k8s架构及服务详解
9.deployment:声明式的升级应用
9.1.使用RC实现滚动升级
#kubectl rolling-update kubia-v1 kubia-v2 --image=luksa/kubia:v2
使用kubia-v2版本应用来替换运行着kubia-v1的RC,将新的复制控制器命名为kubia-v2,并使用luksa/kubia:v2最为镜像。
升级完成后使kubectl describe rc kubia-v2查看升级后的状态。
为什么现在不再使用rolling-update?
1.直接更新pod和RC的标签并不是一个很的方案;
2.kubectl只是执行升级中的客户端,但如果执行kubectl过程中是去了网络连接,升级将会被中断,pod和RC将会处于一个中间的状态,所以才有了Deployment资源的引入。
9.2.使用Deployment声明式的升级应用
Rs替代Rc来复制个管理pod。
创建Deployment前确保删除所有的RC和pod,但是暂时保留Service,
kubectl delete rc --all
创建Deployment
#kubectl create -f kubectl.depl-v1.yaml --record //--record可以记录历史版本
#查看Deployment的相关信息
#kubectl get deployment
#kubectl describe deployment
#查看部署状态:
#kubectl rollout status deployment kubia
9.3.触发deployment升级
#kubectl edit deployment kubia //修改完后资源对象会被更新
#kubectl patch deployment kubia -p '{...}' //只能包含想要更新的字段
#kubectl apply -f kubia-deploy-v2.yml //如果yml中定义的资源不存在,会自动被创建
#kubectl replace -f kubia-deploy-v2.yml //如果yml中定义的资源不存在,则会报错修改configmap并不会触发升级,如果想要触发,可以创建新的configmap并修改pod模板引用新的configmap。
9.4.回滚deployment
在上述升级deployment过程中可以使用如下命令来观察升级的过程
#kubectl rollout status deployment kubia如果出现报错,如何进行停止?可以使用如下命令进行回滚到先前部署的版本
#kubectl rollout undo deployment kubia如何显示deployment的历史版本?
#kubectl rollout history deployment kubia如何回滚到特定的版本?
#kubectl rollout undo deployment kubia --to-revision=1
9.5.控制滚动升级的速率
在deployment的滚动升级过程中,有两个属性决定一次替换多少个pod:maxSurge、maxUnavailable,可以通过strategy字段下的rollingUpdate的属性来配置,
maxSurge:决定期望的副本数,默认值为25%,如果副本数设置为4个,则在滚动升级过程中,不会运行超过5个pod。
maxUnavaliable: 决定允许多少个pod处于不可用状态,默认值为25%,如果副本数为4,那么只能有一个pod处于不可用状态,
默认情况下如果10分钟内没有升级完成,将被视为失败,如果要修改这个参数可以使用kubectl describe deploy kubia 查看到一条ProgressDeadline-Exceeded的记录,可以修改此项参数修改判断时间。
10.Statefulset:部署有状态的多副本应用
10.1.什么是Statefulset
StatefulSet是Kubernetes提供的管理有状态应用的负载管理控制器API。
特点:
1.具有固定的网络标记(主机名)
2.具有持久化存储
3.需要按顺序部署和扩展
4.需要按顺序终止和删除
5.需要按顺序滚动和更新
10.2.statefulset的创建
statefulset的创建顺序从0到N-1,终止顺序则相反,如果需要对satateful扩容,则之前的n个pod必须存在,如果要终止一个pod,则他的后续pod必须全部终止。
创建statefulset
#kubectl create -f ss-nginx.yml
查看statefulset
#kubectl get statefulset
statefulset会使用一个完全一致的pod来替换被删除的pod。
