StackOverflow 这么大,它的架构是怎么样的?
【伯乐在线补充】:Nick Craver 是 StackOverflow 的软件工程师 & 网站可靠性工程师。
这是「解密 Stack Overflow 架构」系列的第一篇,本系列会有非常多的内容。欢迎阅读并保持关注。
为了便于理解本文涉及到的东西到底都干些了什么,让我先从 Stack Overflow 每天平均统计量的变化开始。下面的数据数来自 2013 年 11 月 12 日的统计:
- 负载均衡器接受了148,084,833次HTTP请求
- 其中36,095,312次是加载页面
- 833,992,982,627 bytes (776 GB) 的HTTP流量用于发送
- 总共接收了286,574,644,032 bytes (267 GB) 数据
- 总共发送了1,125,992,557,312 bytes (1,048 GB) 数据
- 334,572,103次SQL查询(仅包含来自于HTTP请求的)
- 412,865,051次Redis请求
- 3,603,418次标签引擎请求
- 耗时558,224,585 ms (155 hours) 在SQL查询上
- 耗时99,346,916 ms (27 hours) 在Redis请求上
- 耗时132,384,059 ms (36 hours) 在标签引擎请求上
- 耗时2,728,177,045 ms (757 hours) 在ASP.Net程序处理上
- 节选自@蒋生武 翻译的《StackOverflow 这么大,究竟用在什么硬件设备?》
下方数据是到 2016 年 2 月 9 日时,统计数字发生的变化,你可以比较一下:
- 负载均衡器收到的 HTTP 请求:209,420,973 (+61,336,090)
- 66,294,789 (+30,199,477) 其中的页面加载数量
- 发送的 HTTP 数据量:1,240,266,346,053 (+406,273,363,426) bytes (1.24 TB)
- 总共接收的数据量:569,449,470,023 (+282,874,825,991) bytes (569 GB)
- 总共发送的数据量:3,084,303,599,266 (+1,958,311,041,954) bytes (3.08 TB)
- SQL 查询(仅来自于 HTTP 请求):504,816,843 (+170,244,740)
- Redis 缓存命中数:5,831,683,114 (+5,418,818,063)
- Elastic 搜索数量:17,158,874 (not tracked in 2013)
- 标签引擎(Tag Engine)请求数:3,661,134 (+57,716)
- 运行 SQL 查询累计消耗的时间:607,073,066 (+48,848,481) ms (168 hours)
- Redis 缓存命中消耗的时间:10,396,073 (-88,950,843) ms (2.8 hours)
- 标签引擎请求消耗的时间:147,018,571 (+14,634,512) ms (40.8 hours)
- 在 ASP.Net 处理中消耗的时间:1,609,944,301 (-1,118,232,744) ms (447 hours)
- 22.71 (-5.29) ms 49,180,275 个问题页面平均的渲染时间(其中 19.12 ms 消耗在 ASP.Net 中)
- 11.80 (-53.2) ms 6,370,076 个首页的平均渲染时间(其中 8.81 ms 消耗在 ASP.Net 中)
你可能会好奇为什么 ASP.Net 在每天多处理6100万次请求的情况下,处理时间却减少了757个小时(相比于在2013 年)。这主要归功于在 2015 年初的时候我们对服务器进行的升级,以及大量的应用内的性能优化工作。别忘了:性能依然是个卖点。如果你对具体的硬件配置细节更加好奇的话,别担心,我很快就会在下一篇文章中以附录的形式给出运行这些网站所用的服务器的具体硬件配置细节(到时候我会更新这个链接)。
所以这两年来到底发生了哪些变化?不太多,只是替换掉一些服务器和网络设备而已。下面是今天运行网站所用的服务器概览(注意和 2013 年相比有什么变化)
- 4 台 Microsoft SQL Server 服务器(其中 2 台使用了新的硬件)
- 11 台 IIS Web 服务器(新的硬件)
- 2 台 Redis 服务器(新的硬件)
- 3 台标签引擎服务器(其中 2 台使用了新的硬件)
- 3 台 Elasticsearch 服务器(同上)
- 4 台 HAProxy 负载均衡服务器(添加了 2 台,用于支持 CloudFlare)
- 2 台网络设备(Nexus 5596 核心 + 2232TM Fabric Extender,所有设备都升级到 10Gbps 带宽)
- 2 台 Fortinet 800C 防火墙(取代了 Cisco 5525-X ASAs)
- 2 台 Cisco ASR-1001 路由器(取代了 Cisco 3945 路由器)
- 2 台 Cisco ASR-1001-x 路由器(新的!)
