gamma \mathbb{E}_{\mathbf{s}_{t+1} \sim p}\left[V_{\overline{\psi}}\left(\mathbf{s}_{t+1}\right)\right] Q^(st,at)=r(st,at)+γEst+1∼p[Vψ(st+1)]
J π ( ϕ ) = E s t ∼ D [ D K L ( π ϕ ( ⋅ ∣ s t ) ∥ exp ( Q θ ( s t , ⋅ ) ) Z θ ( s t ) ) ] J_{\pi}(\phi)=\mathbb{E}_{\mathbf{s}_{t} \sim \mathcal{D}}\left[\mathrm{D}_{\mathrm{KL}}\left(\pi_{\phi}\left(\cdot | \mathbf{s}_{t}\right) \| \frac{\exp \left(Q_{\theta}\left(\mathbf{s}_{t}, \cdot\right)\right)}{Z_{\theta}\left(\mathbf{s}_{t}\right)}\right)\right] Jπ(ϕ)=Est∼D[DKL(πϕ(⋅∣st)∥Zθ(st)exp(Qθ(st,⋅)))]
J π ( ϕ ) = E s t ∼ D , ϵ t ∼ N [ log π ϕ ( f ϕ ( ϵ t ; s t ) ∣ s t ) − Q θ ( s t , f ϕ ( ϵ t ; s t ) ) ] J_{\pi}(\phi)=\mathbb{E}_{\mathbf{s}_{t} \sim \mathcal{D}, \epsilon_{t} \sim \mathcal{N}}\left[\log \pi_{\phi}\left(f_{\phi}\left(\epsilon_{t} ; \mathbf{s}_{t}\right) | \mathbf{s}_{t}\right)-Q_{\theta}\left(\mathbf{s}_{t}, f_{\phi}\left(\epsilon_{t} ; \mathbf{s}_{t}\right)\right)\right] Jπ(ϕ)=Est∼D,ϵt∼N[logπϕ(fϕ(ϵt;st)∣st)−Qθ(st,fϕ(ϵt;st))]
∇ ^ ϕ J π ( ϕ ) = ∇ ϕ log π ϕ ( a t ∣ s t ) + ( ∇ a t log π ϕ ( a t ∣ s t ) − ∇ a t Q ( s t , a t ) ) ∇ ϕ f ϕ ( ϵ t ; s t ) \begin{array}{l}{\hat{\nabla}_{\phi} J_{\pi}(\phi)=\nabla_{\phi} \log \pi_{\phi}\left(\mathbf{a}_{t} | \mathbf{s}_{t}\right)+\left(\nabla_{\mathbf{a}_{t}} \log \pi_{\phi}\left(\mathbf{a}_{t} | \mathbf{s}_{t}\right)-\nabla_{\mathbf{a}_{t}} Q\left(\mathbf{s}_{t}, \mathbf{a}_{t}\right)\right) \nabla_{\phi} f_{\phi}(\epsilon_{t} ; \mathbf{s}_{t})}\end{array} ∇^ϕJπ(ϕ)=∇ϕlogπϕ(at∣st)+(∇atlogπϕ(at∣st)−∇atQ(st,at))∇ϕfϕ(ϵt;st)
伪代码分析

实验结果分析
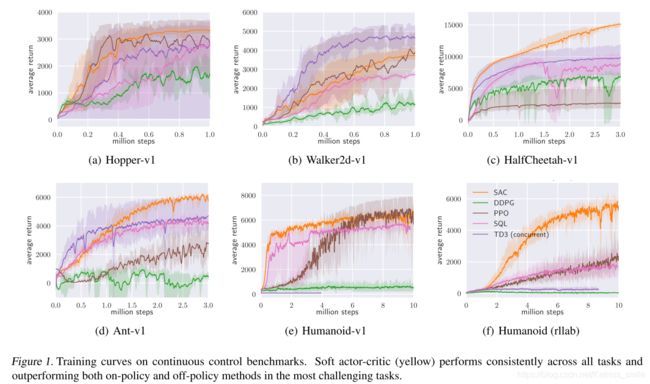
- 不同方法在不同场景下的平均reward
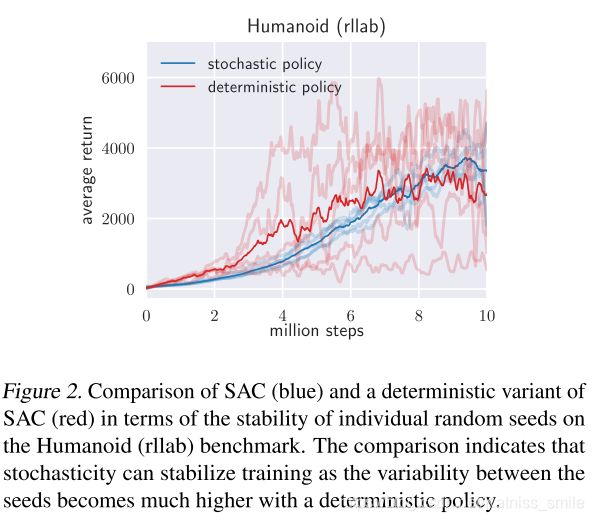
- 随机策略与确定性策略的稳定性对比
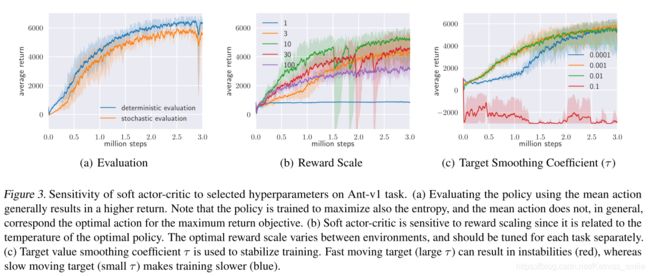
- 对所选超参数的敏感性