statefulset扩容和缩容时,都会删除最高索引的pod,当这个pod完全被删除后,才回删除拥有次高索引的pod。
10.3.statefulset中发现伙伴的节点
通过DNS中SRV互相发现。
10.4.更新statefulset
#kuebctl edit statefulset kubia
但修改后pod不会自动 被更新,需要手动delete pod后会重新调度更新。
10.5.statefulset如何处理节点失效
11.Kubernetes架构及相关服务详解
11.1.了解架构
K8s分为两部分:
1.Master节点
2.node节点
Master节点组件:
1.etcd分布式持久化存储
2.api服务器
3.scheduler
4.controller
Node节点:
1.kubelet
2.kube-proxy
3.容器运行时(docker、rkt及其它)
附加组件:
1.Dns服务器
2.仪表板
3.ingress控制器
4.Heapster控制器
5.网络容器接口插件
11.2.k8s组件分布式特性

k8s系统组件之间通信只能通过API服务器通信,他们之间不会之间进行通信。
API服务器是和etcd通信的唯一组件,其他组件不会直接和etcd进行通信。
API服务器与其他组件之间的通信基本上是由其他组件发起的,
//获取Master节点服务健康状况
#kubectl get componentstatuses
11.3.k8s如何使用etcd
etcd是一个响应快,分布式,一致的key-value存储。
是k8s存储集群状态和元数据唯一的地方,具有乐观锁特性,
关于乐观锁并发控制
乐观锁并发控制(有时候指乐观锁),是指一段数据包含一个版本数字,而不是锁住该段数据并阻止读写操作。每当更新数据,版本数就会增加。当更新数据时,版本就会增加。当更新数据时,就会检查版本值是否在客户端读取数据时间和提交时间之间被增加过。如果增加过,那么更新会被拒绝,客户端必须重新读取新数据,重新尝试更新。
两个客户端尝试更新同一个数据条目,只有一个会被更新成功。
资源如何存储在etcd中
flannel操作etcd使用的是v2的API,而kubernetes操作etcd使用的v3的API,所以在下面我们执行etcdctl的时候需要设置ETCDCTL_API环境变量,该变量默认值为2。
etcd是使用raft一致性算法实现的,是一款分布式的一致性KV存储,主要用于共享配置和服务发现。
Etcd V2和V3之间的数据结构完全不同,互不兼容。
确保etcd集群一致性
一致性算法要求大部分节点参与,才能进行到下一个状态,需要有过半的节点参与状态的更新,所以导致etcd的节点必须为奇数个。
11.4.API服务器
Kubernetes API服务器为API对象验证和配置数据,这些对象包含Pod,Service,ReplicationController等等。API Server提供REST操作以及前端到集群的共享状态,所有其它组件可以通过这些共享状态交互。
1.API提供RESTful API的形式,进行CRUD(增删查改)集群状态
2.进行校验
3.处理乐观锁,用于处理并发问题,
4.认证客户端
(1)通过认证插件认证客户端
(2)通过授权插件认证客户端
(3)通过准入插件验证AND/OR修改资源请求
API服务器如何通知客户端资源变更
API服务器不会去创建pod,同时他不会去管理服务的端点,
它做的是,启动控制器,以及一些其他的组件来监控一键部署的资源变更,是得组件可以再集群元数据变化时候执行任何需要做的任务,
11.5.了解调度器
调度器指定pod运行在哪个集群节点上。
调度器不会命令选中节点取运行pod,调度器做的就是通过api服务器更新pod的定义。然后api服务器再去通知kubelet该pod已经被调用。当目标节点的kubelet发现该pod被调度到本节点,就会创建并运行pod容器。
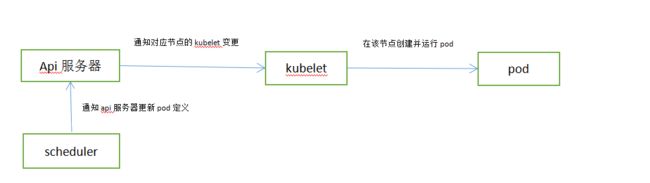
调度方法:
1.通过算法过滤所有节点,找到最优节点
2.查找可用节点
(1)是否满足对硬件的资源要求
(2)节点是否资源耗尽
(3)pod是否要求被调度到指定的节点、
(4)是否和要求的lable一致
(5)需求端口是否被占用
(6)是否有符合要求的存储卷
(7)是否容忍节点的污染
11.6.介绍控制器管理器中运行的控制器
(1)RC控制器
启动RC资源的控制器叫做Replication管理器。
RC的操作可以理解为一个无限的循环,每次循环,控制器都会查找符合其pod选择器的pod数量,并且将该数值和期望的复制集数量做比较。
(2)RS控制器
与RC类似
(3)DaemonSet以及job控制器
从他们各自资源集中定义pod模板创建pod资源,