为了支撑Stack Overflow的运行,我们需要些什么?从 2013 年至今并没有太多的变化,不过因为优化以及上面提到的新硬件设备,我们现在只需要一台 web 服务器了。我们已经无意中测试过这种情况了,成功了好几次。请注意:我只是说这是可行的,我可没说这是个好主意。不过每次发生这种情况的时候都还挺有意思的。
现在我们已经对服务器缩放的想法有了一些基线数字,来看看我们是如何制作这些炫酷网页的。很少有系统是完全独立存在的(当然我们的也不例外),如果没有一个全局眼光能把这些部分集成在一起的话,架构规划的意义就要大打折扣了。我们的目标,就是把握全局。后续会有很多文章深入到每个特定的领域中。本文只是一个关于重点硬件的逻辑结构概要,下一篇文章会包含这些硬件的具体细节。
如果你们想看看今天这些硬件到底长什么样子的话,这里有几张在 2015 年 2 月升级服务器的时候,我拍摄的机柜A的照片(机柜B和它是完全一样的):


如果你想看更多这种东西的话,这里是那一周升级过程中完整的 256 张照片的相册(没错,这个数字就是故意的哈哈)。现在,让我们来深入架构布局。以下是现有的主要系统的逻辑架构概要:
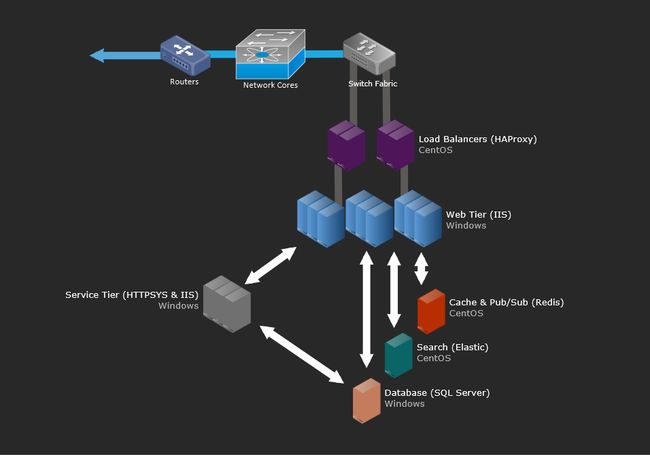
(点击看大图)
基本原则
以下是一些通行的原则,不需要再依次介绍它们了:
- 所有东西都有冗余备份。
- 所有的服务器和网络设备之间都至少有两个 10Gbps 带宽的连接。
- 所有服务器都有两路电源,通过两个 UPS 单元组、背后的两台发电机、两台电网电压前馈来提供电力。
- 所有服务器都有一个冗余备份分别位于机柜A和机柜B中。
- 所有服务器和服务都有双份的冗余备份,放在另外一个数据中心(位于科罗拉多),虽然这里我主要是在介绍纽约的情况。
- 所有东西都有冗余备份。
互联网
首先你得找到我们的网站,这是 DNS 的事儿。查找网站速度得快,所以我们现在把这事儿包给了 CloudFlare,因为他们有遍布在全球各个角落的 DNS 服务器。我们通过 API 来更新 DNS 记录,他们负责“管理”DNS。不过以我们的小人之心,因为还是有根深蒂固的信任问题,所以我们依然还是拥有自己的 DNS 服务器。当世界末日的时候——可能因为 GPL、Punyon(译注:Stack Overflow 团队的一员)或者缓存问题——而人们依然想要通过编程来转移注意力的话,我们就会切换到自己的 DNS 服务器。
你的浏览器找到了我们的藏身之所之后,来自我们四家网络服务供应商(纽约的 Level 3、Zayo、Cogent 和 Lightower)的 HTTP 流量就会进入我们四台先进的路由器之一。我们使用边界网关协议(BGP,非常标准的协议)来对等处理来自网络供应商的流量,以此来对其进行控制,并提供最高效的通路来访问我们的服务。这些 ASR-1001 和 ASR-1001-X 路由器被分为两组,每组应都使用双活的模式(active/active)来处理来自两家网络供应商的流量——在这里是有冗余备份的。虽然都是拥有同样的物理 10Gbps 的带宽,来自外部的流量还是和外部 VLAN 的流量独立开来,分别接入负载均衡。在流量通过路由器之后,你就会来到负载均衡器了。
