Lucene从入门到正常使用到底层剖析
Lucene(中文解释网络 搜索引擎; 全文检索; 搜索技术; 垂直搜索引擎;)
Lucene简介
Lucene是apache软件基金会4 jakarta项目组的一个子项目,是一个开放源代码的全文检索引擎工具包,但它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎,部分文本分析引擎(英文与德文两种西方语言)。Lucene的目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能,或者是以此为基础建立起完整的全文检索引擎。Lucene是一套用于全文检索和搜寻的开源程式库,由Apache软件基金会支持和提供。Lucene提供了一个简单却强大的应用程式接口,能够做全文索引和搜寻。在Java开发环境里Lucene是一个成熟的免费开源工具。就其本身而言,Lucene是当前以及最近几年最受欢迎的免费Java信息检索程序库。人们经常提到信息检索程序库,虽然与搜索引擎有关,但不应该将信息检索程序库与搜索引擎相混淆。
Lucene特点优势
Lucene作为一个全文检索引擎,其具有如下突出的优点:
(1)索引文件格式独立于应用平台。Lucene定义了一套以8位字节为基础的索引文件格式,使得兼容系统或者不同平台的应用能够共享建立的索引文件。
(2)在传统全文检索引擎的倒排索引的基础上,实现了分块索引,能够针对新的文件建立小文件索引,提升索引速度。然后通过与原有索引的合并,达到优化的目的。
(3)优秀的面向对象的系统架构,使得对于Lucene扩展的学习难度降低,方便扩充新功能。
(4)设计了独立于语言和文件格式的文本分析接口,索引器通过接受Token流完成索引文件的创立,用户扩展新的语言和文件格式,只需要实现文本分析的接口。
(5)已经默认实现了一套强大的查询引擎,用户无需自己编写代码即可使系统可获得强大的查询能力,Lucene的查询实现中默认实现了布尔操作、模糊查询(Fuzzy Search[11])、分组查询等等。
面对已经存在的商业全文检索引擎,Lucene也具有相当的优势。
首先,它的开发源代码发行方式(遵守Apache Software License[12]),在此基础上程序员不仅仅可以充分的利用Lucene所提供的强大功能,而且可以深入细致的学习到全文检索引擎制作技术和面向对象编程的实践,进而在此基础上根据应用的实际情况编写出更好的更适合当前应用的全文检索引擎。在这一点上,商业软件的灵活性远远不及Lucene。
其次,Lucene秉承了开放源代码一贯的架构优良的优势,设计了一个合理而极具扩充能力的面向对象架构,程序员可以在Lucene的基础上扩充各种功能,比如扩充中文处理能力,从文本扩充到HTML、PDF[13]等等文本格式的处理,编写这些扩展的功能不仅仅不复杂,而且由于Lucene恰当合理的对系统设备做了程序上的抽象,扩展的功能也能轻易的达到跨平台的能力。
最后,转移到apache软件基金会后,借助于apache软件基金会的网络平台,程序员可以方便的和开发者、其它程序员交流,促成资源的共享,甚至直接获得已经编写完备的扩充功能。最后,虽然Lucene使用Java语言写成,但是开放源代码社区的程序员正在不懈的将之使用各种传统语言实现(例如.net framework[14]),在遵守Lucene索引文件格式的基础上,使得Lucene能够运行在各种各样的平台上,系统管理员可以根据当前的平台适合的语言来合理的选择。
开发使用
基于Luence使用 Solr和elasticsearch
Solr:Solr是一个独立的企业级搜索应用服务器,它对外提供类似于Web-service的API接口。用户可以通过http请求,向搜索引擎服务器提交一定格式的XML文件,生成索引;也可以通过Http Get操作提出查找请求,并得到XML格式的返回结果。 ps:https://baike.baidu.com/item/Solr/4101582?fr=aladdin
elasticsearch :ElasticSearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java语言开发的,并作为Apache许可条款下的开放源码发布,是一种流行的企业级搜索引擎。ElasticSearch用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。官方客户端在Java、.NET(C#)、PHP、Python、Apache Groovy、Ruby和许多其他语言中都是可用的。根据DB-Engines的排名显示,Elasticsearch是最受欢迎的企业搜索引擎,其次是Apache Solr,也是基于Lucene。 ps:https://baike.baidu.com/item/elasticsearch/3411206?fr=aladdin
二 认识检索
一、 什么是全文检索
