k8s 中部署grafana,prometheus 监控服务器信息
服务器为centos7
1:到docker hub 中搜索 grafana 选择最新版本 grafana/grafana:latest
2: 到docker hub 中搜索 prometheus 选择最新版本 prom/prometheus:v2.10.0
2: 到docker hub 中搜索 node-exporter 选择最新版本 prom/node-exporter:v0.17.0
3:通过kuboard 部署 以上三个个镜像
其中部署 prometheus 比较麻烦,步骤如下:
1:需要在服务器安装 nfs https://blog.csdn.net/qq_38265137/article/details/83146421
2:安装好后,创建存储类
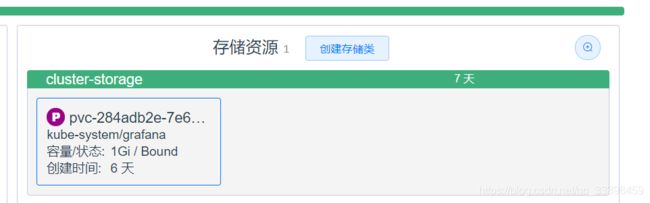
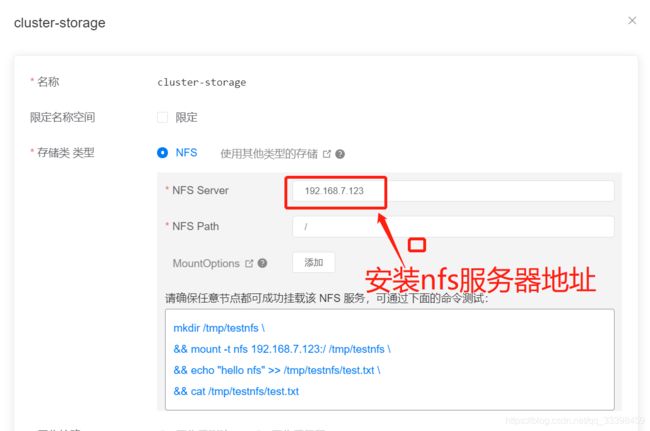
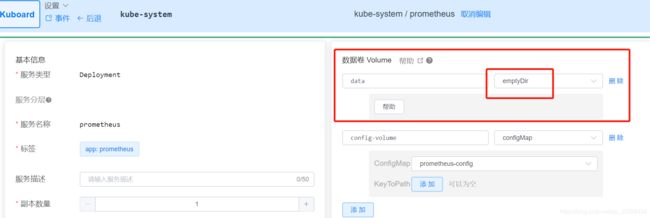
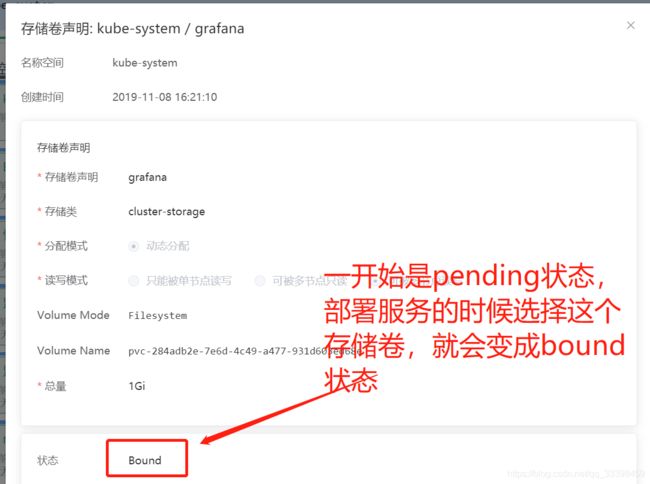
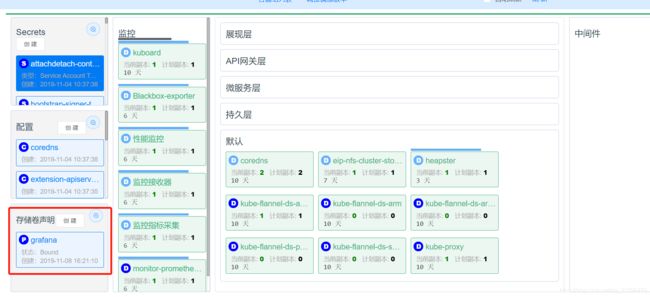 创建存储声明
创建存储声明
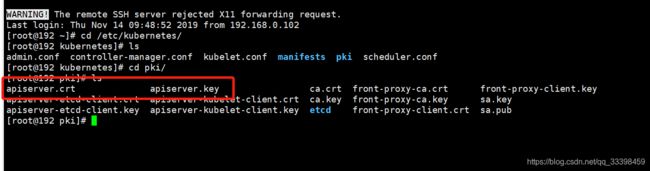
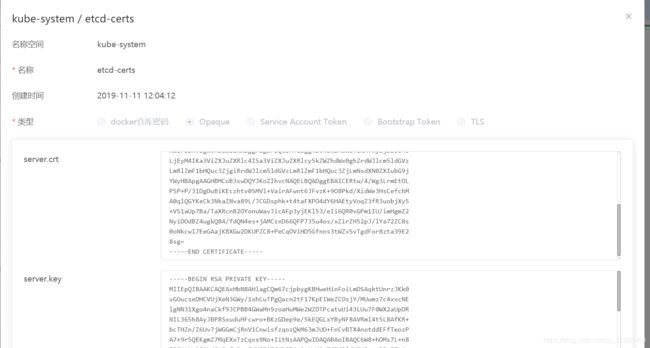
创建secrets,配置etcd-certs,到k8s路径下取到这两个crt,和key的值
配置prometheus config文件
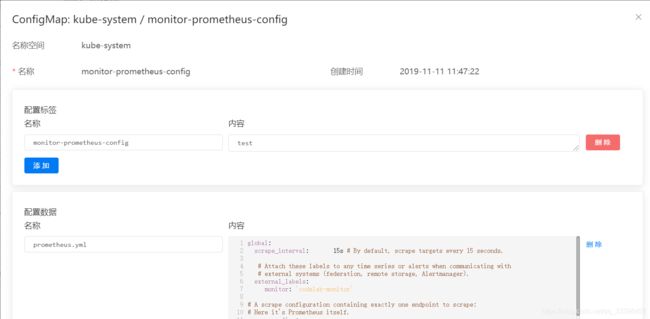
global:
scrape_interval: 15s # By default, scrape targets every 15 seconds.
# Attach these labels to any time series or alerts when communicating with
# external systems (federation, remote storage, Alertmanager).
external_labels:
monitor: 'codelab-monitor'
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=
- job_name: 'prometheus'
# Override the global default and scrape targets from this job every 5 seconds.
scrape_interval: 5s
static_configs:
- targets: ['localhost:9090']
- job_name: 'node'
# Override the global default and scrape targets from this job every 5 seconds.
scrape_interval: 5s
static_configs:
- targets: ['192.168.7.123:30091']
- job_name: 'heapster'
# Override the global default and scrape targets from this job every 5 seconds.
scrape_interval: 5s
static_configs:
- targets: ['192.168.7.123:30080']
- job_name: 'metrics'
# Override the global default and scrape targets from this job every 5 seconds.
scrape_interval: 5s
static_configs:
- targets: ['monitor-kube-state-metrics:8080']
- job_name: 'gateway'