我想现在可能是时候提到我们在两个数据中心之间拥有 10Gbps 带宽的 MPLS,虽然这其实和网站服务没什么直接关系。我们使用这种技术来进行数据的异地复制和快速恢复,来应对某些突发情况。“不过 Nick,这里面可没有冗余!”好吧,从技术角度上你说的没错(正面意义上的没错),在这个层面上它确实是单点故障。不过等等!通过网络供应商,我们还额外拥有两个 OSPF 故障转移路由(MPLS是第一选择,出于成本考虑这个是第二和第三选择)。之前提到的每组设备都会相应地接入科罗拉多的数据中心,在故障转移的情况下来对网络流量进行负载均衡。当然我们本可以让这两组设备互相之间都连接在一起,这样就有四组通路了,不过管它呢,让我们继续。
负载均衡(HAProxy)
负载均衡通过 HAProxy 1.5.15 实现,运行在 CentOS 7 上(我们最喜欢的 Linux 版本)。并在HAProxy上加入TLS(SSL)安全传输协议。我们还在密切关注 HAProxy 1.7,它马上就会提供对 HTTP/2 协议的支持。
和其他拥有双路 10Gbps LACP 网络连接的服务器不同,每台负载均衡都拥有两套 10Gbps 的连接:其中一套对应外部网络,另一套对应 DMZ。这些服务器拥有 64GB 或者更多的内存,来更有效地处理 SSL 协议层。当我们可以在内存中缓存和重用更多的 TLS 会话的时候,在连接到同一个客户端时就会少消耗一些计算资源。这意味着我们能够以更快、更便宜的方式来还原会话。内存是如此廉价,所以这是个很容易做出的抉择。
负载均衡本身搭建起来很容易。我们在多个不同的 IP(主要出于证书和 DNS 管理的考虑)上监听不同的网站,然后将流量路由到不同的后端(主要基于host header)。我们在这里做的唯一值得一提的事情就是限速和抓取部分 header 信息(来自 web 层)记录到 HAProxy 的系统日志消息中,通过这种方式我们可以记录每个请求的性能指标。我们会在后面详细提到这一点。
Web 层(IIS 8.5、ASP.Net MVC 5.2.3 和 .Net 4.6.1)
负载均衡将流量分配到 9 台我们所谓的主 web 服务器(01-09)中和 2 台开发 web 服务器(10-11,我们的测试环境)。主服务器运行着 Stack Overflow、Careers 以及所有的 Stack Exchange 网站,除此之外的 meta.stackoverflow.com 和 meta.stackexchange.com 在是运行在另外两台服务器上的。主要的 Q&A 应用本身就是多租户(multi-tenant)形式的,也就是说一个单独应用处理了所有 Q&A 网站的请求。换句话说,我们可以在一台服务器的一个应用程序池上,运行整个的 Q&A 应用。其它的应用比如 Careers、API v2、Mobile API 等等,都是独立的。下面是主服务器和开发服务器的 IIS 中看到的内容:
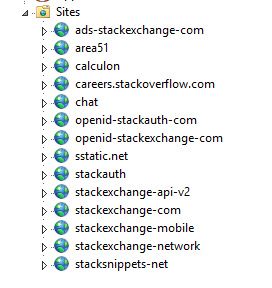
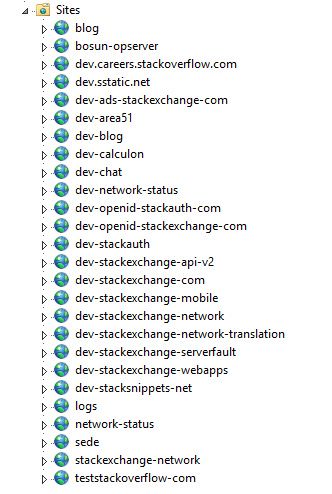
下面是在 Opserver(我们内部的监控仪表板)中看到的 Stack Overflow 的 web 层分布情况:
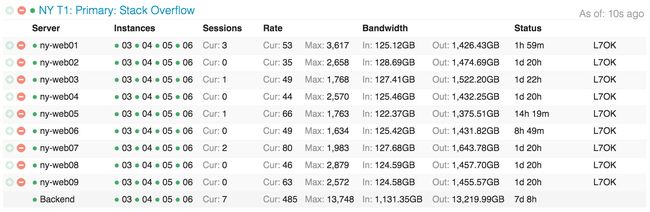
(点击查看大图)
还有下面这个是这些 web 服务器的资源消耗情况(译注:不是说好的 11 台么):
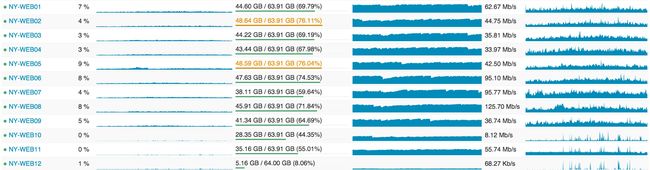
(点击查看大图)
我会在后续的文章中详细提到为什么我们过度提供了这么多资源,重点在于:滚动构建(rolling build)、留有余地、冗余。