全文检索是计算机程序通过扫描文章中的每一个词,对每一个词建立一个索引,指明该词在文章中出现的次数和位置。当用户查询时根据建立的索引查找,类似于通过字典的检索字表查字的过程
全文检索(Full-Text Retrieval)以文本作为检索对象,找出含有指定词汇的文本。全面、准确和快速是衡量全文检索系统的关键指标。
关于全文检索,我们要知道:
1,只处理文本。
2,不处理语义。
3,搜索时英文不区分大小写。
4,结果列表有相关度排序。
二、 全文检索与数据库检索的区别
全文检索不同于数据库的SQL查询。(他们所解决的问题不一样,解决的方案也不一样,所以不应进行对比)。在数据库中的搜索就是使用SQL,如:SELECT * FROM t WHERE content like ‘%ant%’。这样会有如下问题:
1、匹配效果:如搜索ant会搜索出planting。这样就会搜出很多无关的信息。
2、相关度排序:查出的结果没有相关度排序,不知道我想要的结果在哪一页。我们在使用百度搜索时,一般不需要翻页,为什么?因为百度做了相关度排序:为每一条结果打一个分数,这条结果越符合搜索条件,得分就越高,叫做相关度得分,结果列表会按照这个分数由高到低排列,所以第1页的结果就是我们最想要的结果。
3、全文检索的速度大大快于SQL的like搜索的速度。这是因为查询方式不同造成的,以查字典举例:数据库的like就是一页一页的翻,一行一行的找,而全文检索是先查目录,得到结果所在的页码,再直接翻到这一页。
三、 全文检索的使用场景
我们使用Lucene,主要是做站内搜索,即对一个系统内的资源进行搜索。如BBS(论坛)、BLOG(博客)中的文章搜索,网上商店中的商品搜索等。使用Lucene的项目有Eclipse,智联招聘,天猫,京东等。一般不做互联网中资源的搜索,因为不易获取与管理海量资源(专业搜索方向的公司除外)
三 开发使用
3.1jar包
lucene有7个包需要导入:analysis,document,index,queryParser,search,store,util
3.2 开发我的第一个Lucene程序
创建索引也就是(添加)


package com.MyFirstLuence.xql.Test;
import java.io.File;
import java.io.IOException;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field.Store;
import org.apache.lucene.document.IntField;
import org.apache.lucene.document.StringField;
import org.apache.lucene.document.TextField;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.index.IndexableField;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.util.Version;
public class CreatLuence {
public static void main(String[] args) throws IOException {
File path = new File("D:\\index");//用来创建文件夹对象构造参数路径
/**
* 获取(创建)索引写入器对象(indexWriter)
* Directory索引库
*/
Directory directory = FSDirectory.open(path);//抽象父类只能用子类创建
Version version = Version.LUCENE_44;//一个是Luence的版本号
Analyzer analyzer = new StandardAnalyzer(version);//分词器类型 这里是标准分词器StandardAnalyzer
IndexWriterConfig config = new IndexWriterConfig(version,analyzer);//两个参数 一个版本 一个
/**
* 第一个参数获取写入器把索引写到那个位置
* 第二个配置初始化Config里面的配置信息
* config里面两个参数一个是Luence的版本号一个是
* 一个是 分词器类型有很多如标准分词器等等
*/
IndexWriter indexwriter = new IndexWriter(directory,config);
/**
* 写入格式 只支持Document格式
*/
Document document = new Document();
/**
* 会发现IndexableField的实现类的构造方法有三个参数
* 1.是数据key
* 2.是value
* 3.是是否放入指定源数据区域 Store(保存储存)
* lucene中的Field对象是luene进行创建索引的具体字段,
* Field主要包含如下三个属性 name(字段名称) ,
