Apache Calcite VolcanoPlanner源码学习
calcite VolcanoPlanner是基于Cascades模型的自顶向下的查询优化器,具体模型细节可以参见Cascade模型,Volcano模型
在这里以举例的方式解释VolcanoPlanner的整体工作流程
// SqlVolcanoTest.java
public class SqlVolcanoTest {
private static final Logger LOGGER = LoggerFactory.getLogger(SqlVolcanoTest.class);
public static void main(String[] args) {
SchemaPlus rootSchema = CalciteUtils.registerRootSchema();
final FrameworkConfig frameworkConfig = Frameworks.newConfigBuilder()
.parserConfig(SqlParser.Config.DEFAULT)
.defaultSchema(rootSchema)
.traitDefs(ConventionTraitDef.INSTANCE, RelDistributionTraitDef.INSTANCE)
.build();
String sql
= "select u.id as user_id, u.name as user_name, j.company as user_company, u.age as user_age from users u"
+ " join jobs j on u.id=j.id where u.age > 30 and j.id>10 order by user_id";
// use HepPlanner
VolcanoPlanner planner = new VolcanoPlanner();
planner.addRelTraitDef(ConventionTraitDef.INSTANCE);
planner.addRelTraitDef(RelDistributionTraitDef.INSTANCE);
// add rules
planner.addRule(FilterJoinRule.FilterIntoJoinRule.FILTER_ON_JOIN);
planner.addRule(ReduceExpressionsRule.PROJECT_INSTANCE);
planner.addRule(PruneEmptyRules.PROJECT_INSTANCE);
// add ConverterRule
planner.addRule(EnumerableRules.ENUMERABLE_MERGE_JOIN_RULE);
planner.addRule(EnumerableRules.ENUMERABLE_SORT_RULE);
planner.addRule(EnumerableRules.ENUMERABLE_VALUES_RULE);
planner.addRule(EnumerableRules.ENUMERABLE_PROJECT_RULE);
planner.addRule(EnumerableRules.ENUMERABLE_FILTER_RULE);
try {
SqlTypeFactoryImpl factory = new SqlTypeFactoryImpl(RelDataTypeSystem.DEFAULT);
// sql parser
SqlParser parser = SqlParser.create(sql, SqlParser.Config.DEFAULT);
SqlNode parsed = parser.parseStmt();
LOGGER.info("The SqlNode after parsed is:\n{}", parsed.toString());
CalciteCatalogReader calciteCatalogReader = new CalciteCatalogReader(
CalciteSchema.from(rootSchema),
CalciteSchema.from(rootSchema).path(null),
factory,
new CalciteConnectionConfigImpl(new Properties()));
// sql validate
SqlValidator validator = SqlValidatorUtil.newValidator(SqlStdOperatorTable.instance(), calciteCatalogReader,
factory, CalciteUtils.conformance(frameworkConfig));
SqlNode validated = validator.validate(parsed);
LOGGER.info("The SqlNode after validated is:\n{}", validated.toString());
final RexBuilder rexBuilder = CalciteUtils.createRexBuilder(factory);
final RelOptCluster cluster = RelOptCluster.create(planner, rexBuilder);
// init SqlToRelConverter config
final SqlToRelConverter.Config config = SqlToRelConverter.configBuilder()
.withConfig(frameworkConfig.getSqlToRelConverterConfig())
.withTrimUnusedFields(false)
.withConvertTableAccess(false)
.build();
// SqlNode toRelNode
final SqlToRelConverter sqlToRelConverter = new SqlToRelConverter(new CalciteUtils.ViewExpanderImpl(),
validator, calciteCatalogReader, cluster, frameworkConfig.getConvertletTable(), config);
RelRoot root = sqlToRelConverter.convertQuery(validated, false, true);
root = root.withRel(sqlToRelConverter.flattenTypes(root.rel, true));
final RelBuilder relBuilder = config.getRelBuilderFactory().create(cluster, null);
root = root.withRel(RelDecorrelator.decorrelateQuery(root.rel, relBuilder));
RelNode relNode = root.rel;
LOGGER.info("The relational expression string before optimized is:\n{}", RelOptUtil.toString(relNode));
