Java web基础总结一之—— xml基础
Java web基础总结之一——xml基础
要学习java web,掌握xml语言是必要的,可以说,在一个java web项目中,xml配置文件无处不在。首先每个java web项目都会有一个web.xml的配置文件。而在各种各样的框架中,xml配置文件更是必不可少。当然,虽然有些框架可以使用注解来实现零配置。但是一般还是习惯于使用配置文件,可以和代码解耦和。
一.Xml基础知识以及语法规范
那首先的问题是,什么是xml?它主要用来做什么?
Xml是Extensible Markup Language的缩写,就是可扩展标记语言。W3C组织于2000发布了XML1.0规范。当时据说是为了替代html语言,现在看来是没有实现。
XML语言的作用是描述有关系的数据。在XML语言中,它允许用户自定义标签。一个标签用于描述一段数据;一个标签可分为开始标签和结束标签,在开始标签和结束标签之间,又可以使用其它标签描述其它数据,以此来实现数据关系的描述。比如:
<大学专业>
<文科>
<历史>
<法律>
<理科>
<化学>
<物理>
下面了解一下xml的语法
一个完整的xml文件会包括以下几个部分:文档声明 ,元素,属性,注释 ,CDATA及转义字符 ,处理指令。
1. 文档声明
在编写XML文档时,最开头要进行文档声明,声明XML文档的类型,下面是两个例子。
最简单的声明语法:
用encoding属性说明文档的字符编码:
2. 元素
XML元素指XML文件中出现的标签,一个标签分为开始标签和结束标签,一个标签有如下几种书写形式,例如:
包含标签体:<大学专业> xx
不含标签体的:<大学专业> , 可以简写为:<大学专业/>
元素的语法规范
XML的合法的元素可以包含字母、数字以及其它一些可见字符,但必须遵守下面的一些规范:大小写敏感的,例如,和是完全不一样的。不能以数字或"_" (下划线)开头。不能以xml(或XML、或Xml 等)开头。不能包含空格。而且中间不能包含冒号。
*有几个需要注意的问题:
(1).一个标签中也可以嵌套若干子标签。绝对不能交叉嵌套,比如:
<历史>aa<物理>xx
(2).通常XML文档必须有且仅有一个根标签,其它标签都是这个根标签的子孙标签。
(3).和java代码不同的是,对于XML标签中出现的所有空格和换行,XML解析程序都会当作标签内容进行处理。举个例子,下面的两个完全不同。
例1:
<大学专业> xx
例2:
<大学专业> xx
3. 属性
一个标签可以有一个或者多个的属性,属性有名字和值,例如:
在XML中,标签属性所代表的信息,也可以被改成用子元素的形式来描述,例如:
< import>
< resource > spring-dao.xml
同时也要注意一些细节,属性值必须要用双引号(")或单引号(')引起来,属性的命名规范和标签一样。
4. 注释
Xml中也可以写一些注释,文件中的注释的格式是:“”。需要注意几个细节,一个是注释不能有嵌套,还有就是和java代码不一样的是,注释不能写在开头,即在xml声明的前面。
5. CDATA区域和转义字符
当我们编写XML文件时,可能会有这种需求,就是有些内容不想让解析引擎解析执行,而是当作原始内容处理,这时可以有两种情况。
(1). 对于任意的字符,可以使用CDATA区,对于CDATA区域内的内容,XML解析程序不会处理,而是直接输出,不做任何的解析。语法是:
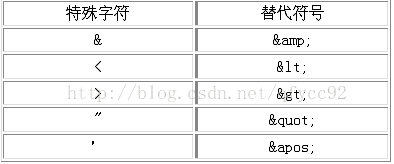
(2). 对于一些单个字符,由于是xml中的有意义的字符,若想显示其原始样式,就可以使用转义的形式予以处理。下面是常见的转义字符表:
6. 处理指令
处理指令,简称PI (processinginstruction)。处理指令用来指挥解析引擎如何解析XML文档内容。处理指令必须以“”作为结尾,XML声明语句就是最常见的一种处理指令。
二.XML的约束
所谓的xml约束,就是约束一个XML文档的书写规范的一个约束文档,这称之为XML约束。例如spring中的约束文件:
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans-3.1.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context-3.1.xsd"
常见的有XML DTD 和XML Schema两种约束
1. XML DTD约束
DTD(Document Type Definition),全称为文档类型定义。使用一个以 .dtd 为后缀的约束文件。DTD约束即可以作为一个单独的文件编写,也可以在XML文件内编写。具体的语法这里就不详细讨论了。
2. XML Schema约束
XML Schema 是另一种用于定义和描述 XML 文档结构与内容的模式语言,其出现是为了克服 DTD 的局限性。Schema约束与dtd约束最大的区别在于Schema约束文档本身也是一个符合xml语法的xml文件。它的功能更强大,更复杂,现在已是w3c组织的标准,它正逐步取代DTD成为标准的xml约束,常见的是以.xsd为后缀的文件,如上面例子中的spring的约束文件。
三.XML文件的解析
Java中有很多的第三方的解析xml文件的类库,可以避免我们重复造轮子,而去直接使用。
XML解析方式分为两种:dom和sax。dom:(Document Object Model, 即文档对象模型) 是 W3C 组织推荐的处理 XML 的一种方式。sax: (Simple APIfor XML) 不是官方标准,但它是 XML 社区事实上的标准,几乎所有的 XML 解析器都支持它。XML解析器(apache)主要有:Crimson(sun1.4)、Xerces(IBM 1.5) 、Aelfred2(DOM4J)。XML解析开发包(对解析封装后开发的API)主要有Jaxp(使用Crimson(sun1.4)、Xerces(IBM 1.5) )、Jdom、Dom4j(Aelfred2(DOM4J))。
DOM解析和SAX解析的区别是在使用 DOM 解析 XML 文档时,需要读取整个 XML 文档,在内存中构架代表整个 DOM 树的Doucment对象,从而再对XML文档进行操作。此种情况下,如果 XML 文档特别大,就会消耗计算机的大量内存,并且容易导致内存溢出。
SAX解析允许在读取文档的时候,即对文档进行处理,而不必等到整个文档装载完才会文档进行操作。所以相对更加的灵活。对于xml解析的具体操作,可以查看相应的xml解析器的API文档进行学习。这篇文章只是简单的介绍,就不多说了。