influxdb内存中Cache数据结构详解
引:
前面TSM文件格式解析(一到四)综合分析了不同case下的TSM文件格式,文件格式已基本清楚。
写入磁盘是如此格式,那在写入磁盘之前的内存中是怎么存储的呢?
通过第一篇influxdb初探https://blog.csdn.net/jacicson1987/article/details/81986234,了解到内存中的数据是存储在
DBStore中的某个shard里,
每个shard有一个tsm engine
每一个tsm engine里面有一个Cache
结构说明
type Cache struct {
// Due to a bug in atomic size needs to be the first word in the struct, as
// that's the only place where you're guaranteed to be 64-bit aligned on a
// 32 bit system. See: https://golang.org/pkg/sync/atomic/#pkg-note-BUG
size uint64
snapshotSize uint64
mu sync.RWMutex
store storer
maxSize uint64
// snapshots are the cache objects that are currently being written to tsm files
// they're kept in memory while flushing so they can be queried along with the cache.
// they are read only and should never be modified
snapshot *Cache
snapshotting bool
// This number is the number of pending or failed WriteSnaphot attempts since the last successful one.
snapshotAttempts int
stats *CacheStatistics
lastSnapshot time.Time
lastWriteTime time.Time
// A one time synchronization used to initial the cache with a store. Since the store can allocate a
// a large amount memory across shards, we lazily create it.
initialize atomic.Value
initializedCount uint32
}
Cache里面有一个store
数据就是存在这个store里面。
Cache里面还有一个snapshot, 定时把store里的数据复制到snapshot.store里,然后store清空。
然后再把snapshot.store里的内容写入文件。
那这个store里到底是什么结构呢?
store被初始化成一个含有16个partitions(节点)的ring。这个ring我称之为伪一致性哈希,因为它并没有成环。
func (c *Cache) init() {
if !atomic.CompareAndSwapUint32(&c.initializedCount, 0, 1) {
return
}
c.mu.Lock()
c.store, _ = newring(ringShards) // ringShards = 16
c.mu.Unlock()
}每一个partition都初始化成一个map,key是string, value是一个数组
func newring(n int) (*ring, error) {
if n <= 0 || n > partitions {
return nil, fmt.Errorf("invalid number of paritions: %d", n)
}
r := ring{
partitions: make([]*partition, n), // maximum number of partitions.
}
// The trick here is to map N partitions to all points on the continuum,
// such that the first eight bits of a given hash will map directly to one
// of the N partitions.
for i := 0; i < len(r.partitions); i++ {
r.partitions[i] = &partition{
store: make(map[string]*entry),
}
}
return &r, nil
}通过跟踪发现,这个map的key就是和TSM文件结构里面的key一致:measurement,tags#!~#field
而这个entry呢,是一组data,每个data由timestamp和value 两个部分构成。
type FloatValue struct {
unixnano int64
value float64
}
type StringValue struct {
unixnano int64
value string
}那key是怎么映射到具体某个partition的呢
// getPartition retrieves the hash ring partition associated with the provided
// key.
func (r *ring) getPartition(key []byte) *partition {
return r.partitions[int(xxhash.Sum64(key)%partitions)]
}xxhash.sum64,再与partition的数量(16)求余,得到下标,找到partition.
具体xxhash.sum64这个哈希值怎么计算的呢,以后在研究。
结构图
现在已经知道了Cache中数据的存储方式了,来张表更清楚一点
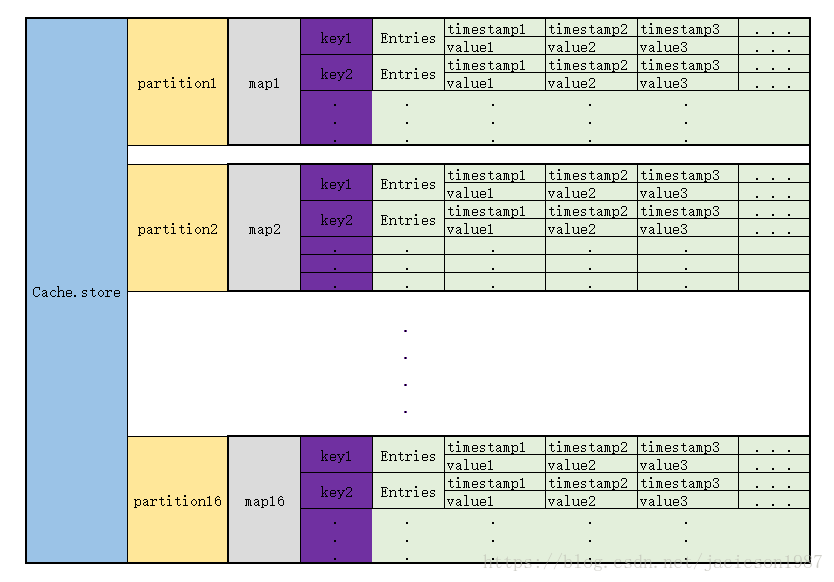
每次写入同一个key的数据,那就找到其Entries, 把新的数据直接append到后面。
排序与去重
这样就又有问题了,如果 timestamp旧的数据后来,那这一组数据的就不是按照timestamp的大小顺序了。
这里怎么解决的呢,这里并没有解决,不管是来的更旧的timestamp的数据 还是duplicated数据,统统加后面。
去重和排序在两个地方做
1. select xx from xx的时候
2. snapshot写入TSM文件的时候
这个去重和排序代码如下, 先检查顺序,需要的话就sort..最后检查去重。
这个sort算法有时间可以看看,应该是针对大部分都是按顺序的情况下效率可以的排序。
// Deduplicate returns a new slice with any values that have the same timestamp removed.
// The Value that appears last in the slice is the one that is kept. The returned
// Values are sorted if necessary.
func (a Values) Deduplicate() Values {
if len(a) <= 1 {
return a
}
// See if we're already sorted and deduped
var needSort bool
for i := 1; i < len(a); i++ {
if a[i-1].UnixNano() >= a[i].UnixNano() {
needSort = true
break
}
}
if !needSort {
return a
}
sort.Stable(a)
var i int
for j := 1; j < len(a); j++ {
v := a[j]
if v.UnixNano() != a[i].UnixNano() {
i++
}
a[i] = v
}
return a[:i+1]
}
小结:
由下至上,了解到写入TSM文件之前,数据在Cache中的存储方式。
具体的查询和写入的逻辑这里只涉及了一点点,其他的大部分包括如何分shard, 如何通过制定时间段获得数据,如何索引到TSM文件indexes等等还需要再研究。