* value(字段对应的值),
* IndexableFieldType(该字段的配置信息,是否存储,是否分词等等属性配置),
* 常用的Field子类的属性详解 看后面分析
*/
IndexableField field1 = new IntField("id",1,Store.YES);//接口 只能用实现类 不同类型的用不同实现类
 field2 = new StringField("title","不开森",Store.YES);//接口 只能用实现类 不同类型的用不同实现类
IndexableField field3 = new TextField("content","拍卖拍卖不开森",Store.YES);//接口 只能用实现类 不同类型的用不同实现类
document.add(field1);//肯定调用的是类里面封装的方法
document.add(field2);//肯定调用的是类里面封装的方法
document.add(field3);//肯定调用的是类里面封装的方法
/**
* 接下来文档有了 写入器也有了 肯定是用写入器把Document写入索引创建索引
*/
indexwriter.addDocument(document);//把指定文件写入服务器指定存储索引位置
/**
* 释放资源 关闭indexwriter索引写入器对象
*/
if(indexwriter!=null){
indexwriter.close();
}
/**
* 写完就该测试了
* 测试思路 运行 查看指定路径是否有自动索引文件
*/
}
}
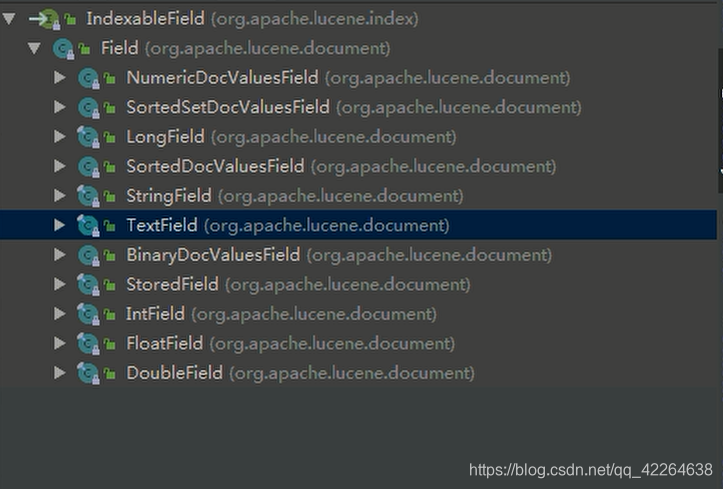
用到的相关接口(或者抽象类)的实现类或者子类
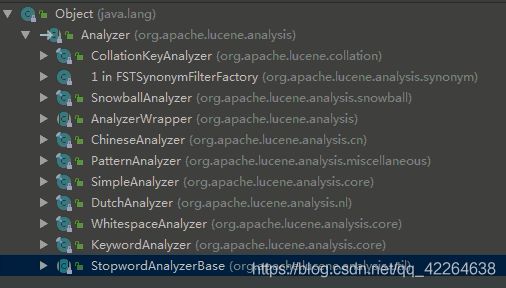


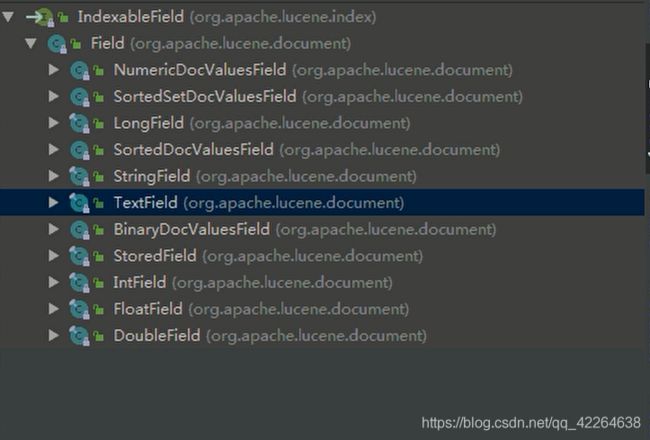
索引搜索器(索引读出器 也就是 查)


package com.MyFirstLuence.xql.Test;
import java.io.File;
import java.io.IOException;
import org.apache.lucene.document.Document;
import org.apache.lucene.index.DirectoryReader;
import org.apache.lucene.index.IndexReader;
import org.apache.lucene.index.Term;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TermQuery;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
public class RederLuence {
/** 注意:
* 八种基本数据类型 + String类型不分词
* Text类型分词 标准分词器的规则 单字分词
*/
public static void main(String[] args) throws IOException {
File path = new File("D:\\index");//索引写入器写入的位置
Directory directory = FSDirectory.open(path);//抽象父类只能用子类创建 读取位置
/**
* 刚刚写好索引
* 现在使用 使用的话我们创建索引用的indexwriter写入索引器
* 现在读应该用reader读索引器
*/
IndexReader indexreader = DirectoryReader.open(directory);//抽象类由抽象类方法创建
/**
* 创建索引搜索对象
*/
IndexSearcher indexSearcher = new IndexSearcher(indexreader);
/**
* fld属性列
* text 文本查什么
*/
Query query = new TermQuery(new Term("title", "不开森"));//抽象类 (Query查询)子类(TermQuery词查询)
int n=100;//
/**
* topDocs 查询的结果是TopDocs相关度排序 (查的是索引区)
*/
TopDocs topDocs = indexSearcher.search(query, n);//两个参数 第一个根据什么搜索(搜索条件) 第二个搜索多少条
/**
* 想要展示肯定想我刚刚查询结果进行相关度排序 所有调用工具类topDocs里面的方法
*/
ScoreDoc[] scoreDocs = topDocs.scoreDocs;//查看源码调用这个方法返回数组
/**
* scoreDoc里面又是一个对象里面存储了关于这篇文章索引区的信息比如索引编号索引评分
* scoreDoc.doc是索引区的索引编号
*/
for (ScoreDoc scoreDoc : scoreDocs) {