RelTraitSet desiredTraits =
relNode.getCluster().traitSet().replace(EnumerableConvention.INSTANCE);
relNode = planner.changeTraits(relNode, desiredTraits);
planner.setRoot(relNode);
relNode = planner.findBestExp();
System.out.println("-----------------------------------------------------------");
System.out.println("The Best relational expression string:");
System.out.println(RelOptUtil.toString(relNode));
System.out.println("-----------------------------------------------------------");
} catch (Exception e) {
e.printStackTrace();
}
}
}
// CalciteUtils.java
public class CalciteUtils {
public static SchemaPlus registerRootSchema() {
SchemaPlus rootSchema = Frameworks.createRootSchema(true);
rootSchema.add("USERS", new AbstractTable() { //note: add a table
@Override
public RelDataType getRowType(final RelDataTypeFactory typeFactory) {
RelDataTypeFactory.Builder builder = typeFactory.builder();
builder.add("ID", new BasicSqlType(new RelDataTypeSystemImpl() {}, SqlTypeName.INTEGER));
builder.add("NAME", new BasicSqlType(new RelDataTypeSystemImpl() {}, SqlTypeName.CHAR));
builder.add("AGE", new BasicSqlType(new RelDataTypeSystemImpl() {}, SqlTypeName.INTEGER));
return builder.build();
}
});
rootSchema.add("JOBS", new AbstractTable() {
@Override
public RelDataType getRowType(final RelDataTypeFactory typeFactory) {
RelDataTypeFactory.Builder builder = typeFactory.builder();
builder.add("ID", new BasicSqlType(new RelDataTypeSystemImpl() {}, SqlTypeName.INTEGER));
builder.add("NAME", new BasicSqlType(new RelDataTypeSystemImpl() {}, SqlTypeName.CHAR));
builder.add("COMPANY", new BasicSqlType(new RelDataTypeSystemImpl() {}, SqlTypeName.CHAR));
return builder.build();
}
});
return rootSchema;
}
public static SqlConformance conformance(FrameworkConfig config) {
final Context context = config.getContext();
if (context != null) {
final CalciteConnectionConfig connectionConfig =
context.unwrap(CalciteConnectionConfig.class);
if (connectionConfig != null) {
return connectionConfig.conformance();
}
}
return SqlConformanceEnum.DEFAULT;
}
public static RexBuilder createRexBuilder(RelDataTypeFactory typeFactory) {
return new RexBuilder(typeFactory);
}
public static class ViewExpanderImpl implements RelOptTable.ViewExpander {
public ViewExpanderImpl() {
}
@Override
public RelRoot expandView(RelDataType rowType, String queryString, List<String> schemaPath,
List<String> viewPath) {
return null;
}
}
}
Table USERS
ID(INTEGER) NAME(CHAR) AGE(INTEGER)
Table JOBS
ID(INTEGER) NAME(CHAR) COMPANY(CHAR)
上述代码摘自Matt Blog calcite-example
优化前的逻辑执行计划如下所示:
LogicalSort(sort0=[$0], dir0=[ASC])
LogicalProject(USER_ID=[$0], USER_NAME=[$1], USER_COMPANY=[$5], USER_AGE=[$2])
LogicalFilter(condition=[AND(>($2, 30), >($3, 10))])
LogicalJoin(condition=[=($0, $3)], joinType=[inner])
EnumerableTableScan(table=[[USERS]])
EnumerableTableScan(table=[[JOBS]])
Enumerable是calcite中的一种calling convention trait,官方解释如下
Calcite includes common traits that describe the physical
properties of the data produced by a relational expression,
such as ordering, grouping, and partitioning. In addition to
these properties, one of the main features of Calcite is the
calling convention trait. Essentially, the trait represents
the data processing system where the expression will be executed.