服务层(IIS、ASP.Net MVC 5.2.3、.NET 4.6.1 和 HTTP.SYS)
紧挨着web层的是服务层。它们同样运行在 Windows 2012R2 的 IIS 8.5 之上。这一层运行一些内部服务,对生产环境的 web 层和其他内部系统提供支持。两个主要的服务包括:“Stack Server”,其中运行着标签引擎,是基于 http.sys的(背后并非是 IIS);Providence API(基于IIS)。一个有趣的事实:我不得不对着两个进程进行相关性设置,让它们连接到不同的 socket 上,因为 Stack Server 在以两分钟为间隔刷新问题列表的时候,会非常频繁的访问 L2 和 L3 级缓存。
运行这些服务的机器对于标签引擎和后端的 API 有着举足轻重的意义,因此它们必须是冗余的,不过并不需要 9 倍的冗余。举例来说,我们会每隔 n 分钟(目前是两分钟)就从数据库中加载所有文章及其标签,这个操作消耗并不低。我们可不想在 web 层把这个加载操作重复 9 次,3 次对我们来说就足够安全了。我们同样会对这些服务器采用不同的硬件配置,以便针对标签引擎和 elastic 索引作业(同样运行在这一层中)的计算和数据加载的特征进行更好的优化。“标签引擎”本身就是一个相对复杂的话题,会在专门的文章中进行介绍。基本的原理是:当你访问地址 /questions/tagged/java 的时候,你会访问标签引擎来获取与之匹配的问题。该引擎处理了除 /search 之外的所有标签匹配工作,所以包括新的导航在内的所有地方都是通过这个服务来获取数据的。
缓存 & 发布/订阅(Redis)
我们在一些地方使用了 Redis,它拥有坚如磐石般地稳定性。尽管每个月的操作有 1600 亿次之多,每个实例的 CPU 也不会超过 2%,通常会更低:
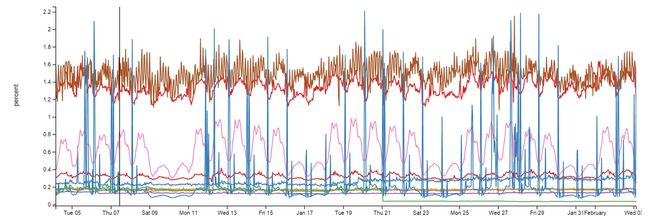
(点击查看大图)
我们借助 Redis 用于 L1/L2 级别的缓存系统。“L1”级是 HTTP 缓存,在 web 服务器或者任何类似的应用程序中起作用。“L2”级则是当上一级缓存失效之后,通过 Redis 获取数据。我们的数据是以 Protobuf 格式储存的,通过 Marc Gravell 编写的 protobuf-dot-net 实现。对于 Redis 客户端,我们使用了 StackExchange.Redis 库,这是一个内部开发的开源库。如果一台 web 服务器在 L1 和 L2 缓存中都没有命中,它就会从其数据源中获取数据(数据库查询、API 调用等等),然后将结果保存到本地缓存和 Redis 中。下一台服务器在获取同样数据的时候,可能会在 L1 缓存中缺失,但是它会在 L2/Redis 中获取到数据,省去了数据库查询或者 API 调用的操作。
我们同样运行着很多 Q&A 站点,每个站点都有其自己的 L1/L2 缓存:在 L1 缓存中使用 key 作为前缀,在 L2/Redis 缓存中使用数据库 ID。我们会在未来的文章中深入探讨这个话题。
除了运行着所有站点实例的两台主要的 Redis 服务器(一主一从)之外,我们还利用另外两台专用的从服务器搭建了一个用于机器学习的的实例(主要出于内存考虑)。这组服务器用来提供首页上的问题推荐、做出更优的工作职位匹配等服务。这个平台称为 Providence,Kevin Montrose 曾撰文描述过它。
主要的 Redis 服务器拥有 256GB 内存(大约使用了 90GB),Providence 服务器拥有 384GB 内存(大约使用了 125GB)。