# Override the global default and scrape targets from this job every 5 seconds.
scrape_interval: 5s
static_configs:
- targets: ['192.168.7.115:30020']
部署prometheus
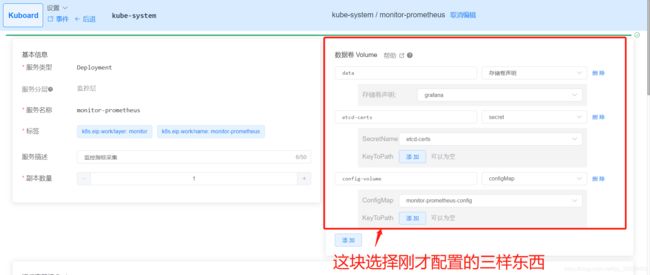
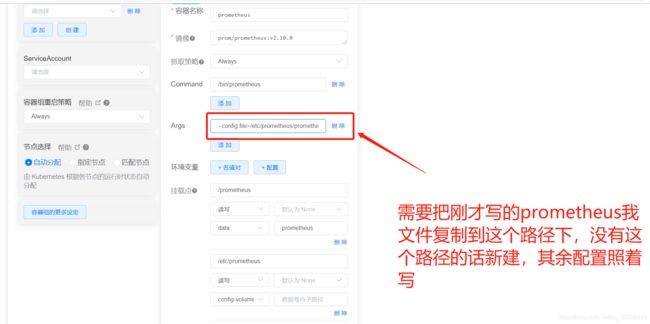
之后访问 ip:端口号 访问grafana
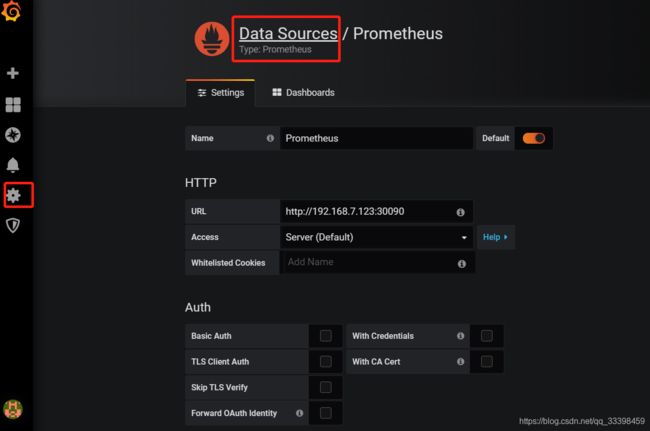
1:配置prometheus数据源
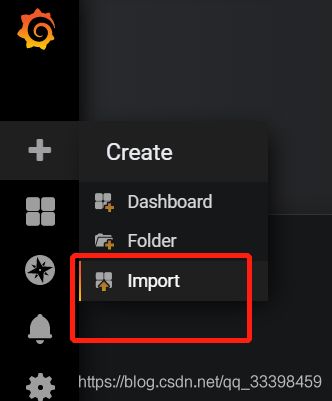
可以去 https://grafana.com/dashboards 自行搜寻,在这里我们用一名国人为 node_exporter 写的 Dashboard ,对应的主页为 https://grafana.com/dashboards/8919
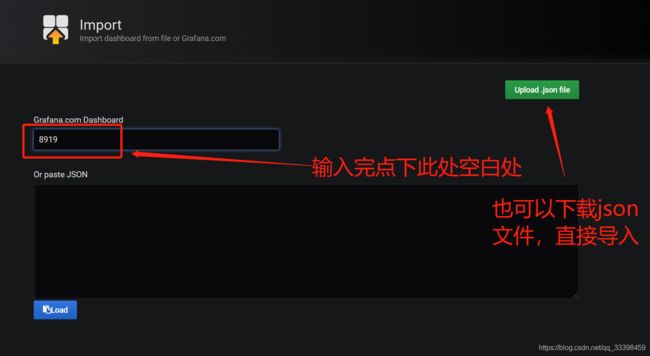
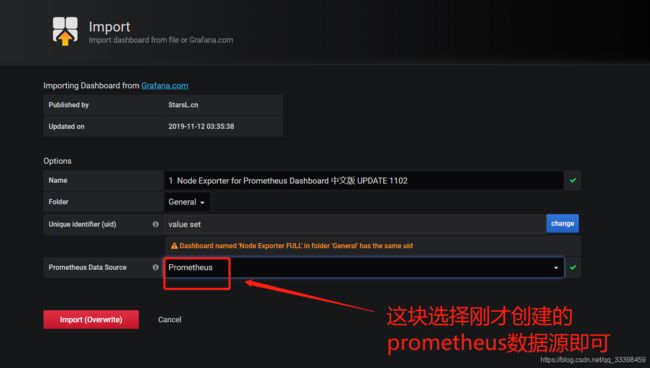

如果不能联网:需要导入以下镜像
quay.io/external_storage/nfs-client-provisioner:v3.1.0-k8s1.11
下面配置为空