百度七天强化学习 心得体会
本人强化学习小白,参加了百度7天强化学习打卡营
1. 第一天:熟悉paddlepaddle, parl和机器学习、深度学习基础
我之前做深度学习,有一定基础。第一天作业是配置相应环境,pip 安装用百度源 -i https://mirror.baidu.com/pypi/simple 速度非常快,git clone使用码云链接替换github链接速度快不少
2. 第二天:学习Sarsa 和Q learning算法
先回顾下RL的一些基础概念:
状态state, 动作action, 奖励reward:
智能体agent在环境env 状态s下执行动作a得到环境的反馈r
状态转移函数Transition
![]() ,
,
根据当前状态 s 和动作 a 预测下一个状态 s’,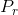 表示从 状态s 采取动作a 转移到状态 s’ 的概率
表示从 状态s 采取动作a 转移到状态 s’ 的概率
策略policy
策略即为智能体agent在状态下执行动作的根据,用 表示
表示
状态值函数
![]()
其中 为折扣因子,值函数用来评估智能体在该时间步状态的好坏程度,是对未来奖励的预测,折扣因子也可称为未来折扣因子,对未来的奖励乘以折扣因子,说明更注重于当下的奖励,折扣一般取值范围在0到1
为折扣因子,值函数用来评估智能体在该时间步状态的好坏程度,是对未来奖励的预测,折扣因子也可称为未来折扣因子,对未来的奖励乘以折扣因子,说明更注重于当下的奖励,折扣一般取值范围在0到1
时间差分控制Sarsa算法
时间差分控制主要分为固定策略和非固定策略两种,Sarsa算法属于固定策略
原理:Sarsa算法估计的是动作值函数q(s, a), 即估计在策略下对于任意状态s上所有可能执行动作a的动作值函数
每一次算法更新都需要5个变量 :当前状态s,当前动作a,获得奖励r,下一时间步状态s‘,下一时间步动作a’,Sarsa算法名称因此得来
![]()
Q learning
Q learning算法是一种非固定策略算法,其在动作值函数q(s,a)的更新中,采用的是不同于选择动作时遵循的策略
![]()
时间差分目标使用动作值函数的最大值![]() 并于当前选取动作使用的策略无关,Q-learning选取的动作值Q往往是最优的。
并于当前选取动作使用的策略无关,Q-learning选取的动作值Q往往是最优的。
3. 第三天:学习DQN 玩小车爬坡游戏
DQN是用神经网络来建模Q函数,即用神经网络模型代替Q-learning中的q函数
其有2个创新点是1. 使用经验回放机制,解决样本相关性问题 2. 使用target model 来稳地神经网络的输出,来使Q值预测稳地
每隔一定的训练步数,就会将predict model的参数服知道target model中,使用target model的输出值作为目标Q值
4. 第四天:Policy Gradient 策略梯度法处理乒乓球游戏
策略梯度法将策略的学习从概率集合![]() 变换成策略
变换成策略![]() , 并通过求解策略目标函数的极大值,得到最优策略
, 并通过求解策略目标函数的极大值,得到最优策略![]()
使用神经网络来建模策略
将策略的目标函数设为智能体关于奖励的期望,用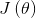 表示。并采用策略梯度法求解目标函数的梯度,进而学习出策略网络参数
表示。并采用策略梯度法求解目标函数的梯度,进而学习出策略网络参数 . 为了使求解的梯度最大(奖励最大化的期望),使用梯度上升算法更新目标函数的策略参数
. 为了使求解的梯度最大(奖励最大化的期望),使用梯度上升算法更新目标函数的策略参数
![]()
在实现demo项目中,会发现比前几天的作业都要难一点,而且训练时间要更长
5. 第五天:DDPG算法控制四轴飞行器悬停
这一节的作业就难多了。
DDPG 全程 Deep Deterministic Policy Gradient, 其使用演员-评论家算法,融合DQN的优势,很好地解决了算法收敛难得问题
演员-评论家策略梯度结合了值函数近似的求解思路,具体分为两部分:演员(Actor)和评论家(Critic),演员负责更新策略,评论家负责更新动作值函数:
演员和评论家均使用神经网络来拟合。演员基于概率选择动作,评论家基于演员选择的动作评价该动作并给出评分,演员根据评论家的评分修改后续选择动作的概率。演员选择动作后,其余步骤与通用的强化学习框架类似,环境执行智能体选择的动作,并输出奖励和状态给智能体。
策略网络代表演员,输入为状态,输出为动作;价值网络代表评论家,用于评价演员选取的动作的好坏,并生成时间差分误差信号指导演员的更新。
对于四轴飞行器的控制任务,我使用的策略网络和价值网络均包含2层隐层全连接,由于四轴4电机电压接近更利于四轴平稳悬停,我对ddpg算法的学习进行了修改,输出的四维action,先对其排序和求均值,对中间2个值使用均值代替,最大值和最小值分别与均值加权,在本地显卡跑到9800分