This table scan operator contains the necessary information
the adapter requires to issue the scan to the adapter’s backend
database. To extend the functionality provided by adapters,
Calcite defines an enumerable calling convention. Relational
operators with the enumerable calling convention simply operate
over tuples via an iterator interface. This calling convention
allows Calcite to implement operators which may not be available
in each adapter’s backend.
EnumerableTableScan表示通过iterator的方式从底层数据处理系统获取Table数据。
在获得了初始逻辑执行计划之后,需要调用VolcanoPlanner对其进行优化,optimization planner优化分为两部分:
- setRoot
- findBestExpr
setRoot
// VolcanoPlanner.java
public void setRoot(RelNode rel) {
// We're registered all the rules, and therefore RelNode classes,
// we're interested in, and have not yet started calling metadata providers.
// So now is a good time to tell the metadata layer what to expect.
registerMetadataRels();
this.root = registerImpl(rel, null);
if (this.originalRoot == null) {
this.originalRoot = rel;
}
// Making a node the root changes its importance.
this.ruleQueue.recompute(this.root);
ensureRootConverters();
}
private RelSubset registerImpl(
RelNode rel,
RelSet set) {
if (rel instanceof RelSubset) {
return registerSubset(set, (RelSubset) rel);
}
assert !isRegistered(rel) : "already been registered: " + rel;
if (rel.getCluster().getPlanner() != this) {
throw new AssertionError("Relational expression " + rel
+ " belongs to a different planner than is currently being used.");
}
// Now is a good time to ensure that the relational expression
// implements the interface required by its calling convention.
final RelTraitSet traits = rel.getTraitSet();
final Convention convention = traits.getTrait(ConventionTraitDef.INSTANCE);
assert convention != null;
if (!convention.getInterface().isInstance(rel)
&& !(rel instanceof Converter)) {
throw new AssertionError("Relational expression " + rel
+ " has calling-convention " + convention
+ " but does not implement the required interface '"
+ convention.getInterface() + "' of that convention");
}
if (traits.size() != traitDefs.size()) {
throw new AssertionError("Relational expression " + rel
+ " does not have the correct number of traits: " + traits.size()
+ " != " + traitDefs.size());
}
// Ensure that its sub-expressions are registered.
rel = rel.onRegister(this);
// Record its provenance. (Rule call may be null.)
if (ruleCallStack.isEmpty()) {
provenanceMap.put(rel, Provenance.EMPTY);
} else {
final VolcanoRuleCall ruleCall = ruleCallStack.peek();
provenanceMap.put(
rel,
new RuleProvenance(
ruleCall.rule,
ImmutableList.copyOf(ruleCall.rels),
ruleCall.id));
}
// If it is equivalent to an existing expression, return the set that
// the equivalent expression belongs to.
Pair<String, RelDataType> key = key(rel);
RelNode equivExp = mapDigestToRel.get(key);
if (equivExp == null) {
// do nothing
} else if (equivExp == rel) {
return getSubset(rel);
} else {
assert RelOptUtil.equal(
"left", equivExp.getRowType(),
"right", rel.getRowType(),
Litmus.THROW);
RelSet equivSet = getSet(equivExp);
if (equivSet != null) {
LOGGER.trace(
"Register: rel#{} is equivalent to {}", rel.getId(), equivExp.getDescription());
return registerSubset(set, getSubset(equivExp));
}
}
// Converters are in the same set as their children.
if (rel instanceof Converter) {
final RelNode input = ((Converter) rel).getInput();
final RelSet childSet = getSet(input);
if ((set != null)
&& (set != childSet)
&& (set.equivalentSet == null)) {
LOGGER.trace(
"Register #{} {} (and merge sets, because it is a conversion)",
rel.getId(), rel.getDigest());
merge(set, childSet);
registerCount++;
// During the mergers, the child set may have changed, and since
// we're not registered yet, we won't have been informed. So
// check whether we are now equivalent to an existing
// expression.