(4)Deployment控制器
Deployment控制器负责使deployment的实际状态与对应的Deployment API对象期望状态同步。
每次Deployment对象修改后,Deployment控制器会滚动升级到新的版本。通过创建ReplicaSet,然后按照Deployment中定义的策略同时伸缩新、旧RelicaSet,直到旧pod被新的替代。
(5)StatefulSet控制器
StatefulSet控制器会初始化并管理每个pod实例的持久声明字段。
(6)Node控制器
Node控制器管理Node资源,描述了集群的工作节点。
(7)Service控制器
Service控制器就是用来在loadBalancer类型服务被创建或删除,从基础设施服务请求,释放负载均衡器的。
当Endpoints监听到API服务器中Aervice资源和pod资源发生变化时,会对应修改、创建、删除Endpoints资源。
(8)Endpoint资源控制器
Service不会直接连接到pod,而是通过一个ip和端口的列表,EedPoint管理器就是监听service和pod的变化,将ip和端口更新endpoint资源。
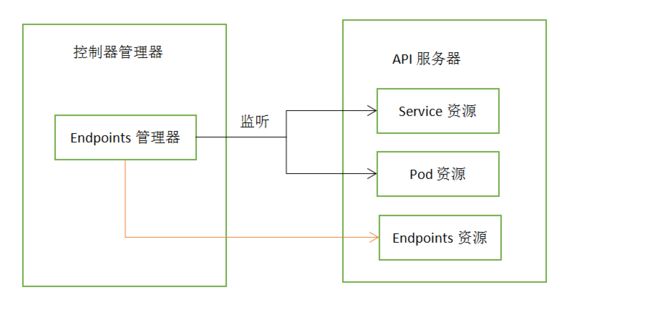
(9)Namespace控制器
当收到删除namespace对象的通知时,控制器通过API服务群删除后所有属于该命名空间的资源。
(10)PV控制器
创建一个持久卷声明时,就找到一个合适的持久卷进行绑定到声明。
11.7.kubelet做了什么
了解kubelet的工作内容
简单来说,就是负责所有运行在工作节点上的全部内容。
第一个任务,在api服务器中创建一个node资源来注册该节点;第二任务,持续监控api服务器是否把该节点分配给pod;第三任务,启动pod;第四任务,持续监控运行的容器,向api服务器报告他们的状态,事件和资源消耗。
第五任务,kubelet也是运行容器的存活探针的组件,当探针报错时,他会重启容器;第六任务,当pod从api服务器删除时,kubelet终止容器,并通知服务器pod已经终止。
11.1.7.kube-proxy的作用
service是一组pod的服务抽象,相当于一组pod的LB,负责将请求分发给对应的pod。service会为这个LB提供一个IP,一般称为cluster IP。
kube-proxy的作用主要是负责service的实现,具体来说,就是实现了内部从pod到service和外部的从node port向service的访问。
kube-proxy有两种代理模式,userspace和iptables,目前都是使用iptables。
12.kubernetes API服务器的安全防护
12.1.了解认证机制
启动API服务器时,通过命令行选项可以开启认证插件。
12.1.1.用户和组
了解用户:
分为两种连接到api服务器的客户端:
1.真实的人
2.pod,使用一种称为ServiceAccount的机制
了解组:
认证插件会连同用户名,和用户id返回组,组可以一次性给用户服务多个权限,不用单次赋予,
system:unauthenticated组:用于所有认证插件都不会认证客户端身份的请求。
system:authenticated组:会自动分配给一个成功通过认证的用户。
system:serviceaccount组:包含 所有在系统中的serviceaccount。
system:serviceaccount:
12.1.2 ServiceAccount介绍
每个pod中都包含/var/run/secrets/kubernetes.io/serviceaccount/token文件,如下图所示,文件内容用于对身份进行验证,token文件持有serviceaccount的认证token。

应用程序使用token去连接api服务器时,认证插件会对serviceaccount进行身份认证,并将serviceaccount的用户名传回到api服务器内部。
serviceaccount的用户名格式如下:
system:serviceaccount:
ServiceAccount是运行在pod中的应用程序,和api服务器身份认证的一中方式。
了解ServiceAccount资源
ServiceAcount作用在单一命名空间,为每个命名空间创建默认的ServiceAccount。

多个pod可以使用相同命名空间下的同一的ServiceAccount,
ServiceAccount如何与授权文件绑定
在pod的manifest文件中,可以指定账户名称的方式,将一个serviceAccount赋值给一个pod,如果不指定,将使用该命名空间下默认的ServiceAccount.
