LevelDB之LRUCaChe解析
背景:
之前学过操作系统的都应该知道LRU Cache算法,即最近最少使用算法。算法的缘由是Cache的容量有限,不可能无限制的去存储数据,那么在容量用完又需要添加新的数据时,就需要在原cache当中选择一些数据清除掉,而我们选择的数据就是那些最近最少使用的数据(实际上在我看来,说是最久未使用算法更形象,因为该算法每次替换掉的就是一段时间内最久没有使用过的内容)
技术实现:
LRU一般的实现是hash map + 双向链表,hash map是为了在cache当中寻找数据的时候能够以O(1)的时间复杂度去返回找寻的结果。而双向链表就是用于实现最近最少使用的思想,当每次数据被访问时,就将其插入到双向链表的头部。那么越接近头部的数据,就越是最近被使用过的数据,越靠近双向尾部的数据,就越是最久未被使用的数据,尾部的数据就是我们未来需要删除的对象。在cache容量满了而需要删除数据的时候,只需要从尾部开始遍历双向链表,将数据清除掉,就达到了剔除的是最近最少使用数据的目的。
现在举个例子,假设头节点为head,1被使用过,此时1是最近被使用过的数据,将其插入到head的next。

此时1是最近被使用过的,然后又使用了数2,又将其插入到头部,那么如下所示:
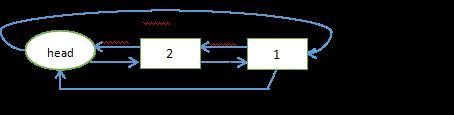
那么2是最新被使用的数据,1次之。那么删除的时候就先选最久未被使用的1。这就是最近最少使用的核心概念。
LevelDB的LRUCache的实现:
先看类的实现框架
// A single shard of sharded cache.
class LRUCache {
public:
LRUCache();
~LRUCache();
// Separate from constructor so caller can easily make an array of LRUCache
void SetCapacity(size_t capacity) { capacity_ = capacity; }
// Like Cache methods, but with an extra "hash" parameter.
Cache::Handle* Insert(const Slice& key, uint32_t hash,
void* value, size_t charge,
void (*deleter)(const Slice& key, void* value));
Cache::Handle* Lookup(const Slice& key, uint32_t hash);
void Release(Cache::Handle* handle);
void Erase(const Slice& key, uint32_t hash);
void Prune();
size_t TotalCharge() const {
MutexLock l(&mutex_);
return usage_;
}
private:
void LRU_Remove(LRUHandle* e);
void LRU_Append(LRUHandle*list, LRUHandle* e);
void Ref(LRUHandle* e);
void Unref(LRUHandle* e);
bool FinishErase(LRUHandle* e) EXCLUSIVE_LOCKS_REQUIRED(mutex_);
// Initialized before use.
size_t capacity_;
// mutex_ protects the following state.
mutable port::Mutex mutex_;
size_t usage_ GUARDED_BY(mutex_);
// Dummy head of LRU list.
// lru.prev is newest entry, lru.next is oldest entry.
// Entries have refs==1 and in_cache==true.
LRUHandle lru_ GUARDED_BY(mutex_); //lru_ 是冷链表,属于冷宫
// Dummy head of in-use list.
// Entries are in use by clients, and have refs >= 2 and in_cache==true.
LRUHandle in_use_ GUARDED_BY(mutex_); //in_use_ 属于热链表,热数据在此链表
HandleTable table_ GUARDED_BY(mutex_);
};可以看到数据成员主要有HandleTable类型变量table_(猜测和hash有关),LRUHandle类型的变量in_use_(顾名思义是正在使用当中的数据),LRUHandle类型的变量lru_(顾名思义最近最少使用的数据),还有size_t类型的usage_(当前使用的容量)和capacity_(总总量)。在看到in_use_和lru_可以进行猜测,其应该是有两个双向链表,一个维护正在被使用的数据,一个维护最近最少被使用的数据,那么清除cache数据的时候应当会从lru_当中去选择数据删除。
此类的成员方法是围绕着私有方法LRU_Remove、LRU_Append、Ref、Unref来展开实现的,具体的public实现方法有SetCapacity、Insert、Lookup、Release、Erase、Prune、TotalCharge,实现细节后面具体分析。整体的分析思路是分析各个函数的含义,以及数据成员在其中扮演的角色。最后整体上讲述其多线程安全性的实现,还有整个LRUCache与普通LRU方法之间的差异性以及其相关实现的亮点。
Cache::Handle* LRUCache::Insert(
const Slice& key, uint32_t hash, void* value, size_t charge,
void (*deleter)(const Slice& key, void* value)) {
MutexLock l(&mutex_);
LRUHandle* e = reinterpret_cast(
malloc(sizeof(LRUHandle)-1 + key.size()));
e->value = value;
e->deleter = deleter;
e->charge = charge;
e->key_length = key.size();
e->hash = hash;
e->in_cache = false;
e->refs = 1; // for the returned handle.
memcpy(e->key_data, key.data(), key.size());
if (capacity_ > 0) {
e->refs++; // for the cache's reference.
e->in_cache = true;
LRU_Append(&in_use_, e); //将该缓存记录插入到双向链表中热链表中
usage_ += charge; //使用的容量增加
fprintf(stderr,"fun(%s) line(%d) usage_(%d) capacity_(%d)\n", __FILE__, __LINE__, usage_, capacity_);
FinishErase(table_.Insert(e)); //如果是更新操作,回收旧记录,新的插入哈希表会取代旧的,即旧的不会存在哈希表里,所以旧的同时需要finish removing *e from the cache
} else { // don't cache. (capacity_==0 is supported and turns off caching.)