if (fixUpInputs(rel)) {
rel.recomputeDigest();
key = key(rel);
RelNode equivRel = mapDigestToRel.get(key);
if ((equivRel != rel) && (equivRel != null)) {
// make sure this bad rel didn't get into the
// set in any way (fixupInputs will do this but it
// doesn't know if it should so it does it anyway)
set.obliterateRelNode(rel);
// There is already an equivalent expression. Use that
// one, and forget about this one.
return getSubset(equivRel);
}
}
} else {
set = childSet;
}
}
// Place the expression in the appropriate equivalence set.
if (set == null) {
set = new RelSet(
nextSetId++,
Util.minus(
RelOptUtil.getVariablesSet(rel),
rel.getVariablesSet()),
RelOptUtil.getVariablesUsed(rel));
this.allSets.add(set);
}
// Chain to find 'live' equivalent set, just in case several sets are
// merging at the same time.
while (set.equivalentSet != null) {
set = set.equivalentSet;
}
// Allow each rel to register its own rules.
registerClass(rel);
registerCount++;
final int subsetBeforeCount = set.subsets.size();
RelSubset subset = addRelToSet(rel, set);
final RelNode xx = mapDigestToRel.put(key, rel);
assert xx == null || xx == rel : rel.getDigest();
LOGGER.trace("Register {} in {}", rel.getDescription(), subset.getDescription());
// This relational expression may have been registered while we
// recursively registered its children. If this is the case, we're done.
if (xx != null) {
return subset;
}
// Create back-links from its children, which makes children more
// important.
if (rel == this.root) {
ruleQueue.subsetImportances.put(
subset,
1.0); // todo: remove
}
for (RelNode input : rel.getInputs()) {
RelSubset childSubset = (RelSubset) input;
childSubset.set.parents.add(rel);
// Child subset is more important now a new parent uses it.
ruleQueue.recompute(childSubset);
}
if (rel == this.root) {
ruleQueue.subsetImportances.remove(subset);
}
// Remember abstract converters until they're satisfied
if (rel instanceof AbstractConverter) {
set.abstractConverters.add((AbstractConverter) rel);
}
// If this set has any unsatisfied converters, try to satisfy them.
checkForSatisfiedConverters(set, rel);
// Make sure this rel's subset importance is updated
ruleQueue.recompute(subset, true);
// Queue up all rules triggered by this relexp's creation.
fireRules(rel, true);
// It's a new subset.
if (set.subsets.size() > subsetBeforeCount) {
fireRules(subset, true);
}
return subset;
}
setRoot调用registerImpl进行相应的注册工作:
- 将relNode转化成RelSubset并添加到相应的RelSet中,RelSubset表示具有相同物理属性的等价关系表达式子集(物理属性由Traits进行描述),RelSet表示一组等价集合,一个RelSet中可以有多个具有不同物理属性的RelSubset。等价集合的概念可以参见SQL 查询优化原理与 Volcano Optimizer 介绍
- 计算relSubSet的Importance(Importance表示后面进行规则应用时的优先级,Importance越高,对应的规则越优先应用)
// RuleQueue.java
// childImportance = max(childCost / parentCost * parentImportance)
double computeImportance(RelSubset subset) {
double importance;
if (subset == planner.root) {
// The root always has importance = 1
importance = 1.0;
} else {
final RelMetadataQuery mq = subset.getCluster().getMetadataQuery();
// The importance of a subset is the max of its importance to its
// parents
importance = 0.0;
for (RelSubset parent : subset.getParentSubsets(planner)) {
final double childImportance =
computeImportanceOfChild(mq, subset, parent);
importance = Math.max(importance, childImportance);
}
}