可以 将不同的ServiceAccount赋值给pod,让pod访问不同的资源。
12.1.3创建ServiceAccount
为了集群的安全性,可以手动创建ServiceAccount,可以限制只有允许的pod访问对应的资源。
创建方法如下:
$ kubectl get sa
NAME SECRETS AGE
default 1 21h
$ kubectl create serviceaccount yaohong
serviceaccount/yaohong created
$ kubectl get sa
NAME SECRETS AGE
default 1 21h
yaohong 1 3s
使用describe来查看ServiceAccount。
$ kubectl describe sa yaohong
Name: yaohong
Namespace: default
Labels:
Annotations:
Image pull secrets:
Mountable secrets: yaohong-token-qhbxn //如果强制使用可挂载秘钥。那么使用这个serviceaccount的pod只能挂载这个秘钥
Tokens: yaohong-token-qhbxn
Events: 查看该token,
$ kubectl describe secret yaohong-token-qhbxn
Name: yaohong-token-qhbxn
Namespace: default
Labels:
Annotations: kubernetes.io/service-account.name: yaohong
kubernetes.io/service-account.uid: a3d0d2fe-bb43-11e9-ac1e-005056870b4d
Type: kubernetes.io/service-account-token
Data
====
ca.crt: 1342 bytes
namespace: 7 bytes
token: eyJhbGciOiJSUzI1NiIsImtpZCI6IiJ9.eyJpc3MiOiJrdWJlcm5ldGVzL3NlcnZpY2VhY2NvdW50Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9uYW1lc3BhY2UiOiJkZWZhdWx0Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9zZWNyZXQubmFtZSI6Inlhb2hvbmctdG9rZW4tcWhieG4iLCJrdWJlcm5ldGVzLmlvL3NlcnZpY2VhY2NvdW50L3NlcnZpY2UtYWNjb3VudC5uYW1lIjoieWFvaG9uZyIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VydmljZS1hY2NvdW50LnVpZCI6ImEzZDBkMmZlLWJiNDMtMTFlOS1hYzFlLTAwNTA1Njg3MGI0ZCIsInN1YiI6InN5c3RlbTpzZXJ2aWNlYWNjb3VudDpkZWZhdWx0Onlhb2hvbmcifQ.BwmbZKoM95hTr39BuZhinRT_vHF-typH4anjkL0HQxdVZEt_eie5TjUECV9UbLRRYIqYamkSxmyYapV150AQh-PvdcLYPmwKQLJDe1-7VC4mO2IuVdMCI_BnZFQBJobRK9EdPdbZ9uxc9l0RL5I5WyWoIjiwbrQvtCUEIkjT_99_NngdrIr7QD9S5SxHurgE3HQbmzC6ItU911LjmxtSvBqS5NApJoJaztDv0cHKvlT67ZZbverJaStQdxr4yiRbpSycRNArHy-UZKbNQXuzaZczSjVouo5A5hzgSHEBBJkQpQ6Tb-Ko5XGjjCgV_b9uQvhmgdPAus8GdFTTFAbCBw
12.1.4将ServiceAccount分配给pod
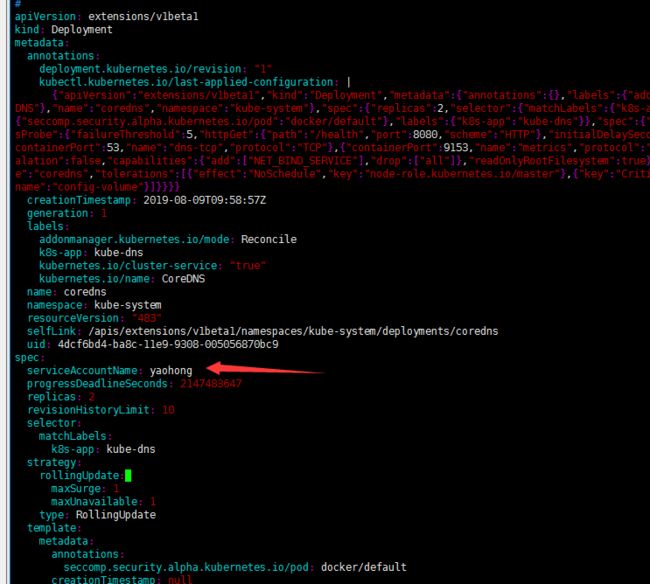
在pod中定义的spec.serviceAccountName字段上设置,此字段必须在pod创建时设置后续不能被修改。
自定义pod的ServiceAccount的方法如下图
12.2通过基于角色的权限控制加强集群安全
12.2.1.介绍RBAC授权插件
RBAC授权插件将用户角色作为决定用户能否执行操作的关机因素。
12.2.2介绍RBAC授权资源
RBAC授权规则通过四种资源来进行配置的,他们可以分为两组:
Role和ClusterRole,他们决定资源上可执行哪些动词。
RoleBinding和ClusterRoleBinding,他们将上述角色绑定到特定的用户,组或者ServiceAccounts上。
Role和RoleBinding是namespace级别资源
ClusterRole和ClusterRoleBinding是集群级别资源
12.2.3使用Role和RoleBinding
Role资源定义了哪些操作可以在哪些资源上执行,
创建Role
service-reader.yml
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
namespace: kube-system
name: service-reader
rules:
- apiGroups: [""]
verbs: ["get", "list"]
resources: ["services"]
在kube-system中创建Role
#kubectl -n kube-system create -f service-reader.yml
查看该namespace下的role
$ kubectl -n kube-system get role
NAME AGE
extension-apiserver-authentication-reader 41h
