Python正则表达式(正则、regular、re)讲解,及常用正则:匹配邮箱、身份证、手机号、IP地址、URL、HTML等
正则表达式(正则、regular、re)是 Python 中最常见的编程技巧,很多时候,一个好的正则表达式可以抵上几十行代码。比如:匹配(校验)邮箱、身份证、手机号、IP地址、URL、HTML等。
正则表达式,其实就是一串特殊的字符序列,而这串字符序列蕴含着事先定义好的 模式 (规则),可以用于匹配、校验其它的字符串(文本、网页等)。
但想掌握正则表达式的难度在于,其包括了较多的 基础模式语法 需要记忆,并且这些基础模式语法可以进行组合,产生无穷的变化。
所以,不建议死记硬背正则的基础模式语法,可以随用随查,使用多了,自然就会形成机械记忆了。
基础模式语法
** 字符范围匹配**
| 正则表达式 | 说明 | 正确 | 错误 |
|---|---|---|---|
| A | 精准匹配单个字符 | A | a |
| x|y | 允许出现的2个字符 | y | n |
| [xyz] | 字符集合,允许出现集合内任意单个字符 | z | c |
| [a-z] [A-Z] [0-9] | 字符范围 | a D 8 | A a A |
| [^xyz] [^0-9] | 集合内字符不允许出现 | 0 A | y 8 |
元字符
| 正则表达式 | 说明 | 正确 | 错误 |
|---|---|---|---|
| \d | 匹配任意单个数字 | 8 | i |
| \D | 匹配\d规则之外的任意单个字符 | i | 8 |
| \w | 匹配任意单个字母数字下划线 | Y | & |
| \W | 匹配\w之外的任意单个字符 | & | Y |
| \s | 匹配单个空格 | x | |
| \n | 匹配单个换行符 | x | |
| . | 匹配任意单个字符(换行符除外) | – | – |
| \. | 特殊字符,只匹配. | . | 1 |
多次重复匹配
| 正则表达式 | 说明 | 正确 | 错误 |
|---|---|---|---|
| A{3} | 精准N次匹配 | AAA | AA |
| A{3,} | 最少出现N次 | AAA | AA |
| \d{3,5} | 约定出现最少次数与最大次数 | 1234 | 12 |
| \d* | 可以出现零次至无限次,相当于{0,} | 1234 | – |
| \d+ | 最少出现一次,相当于{1,} | 12 | |
| \d? | 最多出现一次,相当于{0,1} | 1 | 12 |
定位匹配
| 正则表达式 | 说明 | 正确 | 错误 |
|---|---|---|---|
| ^A.* | 头匹配 | ABC | CBA |
| .*A$ | 尾匹配 | CBA | ABC |
| ^A.*A$ | 全字匹 | ACCCA | ACCC |
正则匹配流程
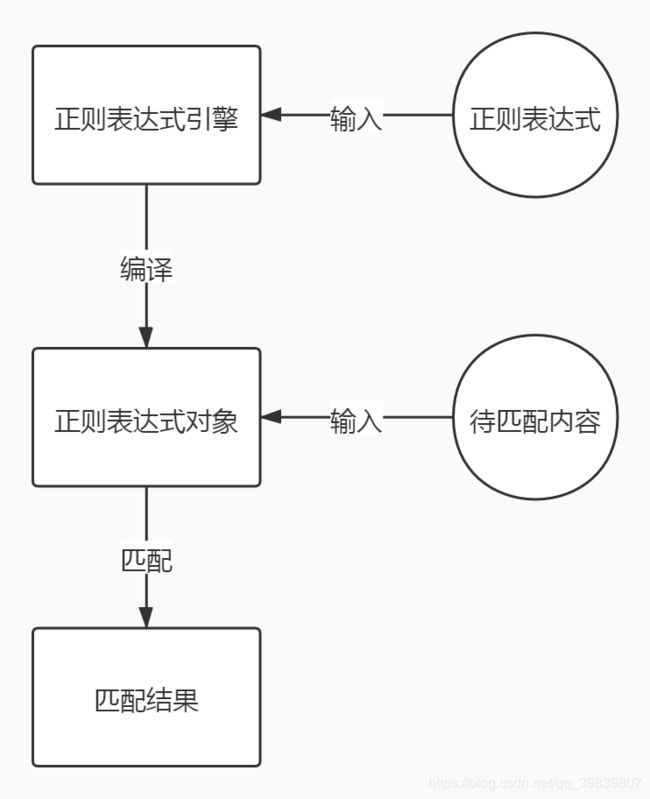
在正则匹配之前,需要先将正则表达式编译成正则表达式对象。所以,一个频繁使用的正则表达式会事先完成编译,以提高执行效率。
import re
# 密码强度的正则表达式
re_password = re.compile(r'^(?=.*\\d)(?=.*[a-z])(?=.*[A-Z]).{8,10}$')
同时在 re.compiler(pattern[, flags]) 时,可选正则表达式的修饰符,来控制匹配的模式。
具体如下表所示:
| 修饰符 | 描述 |
|---|---|
| re.I | 使匹配对大小写不敏感 |
| re.L | 做本地化识别(locale-aware)匹配 |
| re.M | 多行匹配,影响 ^ 和 $ |
| re.S | 使 . 匹配包括换行在内的所有字符 |
| re.U | 根据Unicode字符集解析字符。这个标志影响 \w, \W, \b, \B |