LOGGER.trace("Importance of [{}] is {}", subset, importance);
return importance;
}
private double computeImportanceOfChild(RelMetadataQuery mq, RelSubset child,
RelSubset parent) {
final double parentImportance = getImportance(parent);
final double childCost = toDouble(planner.getCost(child, mq));
final double parentCost = toDouble(planner.getCost(parent, mq));
double alpha = childCost / parentCost;
if (alpha >= 1.0) {
// child is always less important than parent
alpha = 0.99;
}
final double importance = parentImportance * alpha;
LOGGER.trace("Importance of [{}] to its parent [{}] is {} (parent importance={}, child cost={},"
+ " parent cost={})", child, parent, importance, parentImportance, childCost, parentCost);
return importance;
}
double getImportance(RelSubset rel) {
assert rel != null;
double importance = 0;
final RelSet set = planner.getSet(rel);
assert set != null;
for (RelSubset subset2 : set.subsets) {
final Double d = subsetImportances.get(subset2);
if (d == null) {
continue;
}
double subsetImportance = d;
if (subset2 != rel) {
subsetImportance /= 2;
}
if (subsetImportance > importance) {
importance = subsetImportance;
}
}
return importance;
}
- 得到与relNode相匹配的rule,将该ruleMatch添加到ruleQueue中
在这里我们详细看一下获得ruleMatch,并将ruleMatch添加到ruleQueue的过程:
- 首先调用registerClass,registerClass最终调用onNewClass将所有可能可以应用到该relNode的rule operand保存到classOperands
@Override protected void onNewClass(RelNode node) {
super.onNewClass(node);
// Create mappings so that instances of this class will match existing
// operands.
final Class<? extends RelNode> clazz = node.getClass();
for (RelOptRule rule : ruleSet) {
for (RelOptRuleOperand operand : rule.getOperands()) {
if (operand.getMatchedClass().isAssignableFrom(clazz)) {
classOperands.put(clazz, operand);
}
}
}
}
- 获得classOperands之后,fireRules判断该规则是否可以应用于相应的relNode,如果规则与relNode相匹配,则调用onMatch,onMatch将ruleMatch添加到ruleQueue中
// VolcanoPlanner.java
protected void onMatch() {
final VolcanoRuleMatch match =
new VolcanoRuleMatch(
volcanoPlanner,
getOperand0(),
rels,
nodeInputs);
volcanoPlanner.ruleQueue.addMatch(match);
}
}
findBestExpr
// VolcanoPlanner.java
public RelNode findBestExp() {
ensureRootConverters();
registerMaterializations();
int cumulativeTicks = 0;
for (VolcanoPlannerPhase phase : VolcanoPlannerPhase.values()) {
setInitialImportance();
RelOptCost targetCost = costFactory.makeHugeCost();
int tick = 0;
int firstFiniteTick = -1;
int splitCount = 0;
int giveUpTick = Integer.MAX_VALUE;
while (true) {
++tick;
++cumulativeTicks;
if (root.bestCost.isLe(targetCost)) {
if (firstFiniteTick < 0) {
firstFiniteTick = cumulativeTicks;
clearImportanceBoost();
}
if (ambitious) {
// Choose a slightly more ambitious target cost, and
// try again. If it took us 1000 iterations to find our
// first finite plan, give ourselves another 100
// iterations to reduce the cost by 10%.
targetCost = root.bestCost.multiplyBy(0.9);
++splitCount;
if (impatient) {
if (firstFiniteTick < 10) {
// It's possible pre-processing can create
// an implementable plan -- give us some time
// to actually optimize it.
giveUpTick = cumulativeTicks + 25;
} else {
giveUpTick =
cumulativeTicks
+ Math.max(firstFiniteTick / 10, 25);
}
}
} else {
break;
}
} else if (cumulativeTicks > giveUpTick) {
// We haven't made progress recently. Take the current best.