kube-state-metrics-resizer 41h
service-reader 2m17s
system::leader-locking-kube-controller-manager 41h
system::leader-locking-kube-scheduler 41h
system:controller:bootstrap-signer 41h
system:controller:cloud-provider 41h
system:controller:token-cleaner 41h绑定角色到ServiceAccount
将service-reader角色绑定到default ServiceAccount
$ kubectl create rolebinding test --role=service-reader
rolebinding.rbac.authorization.k8s.io/test created
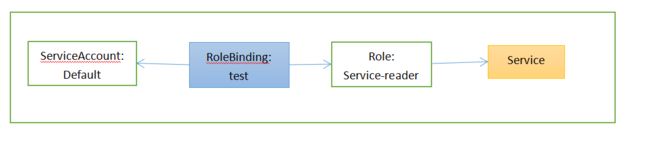
$ kubectl get rolebinding test -o yaml
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
creationTimestamp: 2019-08-11T03:40:51Z
name: test
namespace: default
resourceVersion: "239323"
selfLink: /apis/rbac.authorization.k8s.io/v1/namespaces/default/rolebindings/test
uid: d0aff243-bbe9-11e9-ac1e-005056870b4d
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: Role
name: service-reader
12.2.4使用ClusterRole和ClusterRoleBinding
查看集群ClusterRole
# kubectl get clusterrole
NAME AGE
admin 42h
cluster-admin 42h
edit 42h
flannel 42h
kube-state-metrics 42h
system:aggregate-to-admin 42h
...创建ClusterRole
kubectl create clusterrole flannel --verb=get,list -n kube-system 查看yaml文件
# kubectl get clusterrole flannel -o yaml
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
annotations:
kubectl.kubernetes.io/last-applied-configuration: |
{"apiVersion":"rbac.authorization.k8s.io/v1","kind":"ClusterRole","metadata":{"annotations":{},"name":"flannel"},"rules":[{"apiGroups":[""],"resources":["pods"],"verbs":["get"]},{"apiGroups":[""],"resources":["nodes"],"verbs":["list","watch"]},{"apiGroups":[""],"resources":["nodes/status"],"verbs":["patch"]}]}
creationTimestamp: 2019-08-09T09:58:42Z
name: flannel
resourceVersion: "360"
selfLink: /apis/rbac.authorization.k8s.io/v1/clusterroles/flannel
uid: 45100f6f-ba8c-11e9-8f57-005056870608
rules:
- apiGroups:
- ""
resources:
- pods
verbs:
- get
- apiGroups:
- ""
resources:
- nodes
verbs:
- list
- watch
- apiGroups:
- ""
resources:
- nodes/status
verbs:
- patch
创建clusterRoleBinding
$ kubectl create clusterrolebinding cluster-tetst --clusterrole=pv-reader --serviceaccount=kuebsystem:yaohong
clusterrolebinding.rbac.authorization.k8s.io/cluster-tetst created
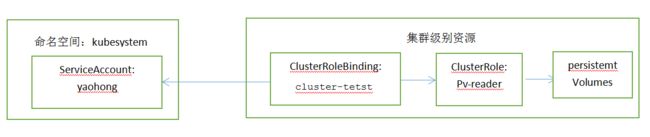
12.2.5了解默认的ClusterRole和ClusterRoleBinding
如下所示使用kubectl get clusterroles和kubectl get clusterrolesbinding可以获取k8s默认资源。
用edit ClusterRole允许对资源进行修改
用admin ClusterRole赋予一个命名空间全部的权限
$ kubectl get clusterroles
NAME AGE
admin 44h
cluster-admin 44h
edit 44h
flannel 44h
kube-state-metrics 44h
system:aggregate-to-admin 44h
system:aggregate-to-edit 44h
system:aggregate-to-view 44h
system:auth-delegator 44h
system:aws-cloud-provider 44h