int id = scoreDoc.doc;
float score = scoreDoc.score;//文章评分
System.out.println(id);
System.out.println(score);//文章评分
Document doc = indexSearcher.doc(id);//根据文章索引编号查询在元数据区查找
System.out.println(doc.get("id"));//元数据区文章id
System.out.println(doc.get("title"));//元数据区文章标题
System.out.println(doc.get("content"));//元数据区文章内容
}
}
}
用到的相关子类或者实现类或者类的信息
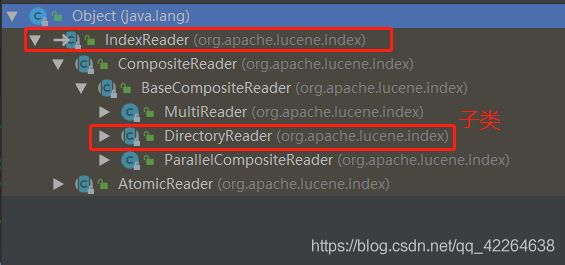


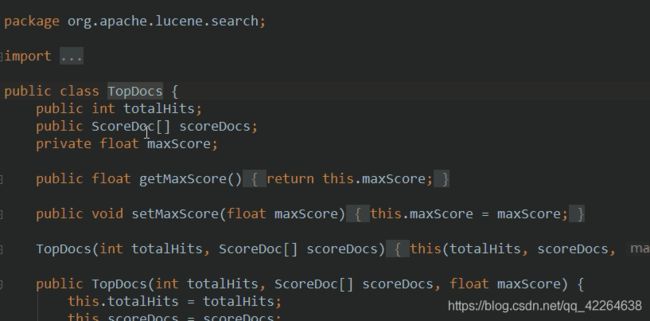
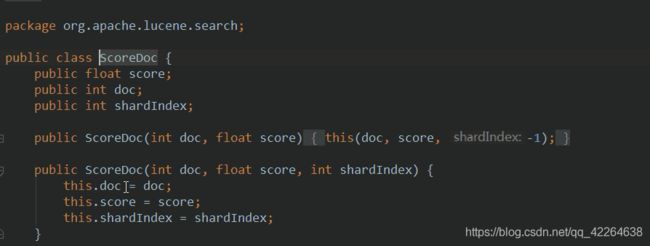
注意:
* 八种基本数据类型 + String类型不分词
* Text类型分词 标准分词器的规则 单字分词
删除索引 (删)


package com.MyFirstLuence.xql.Test;
import java.io.File;
import java.io.IOException;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.index.Term;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.util.Version;
public class DeleteLuence {
public static void main(String[] args) {
/**
* 第一个参数获取写入器把索引写到那个位置
* 第二个配置初始化Config里面的配置信息
* config里面两个参数一个是Luence的版本号一个是
* 一个是 分词器类型有很多如标准分词器等等
*/
IndexWriter indexwriter = null;
try {
File path = new File("D:\\index");//用来创建文件夹对象构造参数路径
/**
* 获取(创建)索引写入器对象(indexWriter)
* Directory索引库
*/
Directory directory = FSDirectory.open(path);//抽象父类只能用子类创建
Version version = Version.LUCENE_44;//一个是Luence的版本号
Analyzer analyzer = new StandardAnalyzer(version);//分词器类型 这里是标准分词器StandardAnalyzer
IndexWriterConfig config = new IndexWriterConfig(version, analyzer);//两个参数 一个版本 一个
indexwriter = new IndexWriter(directory, config);
/**
* Term 词
* fld属性列
* text 文本查什么
*/
//如果只删除一个词则发现根据其他还可以查询 不是我们想要的
indexwriter.deleteDocuments(new Term("title", "不开森"));
indexwriter.deleteDocuments(new Term("id", "1"));
indexwriter.deleteDocuments(new Term("content", "拍卖拍卖不开森"));
indexwriter.commit();
} catch (Exception e) {
e.printStackTrace();
try {
indexwriter.rollback();
} catch (IOException e1) {
e1.printStackTrace();
throw new RuntimeException(e1);
}
throw new RuntimeException(e);
}finally{
if(indexwriter!=null){
try {
indexwriter.close();
} catch (IOException e) {
e.printStackTrace();
throw new RuntimeException(e);
}
}
}
}
}
修改索引(改)
package com.MyFirstLuence.xql.Test;
import java.io.File;
import java.io.IOException;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.IntField;