break;
} else if (root.bestCost.isInfinite() && ((tick % 10) == 0)) {
injectImportanceBoost();
}
LOGGER.debug("PLANNER = {}; TICK = {}/{}; PHASE = {}; COST = {}",
this, cumulativeTicks, tick, phase.toString(), root.bestCost);
VolcanoRuleMatch match = ruleQueue.popMatch(phase);
if (match == null) {
break;
}
assert match.getRule().matches(match);
match.onMatch();
// The root may have been merged with another
// subset. Find the new root subset.
root = canonize(root);
}
ruleQueue.phaseCompleted(phase);
}
if (LOGGER.isTraceEnabled()) {
StringWriter sw = new StringWriter();
final PrintWriter pw = new PrintWriter(sw);
dump(pw);
pw.flush();
LOGGER.trace(sw.toString());
}
RelNode cheapest = root.buildCheapestPlan(this);
if (LOGGER.isDebugEnabled()) {
LOGGER.debug(
"Cheapest plan:\n{}", RelOptUtil.toString(cheapest, SqlExplainLevel.ALL_ATTRIBUTES));
if (!provenanceMap.isEmpty()) {
LOGGER.debug("Provenance:\n{}", provenance(cheapest));
}
}
return cheapest;
}
findBestExpr主要分为3个部分:
- setInitialImportance: 初始化RelSubset Tree中RelSubset节点的Importance, Importance = pow(0.9, depth)
- ruleQueue.popMatch: 将ruleQueue中Importance最大的ruleMatch弹出
- match.onMatch:应用rule优化执行计划
以Test为例初始化RelSubSet Tree如下所示:
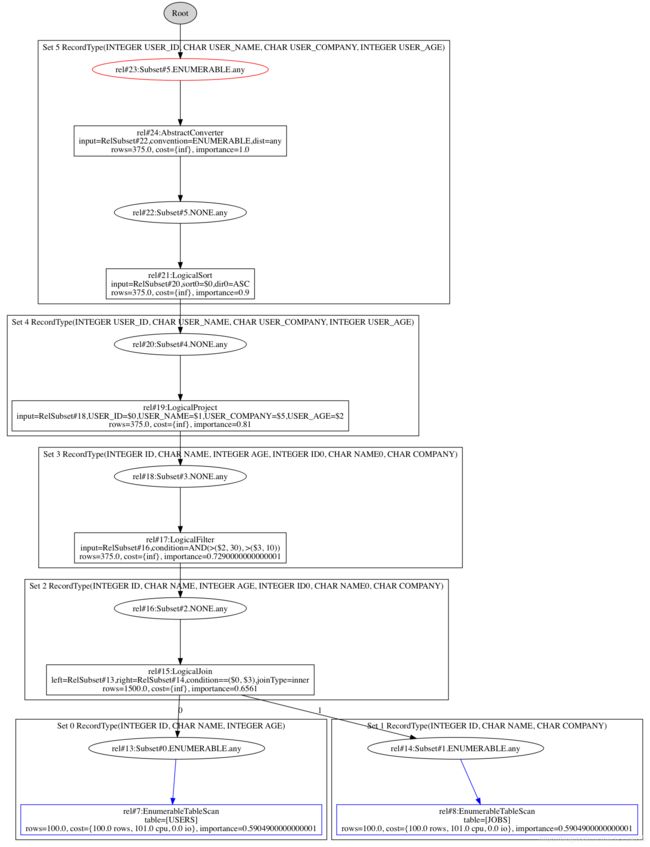
其中蓝框表示该RelSubset中的最优RelNode(也就是该RelNode的cost最小),红框表示该RelSubSet没有与任何RelNode绑定,或该RelSubSet绑定的RelNode为converter
此时ruleQueue中的ruleMatch如下所示:
rule [EnumerableSortRule(in:NONE,out:ENUMERABLE)] rels [rel#21:LogicalSort.NONE.any(input=RelSubset#20,sort0=$0,dir0=ASC)] importance 0.9
rule [ReduceExpressionsRule(Project)] rels [rel#19:LogicalProject.NONE.any(input=RelSubset#18,USER_ID=$0,USER_NAME=$1,USER_COMPANY=$5,USER_AGE=$2)] importance 0.81