system:basic-user 44h
system:certificates.k8s.io:certificatesigningrequests:nodeclient 44h
system:certificates.k8s.io:certificatesigningrequests:selfnodeclient 44h
system:controller:attachdetach-controller 44h
system:controller:certificate-controller 44h
system:controller:clusterrole-aggregation-controller 44h
。。。
wps@wps:~$ kubectl get clusterrolebindings
NAME AGE
clust-tetst 17m
cluster-admin 44h
cluster-tetst 13m
flannel 44h
kube-state-metrics 44h
kubelet-bootstrap 44h
system:aws-cloud-provider 44h
system:basic-user 44h
system:controller:attachdetach-controller 44h
system:controller:certificate-controller 44h
。。。
13.Kubernetes-保障集群内节点和网络安全
13.1.在pod中使用宿主节点的Linux命名空间
13.1.1.在pod中使用宿主节点的网络命名空间
在pod的yaml文件中就设置spec.hostNetwork: true
这个时候pod使用宿主机的网络,如果设置了端口,则使用宿主机的端口。
apiVersion: v1
kind: pod
metadata:
name: pod-host-yaohong
spec:
hostNetwork: true //使用宿主节点的网络命名空间
containers:
- image: luksa/kubia
command: ["/bin/sleep", "9999"]13.1.2.绑定宿主节点上的端口而不使用宿主节点的网络命名空间
在pod的yaml文件中就设置spec.containers.ports字段来设置
在ports字段中可以使用
containerPorts设置通过pod 的ip访问的端口
container.hostPort设置通过所在节点的端口访问
apiVersion: v1
kind: pod
metadata:
name: kubia-hostport-yaohong
spec:
containers:
- image: luksa/kubia
- name: kubia
ports:
- containerport: 8080 //该容器通过pod IP访问该端口
hostport: 9000 //该容器可以通过它所在节点9000端口访问
protocol: Tcp13.1.3.使用宿主节点的PID与IPC
PID是进程ID,PPID是父进程ID。
在linux下的多个进程间的通信机制叫做IPC(Inter-Process Communication),它是多个进程之间相互沟通的一种方法。
apiVersion: v1
kind: pod
metadata:
name: pod-with-host-pid-and-ipc-yaohong
spec:
hostPID: true //你希望这个pod使用宿主节点的PID命名空间
hostIPC: true //你希望pod使用宿主节点的IPC命名空间
containers:
- name: main
image: alpine
command: ["/bin/sleep", "99999"]
13.2.配置节点的安全上下文
13.2.1.使用指定用户运行容器
查看某个pod运行的用户
$ kubectl -n kube-system exec coredns-7b8dbb87dd-6ll7z id
uid=0(root) gid=0(root) groups=0(root),1(bin),2(daemon),3(sys),4(adm),6(disk),10(wheel),11(floppy),20(dialout),26(tape),27(video)
容器的运行用户再DockerFile中指定,如果没有指定则为root
指定pod的运行的用户方法如下
apiVersion: v1
kind: pod
metadata:
name: pod-as-user
spec:
containers:
- name: main
image: alpine
command: ["/bin/sleep", "99999"]
securityContext:
runAsUser: 405 //你需要指定的用户ID,而不是用户名13.2.2.阻止容器以root用户运行
runAsNonRoot来设置
apiVersion: v1
kind: pod
metadata:
name: pod-as-user
spec:
containers:
- name: main
image: alpine
command: ["/bin/sleep", "99999"]
securityContext:
runAsNonRoot: true //这个容器只允许以非root用户运行13.2.3.使用特权模式运行pod
为了获得宿主机内核完整的权限,该pod需要在特权模式下运行。需要添加privileged参数为true。
apiVersion: v1
kind: pod
metadata:
name: pod-as-privileged
spec:
containers:
- name: main
image: alpine
command: ["/bin/sleep", "99999"]
securityContext:
privileged: true //这个容器将在特权模式下运行13.2.4.为容器单独添加内核功能