import org.apache.lucene.document.StringField;
import org.apache.lucene.document.TextField;
import org.apache.lucene.document.Field.Store;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.index.IndexableField;
import org.apache.lucene.index.Term;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.util.Version;
public class UpdateLuence {
//lucene 更新 先删除 再添加
public static void main(String[] args) {
/**
* 第一个参数获取写入器把索引写到那个位置
* 第二个配置初始化Config里面的配置信息
* config里面两个参数一个是Luence的版本号一个是
* 一个是 分词器类型有很多如标准分词器等等
*/
IndexWriter indexwriter = null;
try {
File path = new File("D:\\index");//用来创建文件夹对象构造参数路径
/**
* 获取(创建)索引写入器对象(indexWriter)
* Directory索引库
*/
Directory directory = FSDirectory.open(path);//抽象父类只能用子类创建
Version version = Version.LUCENE_44;//一个是Luence的版本号
Analyzer analyzer = new StandardAnalyzer(version);//分词器类型 这里是标准分词器StandardAnalyzer
IndexWriterConfig config = new IndexWriterConfig(version, analyzer);//两个参数 一个版本 一个
indexwriter = new IndexWriter(directory, config);
Document document = new Document();
/**
* 会发现IndexableField的实现类的构造方法有三个参数
* 1.是数据key
* 2.是value
* 3.是是否放入指定源数据区域 Store(保存储存)
* lucene中的Field对象是luene进行创建索引的具体字段,
* Field主要包含如下三个属性 name(字段名称) ,
* value(字段对应的值),
* IndexableFieldType(该字段的配置信息,是否存储,是否分词等等属性配置),
* 常用的Field子类的属性详解 看后面分析
*/
IndexableField field1 = new IntField("id",1,Store.YES);//接口 只能用实现类 不同类型的用不同实现类
IndexableField field2 = new StringField("title","开森",Store.YES);//接口 只能用实现类 不同类型的用不同实现类
IndexableField field3 = new TextField("content","拍卖拍卖不开森ssssssss",Store.YES);//接口 只能用实现类 不同类型的用不同实现类
document.add(field1);//肯定调用的是类里面封装的方法
document.add(field2);//肯定调用的是类里面封装的方法
document.add(field3);//肯定调用的是类里面封装的方法
/**
* Term 词
* fld属性列
* text 这个时候这个参数是新值
* 参数document 那个文档格式
*/
//lucene 更新 先删除 再添加
indexwriter.updateDocument(new Term("id","4"), document);
indexwriter.commit();
} catch (Exception e) {
e.printStackTrace();
try {
indexwriter.rollback();
} catch (IOException e1) {
e1.printStackTrace();
throw new RuntimeException(e1);
}
throw new RuntimeException(e);
}finally{
if(indexwriter!=null){
try {
indexwriter.close();
} catch (IOException e) {
e.printStackTrace();
throw new RuntimeException(e);
}
}
}
}
}
注意:
Lucene更新时会把符合条件的数据删除,在创建一条数据