rule [EnumerableProjectRule(in:NONE,out:ENUMERABLE)] rels [rel#19:LogicalProject.NONE.any(input=RelSubset#18,USER_ID=$0,USER_NAME=$1,USER_COMPANY=$5,USER_AGE=$2)] importance 0.81
rule [FilterJoinRule:FilterJoinRule:filter] rels [rel#17:LogicalFilter.NONE.any(input=RelSubset#16,condition=AND(>($2, 30), >($3, 10))), rel#15:LogicalJoin.NONE.any(left=RelSubset#13,right=RelSubset#14,condition==($0, $3),joinType=inner)] importance 0.7290000000000001
rule [EnumerableFilterRule(in:NONE,out:ENUMERABLE)] rels [rel#17:LogicalFilter.NONE.any(input=RelSubset#16,condition=AND(>($2, 30), >($3, 10)))] importance 0.7290000000000001
rule [EnumerableMergeJoinRule(in:NONE,out:ENUMERABLE)] rels [rel#15:LogicalJoin.NONE.any(left=RelSubset#13,right=RelSubset#14,condition==($0, $3),joinType=inner)] importance 0.6561
由于EnumerableSortRule ruleMatch的Importance为0.9最大,所以首先弹出EnumerableSortRule调用onMatch对RelSubSet Tree进行优化
// ConvertRule.java
public void onMatch(RelOptRuleCall call) {
RelNode rel = call.rel(0);
if (rel.getTraitSet().contains(inTrait)) {
final RelNode converted = convert(rel);
if (converted != null) {
call.transformTo(converted);
}
}
}
convert根据rule得到新的等价relNode,call.transformTo将新生成的relNode调用registerImpl函数,将新生成的relNode添加到RelSubSet Tree中,并将相应的ruleMatch添加到ruleQueue中。经过EnumerableSortRule优化后的RelSubSet Tree如下图所示:
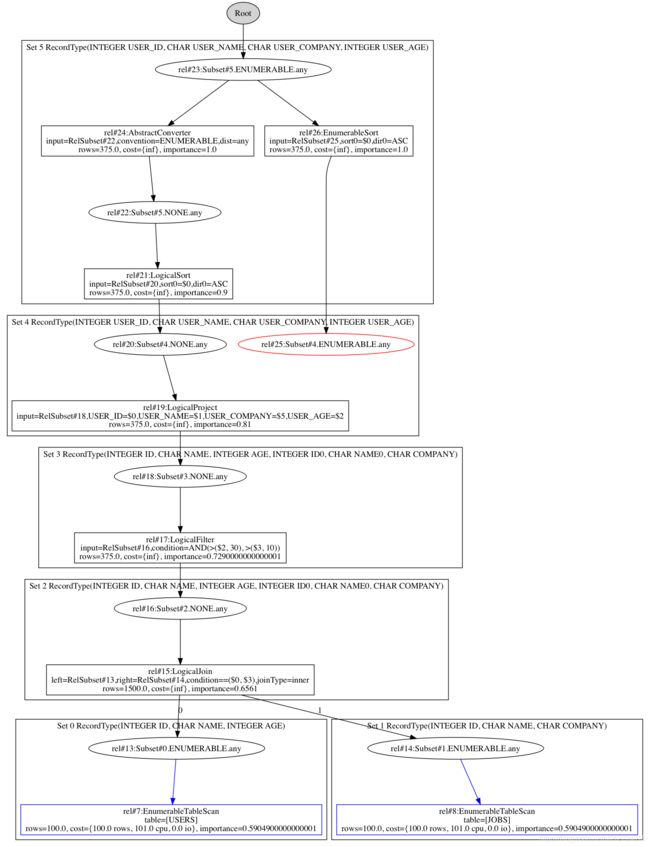
重复上述步骤,可以得到如下图所示的RelSubSet Tree
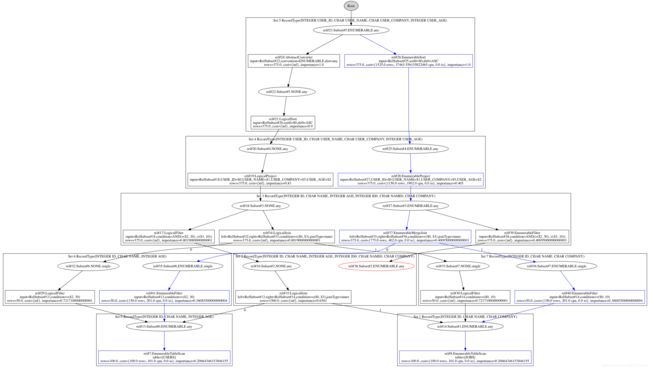
通过蓝色路径我们得到一个优化后的逻辑执行计划
EnumerableSort(subset=[rel#23:Subset#5.ENUMERABLE.any], sort0=[$0], dir0=[ASC]): rowcount = 375.0, cumulative cost = {375.0 rows, 35561.556155822465 cpu, 0.0 io}, id = 26