| re.X | 该标志通过给予你更灵活的格式以便你将正则表达式写得更易于理解 |
匹配
re.match(pattern, string, flags=0)
从字符串的起始位置匹配,如果不能起始位置匹配成功的话,则返回 None,这一点需要我们特别注意。
其中参数 flags 就是正则表达式的修饰符。
import re
print(re.match(r'hello', 'Hello world', re.I))
print(re.match(r'world', 'Hello world', re.I))
<_sre.SRE_Match object at 0x7f2c7c626648>
None
re.search(pattern, string, flags=0)
与 match 方法不同,它可以扫描整个字符串,并返回第一成功的匹配。
import re
print(re.search(r'hello', 'Hello world', re.I))
print(re.search(r'world', 'Hello world', re.I))
<_sre.SRE_Match object at 0x7fbcf9945648>
<_sre.SRE_Match object at 0x7fbcf9945648>
可以看到,search 方法成功找到了 world 字符串。
如果我们想输出匹配的结果,可以使用 group 和 groups。
import re
print(re.search(r'world', 'Hello world', re.I).group(0))
print(re.search(r'(world)', 'Hello world', re.I).groups())
world
('world',)
这里有一个知识点就是 () 在正则表达式中应用给 groups 。
还有一点需要特别说明, 正则表达式匹配默认是 贪婪匹配 。
import re
print(re.match(r'^(\d+)(0*)$', '102300').groups())
print(re.match(r'^(\d+?)(0*)$', '102300').groups())
('102300', '')
('1023', '00')
由于\d+ 采用贪婪匹配,直接把后面的 0 全部匹配了,结果 0* 只能匹配空字符串了。
必须让 \d+ 采用非贪婪匹配(也就是尽可能少匹配),才能把后面的 0 匹配出来,加个 ? 就可以让 \d+ 采用。
match 和 search 只能匹配一次,如果想匹配所有,那么可以使用 findall 和 finditer 。
findall(string[, pos[, endpos]]
import re
# 匹配数字
pattern = re.compile(r'\d+')
result1 = pattern.findall('runoob 123 google 456')
result2 = pattern.findall('run88oob123google456', 0, 10)
print(result1)
print(result2)
['123', '456']
['88', '12']
finditer(pattern, string, flags=0)
import re
# 匹配数字
it = re.finditer(r"\d+","12a32bc43jf3")
for match in it:
print (match.group())
12
32
43
3
除了单纯的匹配之外,还会有 分割 和 替换 的需求,所以下面介绍这两种方法:
re.split(pattern, string[, maxsplit=0, flags=0])
import re
print(re.split('\W+', 'runoob, runoob, runoob.'))
