Scrapy框架爬虫项目:京东商城笔记本电脑信息爬取
一、创建Scrapy项目
在cmd中输入一下指令创建一个新的scrapy项目及一个爬虫
scrapy startproject JD_Goods
cd JD_Goods
scrapy genspider -t basic goods jd.com二、容器设置
在京东商城笔记本电脑分类下进入一个商品页面,在“”规格与包装”栏下可以看见该笔记本电脑的详细信息
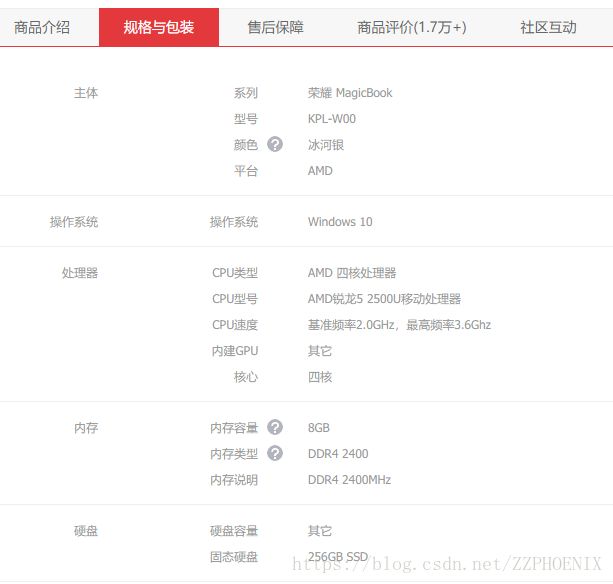
经过筛选,在items.py下设置下列容器(忽略我的Chinglish命名法...):
#商品名称
name = scrapy.Field()
#价格
price = scrapy.Field()
#链接
link = scrapy.Field()
#内存
internalStorage = scrapy.Field()
#CPU类型
cpuType = scrapy.Field()
#CPU型号
cpuModel = scrapy.Field()
#CPU速度
cpuSpeed = scrapy.Field()
#CPU核心
cpuCore = scrapy.Field()
#硬盘容量
diskCapacity = scrapy.Field()
#固态硬盘
SSD = scrapy.Field()
#显卡类型
GCtype = scrapy.Field()
#显示芯片
GCcore = scrapy.Field()
#显存容量
GCcapacity = scrapy.Field()
#尺寸
size = scrapy.Field()
#重量
weight = scrapy.Field()三、爬虫编写
整个项目写完后都用到了这些库,从头开始写的时候可以先一次性import完:
from JD_goods.items import JdGoodsItem
from scrapy.http import Request
import scrapy
import urllib.request
import urllib.error
import re
import json
import pymysql由于要得到笔记本电脑的详细信息需要进入每台笔记本电脑的单独的页面,所以我选择在第一次请求的时候将所有笔记本电脑的链接爬取到链表中。首先分析每一页的url规律,发现规律为:
url = "https://list.jd.com/list.html?cat=670,671,672&page=" + str(页码) + "&sort=sort_totalsales15_desc&trans=1&JL=6_0_0#J_main"然后分析页面中包含末尾页数的信息,用正则表达式提取:
def start_requests(self):
#TOTAL为总页数
url = "https://list.jd.com/list.html? cat=670,671,672&page=1&sort=sort_totalsales15_desc&trans=1&JL=6_0_0#J_main"
TOTAL = int(re.findall('共(.*?)',urllib.request.urlopen(url).read().decode('utf-8','ignore'))[0])
所以用以下代码将url链接存入list中:
self.links = []
for i in range(1, 21):
try:
url = "https://list.jd.com/list.html?cat=670,671,672&page=" + str(
i) + "&sort=sort_totalsales15_desc&trans=1&JL=6_0_0#J_main"
page = urllib.request.urlopen(url).read().decode('utf-8', 'ignore')
link_pattern = ''
if self.links is None:
self.links = re.findall(link_pattern, page)
else:
self.links = self.links.extend(re.findall(link_pattern, page))
print("第"+str(i)+"页处理完成")
except urllib.error.URLError as e:
if hasattr(e, 'code'):
print(e.code)
if hasattr(e, 'reason'):
print(e.reason)
i -= 1
continue
except Exception as e:
print(e)
i -= 1
continue发现提取出的商品url前都缺少了“https:”,二次处理:
for i in range(0,len(self.links)):
self.links[i] = 'https:' + self.links[i]由于之后每次爬取商品的信息时需要在self.links列表中调用不同index对应的url,这里设置一个全局变量index并设置为0,然后start_request方法就结束了:
global index
index = 0
yield Request(self.links[index],headers=ua)接下来码parse方法的代码:
首先实例化item对象
data = JdGoodsItem()然后分析各信息在网页源码中的位置并提取,注意此时link在star_request()中已经提取完了,这里调用index取出,并让index自增,由于xpath不方便提取所需要的标签内容,这里依然使用正则表达式
data['name'] = response.xpath('//img[@id="spec-img"]/@alt').extract()
data['link'] = self.links[index]
index += 1
page_content = urllib.request.urlopen(data['link']).read().decode('gbk','ignore')
pattern1 = '内存容量 .*?(.*?) '
pattern2 = '内存类型 .*?(.*?) '
result1 = re.findall(pattern1,page_content,re.S)
result2 = re.findall(pattern2,page_content,re.S)
if len(result1) > 0 and len(result2) > 0:
data['internalStorage'] = (result1[0]+' '+result2[0])
elif len(result1) > 0 and len(result2) == 0:
data['internalStorage'] = result1[0]
elif len(result2) > 0 and len(result1) == 0:
data['internalStorage'] = result2[0]
else:
data['internalStorage'] = ' '
pattern = 'CPU类型 (.*?) '
result = re.findall(pattern,page_content)
if len(result) > 0:
data['cpuType'] = result[0]
else:
data['cpuType'] = ' '
pattern = 'CPU型号 (.*?) '
result = re.findall(pattern, page_content)
if len(result) > 0:
data['cpuModel'] = result[0]
else:
data['cpuModel'] = ' '
pattern = 'CPU速度 (.*?) '
result = re.findall(pattern,page_content)
if len(result) > 0:
data['cpuSpeed'] = result[0]
else:
data['cpuSpeed'] = [' ']
pattern = '核心 (.*?) '
result = re.findall(pattern,page_content)
if len(result) > 0:
data['cpuCore'] = result[0]
else:
data['cpuCore'] = ' '
pattern = '硬盘容量 (.*?) '
result = re.findall(pattern,page_content)
if len(result) > 0:
data['diskCapacity'] = result[0]
else:
data['diskCapacity'] = ' '
pattern = '固态硬盘 (.*?) '
result = re.findall(pattern, page_content)
if len(result) > 0:
data['SSD'] = result[0]
else:
data['SSD'] = ' '
pattern = '类型 (.*?) '
result = re.findall(pattern, page_content)
if len(result) > 0:
data['GCtype'] = result[0]
else:
data['GCtype'] = ' '
pattern = '显示芯片 (.*?) '
result = re.findall(pattern, page_content)
if len(result) > 0:
data['GCcore'] = result[0]
else:
data['GCcore'] = ' '
pattern = '显存容量 (.*?) '
result = re.findall(pattern, page_content)
if len(result) > 0:
data['GCcapacity'] = result[0]
else:
data['GCcapacity'] = ' '
pattern = '尺寸 (.*?) '
result = re.findall(pattern, page_content)
if len(result) > 0:
data['size'] = result[0]
else:
data['size'] = ' '
pattern = '净重 (.*?) '
result = re.findall(pattern, page_content)
if len(result) > 0:
data['weight'] = result[0]
else:
data['weight'] = ' '(其实这里可以另外定义一个函数进行相应操作简化代码,后期有时间我会改进的)
在网页源码中无法找到价格信息,于是采用抓包分析,得到价格所在的json文件地址,然后提取:
#获取商品价格
good_id = re.findall('.*/(.*?).html',data['link'])[0]
price_url = 'https://p.3.cn/prices/mgets?&skuIds=J_' + good_id
content = urllib.request.urlopen(price_url).read()
print(price_url)
Json = json.loads(content)[0]
data['price'] = Json['p']最后,返回item对象并设置循环爬取:
yield data
for i in range(1,len(self.links)):
url = self.links[i]
yield Request(url, callback=self.parse)至此,爬虫文件的代码就码完了
四、写入Mysql
首先在settings.py中设置好相关信息,然后进入pipelines.py。为了在处理数据时实时反馈,再设置一个全局变量i,然后进行数据处理(我的机子在进行query() insert操作后数据库内还是空白的,于是进行手动commit)
class JdGoodsPipeline(object):
global i
i = 1
def process_item(self, item, spider):
database = pymysql.connect(host='127.0.0.1', user='root', password='Zwp0816...', db='JD_Goods')
# print("index" + str(i))
name = item['name'][0]
#print(name)
price = item['price']
#print(price)
internalStorage = item['internalStorage']
#print(internalStorage)
cpuType = item['cpuType']
# print(item['cpuType'])
cpuModel = item['cpuModel']
# print(item['cpuModel'])
cpuSpeed = item['cpuSpeed']
# print(item['cpuSpeed'])
cpuCore = item['cpuCore']
# print(item['cpuCore'])
diskCapacity = item['diskCapacity']
# print(item['diskCapacity'])
SSD = item['SSD']
# print(item['SSD'])
GCtype = item['GCtype']
# print(item['GCtype'])
GCcore = item['GCcore']
# print(item['GCcore'])
GCcapacity = item['GCcapacity']
# print(item['GCcapacity'])
size = item['size']
# print(item['size'])
weight = item['weight']
# print(item['weight'])
link = item['link']
sql = "insert into pcInfo values('" + name + "','" + price + "','" + internalStorage + "','" + cpuType + "','" + cpuModel + "','" + cpuSpeed + "','" + cpuCore + "','" + diskCapacity + "','" + SSD + "','" + GCtype + "','" + GCcore + "','" + GCcapacity + "','" + size + "','" + weight + "','" + link + "');"
#print(1)
database.query(sql)
commit = "commit;"
#print(2)
database.query(commit)
global i
print("第" + str(i) + "个商品处理完成")
i = i+1
database.close()
return item
五、后续问题
问题1:在处理json文件获取price的操作次数多了之后会返回 {"error":"pdos_captcha"},因此获取price的方法需要改进。
解决办法:在pduid值后添加100000-999999的随机值
后续跟进:使用上述方法爬取一段时间后还是会返回 {"error":"pdos_captcha"},只能用动态页面渲染的方法了。后续会给出相应代码。
更新:已写出利用动态渲染获取价格和评论数的方法,请移步 利用动态渲染页面对京东笔记本电脑信息爬取
import random
price_url = 'https://p.3.cn/prices/mgets?pduid=' + str(random.randint(100000, 999999)) + '&skuIds=J_' + good_id+ '&ext=11100000&source=item-pc'