EnumerableProject(subset=[rel#25:Subset#4.ENUMERABLE.any], USER_ID=[$0], USER_NAME=[$1], USER_COMPANY=[$5], USER_AGE=[$2]): rowcount = 375.0, cumulative cost = {375.0 rows, 1500.0 cpu, 0.0 io}, id = 28
EnumerableMergeJoin(subset=[rel#27:Subset#3.ENUMERABLE.any], condition=[=($0, $3)], joinType=[inner]): rowcount = 375.0, cumulative cost = {475.0 rows, 0.0 cpu, 0.0 io}, id = 37
EnumerableFilter(subset=[rel#35:Subset#6.ENUMERABLE.single], condition=[>($2, 30)]): rowcount = 50.0, cumulative cost = {50.0 rows, 100.0 cpu, 0.0 io}, id = 41
EnumerableTableScan(subset=[rel#13:Subset#0.ENUMERABLE.any], table=[[USERS]]): rowcount = 100.0, cumulative cost = {100.0 rows, 101.0 cpu, 0.0 io}, id = 7
EnumerableFilter(subset=[rel#36:Subset#7.ENUMERABLE.single], condition=[>($0, 10)]): rowcount = 50.0, cumulative cost = {50.0 rows, 100.0 cpu, 0.0 io}, id = 40
EnumerableTableScan(subset=[rel#14:Subset#1.ENUMERABLE.any], table=[[JOBS]]): rowcount = 100.0, cumulative cost = {100.0 rows, 101.0 cpu, 0.0 io}, id = 8
但是这个执行计划不一定是最优执行计划,findBestExpr会重新计算targetCost:
targetCost = root.bestCost.multiplyBy(0.9);
继续进行优化直到满足以下条件中的任意一条而停止优化:
- 优化迭代次数超过giveUpTick
- 没有可用rule进行优化
最终我们得到如下所示的RelSubSet Tree
通过该RelSubSet Tree,buildCheapestPlan得到蓝线所示的最优执行路径,返回该路径表示的逻辑执行计划
EnumerableSort(sort0=[$0], dir0=[ASC])
EnumerableProject(USER_ID=[$0], USER_NAME=[$1], USER_COMPANY=[$5], USER_AGE=[$2])
EnumerableMergeJoin(condition=[=($0, $3)], joinType=[inner])
EnumerableFilter(condition=[>($2, 30)])
EnumerableTableScan(table=[[USERS]])
EnumerableFilter(condition=[>($0, 10)])
EnumerableTableScan(table=[[JOBS]])