Redis 并非只用来做缓存,它同样拥有一套发布和订阅机制,一台服务器可以发布一条消息,其他的订阅服务器可以收到该消息(包括 Redis 从服务器上的下游客户端)。我们利用这个机制来清除其他服务上的 L1 缓存,用来保持 web 服务器上的缓存一致性。不过它还有另外一个重要的用途:websocket。
Websockets(NetGain)
我们使用 websocket 向用户推送实时的更新内容,比如顶部栏中的通知、投票数、新导航数、新的答案和评论等等。
socket 服务器本身在 web 层上运行,使用原生的 socket。这是一个基于我们的开源库实现的非常小型的应用程序:StackExchange.NetGain。在高峰时刻,我们大约有 50 万个并发的 websocket 连接,这可是一大堆浏览器。一个有趣的事实:其中一些浏览器已经打开超过 18 个月了,得找人去看看那些开发者是不是还活着。下面这张图是本周 websocket 并发量的模式:
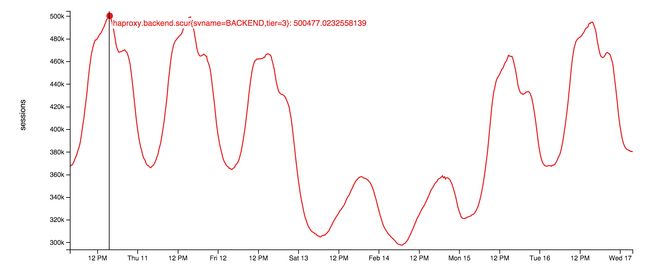
(点击查看大图)
为什么用 websocket?在我们这个规模下,它比轮询要有效率得多。通过这种方式,我们可以简单地使用更少资源来推送更多数据,而且对用户而言实时性也更高。不过这种方式也并非没有问题:临时端口、负载均衡上的文件句柄耗尽,都是非常有趣的问题,我们稍后会提到它们。
搜索(Elasticsearch)
剧透:这里没多少让人兴奋的东西。web层使用了Elasticsearch 1.4 ,并实现了超轻量级、高性能的 StackExchange.Elastic 客户端。和大多数东西不同的是,我们并没有计划把这部分内容开源,简单来说,是因为它只暴露了非常少量的我们需要使用的 API 的子集。我确信把它公开出来是得不偿失的,只会让开发者感到困惑。我们在这些地方用到了 elastic:/search、计算相关问题、提问时给出相关建议。
每个 Elastic 集群(每个数据中心各有一个)包含 3 个节点,每个站点都拥有各自的索引。Careers 站点还有一些额外的索引。在 elastic 圈子里,我们的配置中稍微不那么标准的地方是,我们 3 台服务器的集群比通常的配置要更强大一些:每台服务器都使用了 SSD 存储、192GB 内存、双路 10Gbps 带宽的网络。
在 Stack Server 的同一个应用程序域(没错,我们在这个地方被 .Net Core 折腾惨了)里面还宿主着标签引擎,它同样使用了 Elasticsearch 进行连续索引。这里我们用了些小花招,比如使用 SQL Server(数据来源)中的 ROWVERSION 和 Elastic 中的“最后位置”文档进行比较。因为从表观上看它是顺序的,这样如果内容在最后一次访问后被修改的话,我们就很容易对其进行抓取和索引了。
我们使用 Elasticsearch 代替如 SQL 全文检索这类技术的主要原因,就是它的可扩展性和性价比。SQL 的 CPU 相对而言非常昂贵,而 Elastic 则便宜得多,并且最近有了非常多的新特性。为什么不用 Solr?我们需要在整个网络中进行搜索(同时有多个索引),在我们进行决策的时候 Solr 还不支持这种场景。我们还没有使用 2.x 版本的原因,是因为 2.x 版本中类型(types)有了很大的变化,这意味着想要升级的话我们得重新索引所有内容。我只是没有足够的时间来制定需求变更和迁移的计划。