apiVersion: v1
kind: pod
metadata:
name: pod-as-capability
spec:
containers:
- name: main
image: alpine
command: ["/bin/sleep", "99999"]
securityContext:
capabilities: //该参数用于pod添加或者禁用某项内核功能
add:
- SYS_TIME //添加修改系统时间参数
13.2.5.在容器中禁止使用内核功能
apiVersion: v1
kind: pod
metadata:
name: pod-as-capability
spec:
containers:
- name: main
image: alpine
command: ["/bin/sleep", "99999"]
securityContext:
capabilities: //该参数用于pod添加或者禁用某项内核功能
drop:
- CHOWN //禁用容器修改文件的所有者13.2.6.阻止对容器根文件系统的写入
securityContext.readyOnlyFilesystem设置为true来实现阻止对容器根文件系统的写入。
apiVersion: v1
kind: pod
metadata:
name: pod-with-readonly-filesystem
spec:
containers:
- name: main
image: alpine
command: ["/bin/sleep", "99999"]
securityContext:
readyOnlyFilesystem: true //这个容器的根文件系统不允许写入
volumeMounts:
- name: my-volume
mountPath: /volume //volume写入是允许的,因为这个目录挂载一个存储卷
readOnly: false 13.3.限制pod使用安全相关的特性
13.3.1.PodSecurityPolicy资源介绍
PodSecurityPolicy是一种集群级别(无命名空间)的资源,它定义了用户能否在pod中使用各种安全相关的特性。
13.3.2.了解runAsUser、fsGroups和supplementalGroup策略
runAsUser:
runle: MustRunAs
ranges:
- min: 2 //添加一个max=min的range,来指定一个ID为2的user
max: 2
fsGroup:
rule: MustRunAs
ranges:
- min: 2
max: 10 //添加多个区间id的限制,为2-10 或者20-30
- min: 20
max: 30
supplementalGroups:
rule: MustRunAs
ranges:
- min: 2
max: 10
- min: 20
max: 3013.3.3.配置允许、默认添加、禁止使用的内核功能
三个字段会影响容器的使用
allowedCapabilities:指定容器可以添加的内核功能
defaultAddCapabilities:为所有容器添加的内核功能
requiredDropCapabilities:禁止容器中的内核功能
apiVersion: v1
kind: PodSecurityPolicy
spec:
allowedCapabilities:
- SYS_TIME //允许容器添加SYS_time功能
defaultAddCapabilities:
- CHOWN //为每个容器自动添加CHOWN功能
requiredDropCapabilities:
- SYS_ADMIN //要求容器禁用SYS_ADMIN和SYS_MODULE功能13.4.隔离pod网络
13.4.1.在一个命名空间中使用网络隔离
podSelector进行对一个命名空间下的pod进行隔离
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: postgres-netpolicy
spec:
podSelector: //这个策略确保了对具有app=databases标签的pod的访问安全性
matchLabels:
app: database
ingress:
- from:
- podSelector: //它只允许来自具有app=webserver标签的pod的访问
matchLabels:
app: webserver
ports:
- port: 5432 //允许对这个端口的访问13.4.2.在 不同的kubernetes命名空间之间进行网络隔离
namespaceSelector进行对不同命名空间间进行网络隔离
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: postgres-netpolicy
spec:
podSelector: //这个策略确保了对具有app=databases标签的pod的访问安全性
matchLabels:
app: database
ingress:
- from:
- namespaceSelector: //只允许tenant: manning标签的命名空间中运行的pod进行互相访问
matchLabels:
tenant: manning
ports:
- port: 5432 //允许对这个端口的访问13.4.3.使用CIDR网络隔离
ingress:
- from:
- ipBlock:
cidr: 192.168.1.0/24 //指明允许访问的ip段13.4.4.限制pod对外访问流量
使用egress进行限制
spec:
podSelector: //这个策略确保了对具有app=databases标签的pod的访问安全性
matchLabels:
app: database
egress: //限制pod的出网流量
- to:
- podSelector:
matchLables: //database的pod只能与有app: webserver的pod进行通信
app: webserver