['runoob', 'runoob', 'runoob', '']
re.sub(pattern, repl, string, count=0, flags=0)
import re
dt = '2020-01-01'
print(re.sub(r'\D', ' ', dt))
2020 01 01
常用正则表达式
- 校验密码强度:
^(?=.*\\d)(?=.*[a-z])(?=.*[A-Z]).{8,10}$ - 校验中文:
^[\\u4e00-\\u9fa5]{0,}$ - 有数字、26个英文字母或下划线组成的字符串:
^\\w+$ - 校验Email地址:
[\\w!#$%&'*+/=?^_`{|}~-]+(?:\\.[\\w!#$%&'*+/=?^_`{|}~-]+)*@(?:[\\w](?:[\\w-]*[\\w])?\\.)+[\\w](?:[\\w-]*[\\w])? - 校验身份证号码
15位:^[1-9]\\d{7}((0\\d)|(1[0-2]))(([0|1|2]\\d)|3[0-1])\\d{3}$
18位:^[1-9]\\d{5}[1-9]\\d{3}((0\\d)|(1[0-2]))(([0|1|2]\\d)|3[0-1])\\d{3}([0-9]|X)$ - 校验手机号:
^(13[0-9]|14[5|7]|15[0|1|2|3|5|6|7|8|9]|18[0|1|2|3|5|6|7|8|9])\\d{8}$ - IP地址:
v4:\\b(?:(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\\.){3}(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\\b
v6:(([0-9a-fA-F]{1,4}:){7,7}[0-9a-fA-F]{1,4}|([0-9a-fA-F]{1,4}:){1,7}:|([0-9a-fA-F]{1,4}:){1,6}:[0-9a-fA-F]{1,4}|([0-9a-fA-F]{1,4}:){1,5}(:[0-9a-fA-F]{1,4}){1,2}|([0-9a-fA-F]{1,4}:){1,4}(:[0-9a-fA-F]{1,4}){1,3}|([0-9a-fA-F]{1,4}:){1,3}(:[0-9a-fA-F]{1,4}){1,4}|([0-9a-fA-F]{1,4}:){1,2}(:[0-9a-fA-F]{1,4}){1,5}|[0-9a-fA-F]{1,4}:((:[0-9a-fA-F]{1,4}){1,6})|:((:[0-9a-fA-F]{1,4}){1,7}|:)|fe80:(:[0-9a-fA-F]{0,4}){0,4}%[0-9a-zA-Z]{1,}|::(ffff(:0{1,4}){0,1}:){0,1}((25[0-5]|(2[0-4]|1{0,1}[0-9]){0,1}[0-9])\\.){3,3}(25[0-5]|(2[0-4]|1{0,1}[0-9]){0,1}[0-9])|([0-9a-fA-F]{1,4}:){1,4}:((25[0-5]|(2[0-4]|1{0,1}[0-9]){0,1}[0-9])\\.){3,3}(25[0-5]|(2[0-4]|1{0,1}[0-9]){0,1}[0-9])) - 提取页面超链接:
( - 校验日期:
^(?:(?!0000)[0-9]{4}-(?:(?:0[1-9]|1[0-2])-(?:0[1-9]|1[0-9]|2[0-8])|(?:0[13-9]|1[0-2])-(?:29|30)|(?:0[13578]|1[02])-31)|(?:[0-9]{2}(?:0[48]|[2468][048]|[13579][26])|(?:0[48]|[2468][048]|[13579][26])00)-02-29)$ - 校验金额:
^[0-9]+(.[0-9]{2})?$
最后,安利大家一本书《深入理解NLP的中文分词:从原理到实践》,让你从零掌握中文分词技术,踏入NLP的大门。
如果因为以上内容对你有所帮助,希望你能帮个忙,点个赞、评个论、转个发,关个注。
此公众号每周分享一篇干货文章,实实在在把一个课题说明白,讲清楚,望关注!