数据库(SQL Server)
我们使用 SQL Server 作为单一的数据源(single source of truth)。Elastic 和 Redis 中的所有数据都来自 SQL Server。我们有两个 SQL Server 集群,并配置了 AlwaysOn 可用性组。每个集群都在纽约有一台主服务器(承担了几乎全部负载)和一台副本服务器,此外还有一个在科罗拉多(我们的灾备数据中心)的副本服务器。所有的复制操作都是异步的。
第一个集群是一组 Dell R720xd 服务器,每台拥有 384GB 内存,4TB 空间的 PCIe SSD,和两个 12 核 CPU。它包含了 Stack Overflow、Sites(这是个坏名字,稍后我会解释它)、PRIZM 以及 Mobile 的数据库。
第二个集群是一组 Dell R730xd 服务器,每台拥有 768GB 内存,6TB 空间的 PCIe SSD,和两个 8 核 CPU。这个集群包含了所有其它数据库,包括 Careers、Open ID、Chat、异常日志,以及其他的 Q&A 网站(比如 Super User、Server Fault 等)。
在数据库层上,我们希望让 CPU 利用率保持在一个非常低的级别,不过实际上在一些计划缓存问题(我们正在排查)发生的时候,CPU 占用率会稍高一些。目前,NY-SQL02 和 04 是主服务器,01 和 03 是副本服务器,我们今天因为 SSD 升级刚刚重启过它们。以下是它们在过去 24 小时内的表现:

(点击查看大图)
我们对 SQL 的使用非常简单。简单就意味着快速。虽然有些查询语句会很变态,我们对 SQL 本身的交互还是通过相当原生的方式进行的。我们有一些遗留的 Linq2Sql,不过所有新开发的内容都使用了 Dapper,这是我们开源的微型 ORM 框架,使用了 POCO。让我换一种方式来解释一下:Stack Overflow 的数据库中只有一个存储过程,而且我打算把这个最后残留的存储过程也干掉,换成代码。
库
好吧让我们换个思路,这里是更直接能帮到你的东西。在前面我已经提到过一些了,不过我会给出一个列表,其中包含了很多由我们维护的、大家都在使用的开源 .Net 类库。我们把它们开源,因为其中并不涉及到核心的商业价值,但是可以帮助世界上的开发者们。我希望你们如今能用到它们:
- Dapper (.Net Core) – 高性能的微型 ORM 框架,用于 ADO.Net
- StackExchange.Redis – 高性能的 Redis 客户端
- MiniProfiler – 轻量的分析探查器(profiler),我们在每个页面上都使用了它(同样支持 Ruby、Go 和 Node)
- Exceptional – 用于 SQL、JSON、MySQL 等的错误日志记录
- Jil – 高性能的 JSON 序列化和反序列化器
- Sigil – .Net CIL 生成帮助器(在 C# 不够快的时候使用)
- NetGain – 高性能的 websocket 服务器
- Opserver – 监控仪表板,可以直接轮询大多数系统,并且可以从 Orion、Bosun 或 WMI 中获取信息
- Bosun – 后台的监控系统,使用 Go 编写
下一篇内容:目前我们所使用硬件的详细配置清单。再之后,我们会按照列表依次撰文。敬请期待。
来源:http://blog.jobbole.com/98633/