// next is read by key() in an assert, so it must be initialized
e->next = nullptr;
}
// 已用容量超过总量,回收最近最少被使用的缓存记录
while (usage_ > capacity_ && lru_.next != &lru_) {
//如果容量超过了设计的容量,并且冷链表中有内容,则从冷链表中删除元素直到usage_ <= capacity_
LRUHandle* old = lru_.next;
assert(old->refs == 1);
bool erased = FinishErase(table_.Remove(old->key(), old->hash));
if (!erased) { // to avoid unused variable when compiled NDEBUG
assert(erased);
}
}
return reinterpret_cast(e);
} 从Insert实现可以大体看出这样几个步骤:
- 、先动态分配一个LRUHandle*类型的变量e,内存大小为sizeof(LRUHandle)-1 + key.size()。
- 、通过传递的参数初始化e,注意,初始化时的引用计数refs为1,in_cache为false表示还未存进缓存。
- 当LRUCache的容量大于0的时候,首先将引用计数增1以及in_cache置为true表示已插入到cache中。然后会做三件事:1、将e存入到in_use_双向链表当中,表示其正在被使用当中;2、增大LRUCache的当前使用容量;3、将e插入到哈希表(table_)中。
- 当LRUCache的容量等于0的时候,表示关闭了cache功能,不作插入存储操作
- 假如当前已使用的容量_usage大于预定的总容量capacity_且_lru当中有数据(LRUHandle*类型)的时候,会一直清除_lru当中插入的数据直到_usage没有超过capacity_。
- 将e抽象为Handle*类型后返回。
大体步骤就如此,但是深究细节会有一些疑问:1、refs的作用是什么?2、什么情况_lru双向链表当中会有数据?3、为何要拆分为两个双向链表in_use_和lru_?
refs的作用是什么?
refs可以看作其维护这数据的状态,也可以看作是当前多少个并发持有了这个指针,refs大于1的时候表示数据在in_use双向链表当中、等于1的时候表示其在lru_双向链表当中,等于0的数据会被销毁掉。其实可以表示数据被使用的热度,使用得越频繁,其refs值就会越大。而refs值越低,则使用得频率越低,表示最近最少被使用,那么其会是cache中首要被清除得对象。
什么情况_lru双向链表当中会有数据?
当数据被更新的时候(插入的时候发现key值已被保存过),或数据不被使用的时候,会进行FinishErase操作,然后执行Unref操作在其refs为1的时候,将数据插入到lru_双向链表当中,在refs为0的时候真正的销毁数据。
为何要拆分为两个双向链表in_use_和lru_?
如果只有一个链表,且链表的尾部数据引用计数>1的话,这个节点是不能被淘汰的。 只能每次从尾部往前查找,直到第一个引用计算==1的数据才能被淘汰。效率较低。
于是这里拆成两个链表, used链表+lru链表, used链表代表正在使用的链表,这里的数据引用计数>1, 这里的数据不可能被淘汰。当引用计数减少到1的时候, 再放到lru链表,因此lru_链表当中的全是refs为1的数据,这里的数据都可以被淘汰。 (随着引用计数的变更,在两个链表里来回切换。从lru链表淘汰的时候,再delete清理内存。)
讲述完Insert,其他的方法实现就比较容易了
Cache::Handle* LRUCache::Lookup(const Slice& key, uint32_t hash) {
MutexLock l(&mutex_);
LRUHandle* e = table_.Lookup(key, hash);
if (e != nullptr) {
Ref(e);
}
return reinterpret_cast(e);
} cache的lookup实际上就是调用哈希表table_的LookUp快速寻找数据,table_的类型HandleTable后面会详细介绍
void LRUCache::Release(Cache::Handle* handle) {
MutexLock l(&mutex_);
Unref(reinterpret_cast(handle));
} cache的Release的意义就是不再使用此数据(进行一次Unref操作),注意这里未必会真正销毁数据,只有其refs为0的时候才会执行deleater销毁数据
void LRUCache::Erase(const Slice& key, uint32_t hash) {
MutexLock l(&mutex_);
FinishErase(table_.Remove(key, hash));
}cache的Erase就是根据传递的key和其通过hash算法得到的hash值删除cache存储的相关数据。
void LRUCache::Prune() {
MutexLock l(&mutex_);
while (lru_.next != &lru_) {
LRUHandle* e = lru_.next;
assert(e->refs == 1);
bool erased = FinishErase(table_.Remove(e->key(), e->hash));
if (!erased) { // to avoid unused variable when compiled NDEBUG
assert(erased);
}
}
}cache的Prune方法就是清除lru_链表里的数据。
cache的方法解析到此结束,可以看到其实现和哈希表类HandleTable息息相关,哈希表主要是用于以0(1)的时间复杂度查询时间,哈希表类的具体定义如下:
// We provide our own simple hash table since it removes a whole bunch
// of porting hacks and is also faster than some of the built-in hash
// table implementations in some of the compiler/runtime combinations
// we have tested. E.g., readrandom speeds up by ~5% over the g++
// 4.4.3's builtin hashtable.
class HandleTable {
public:
HandleTable() : length_(0), elems_(0), list_(nullptr) { Resize(); }
~HandleTable() { delete[] list_; }
LRUHandle* Lookup(const Slice& key, uint32_t hash) {
return *FindPointer(key, hash);
}
LRUHandle* Insert(LRUHandle* h) {
LRUHandle** ptr = FindPointer(h->key(), h->hash);
LRUHandle* old = *ptr;
h->next_hash = (old == nullptr ? nullptr : old->next_hash);
*ptr = h;
if (old == nullptr) {
++elems_;
if (elems_ > length_) {
// Since each cache entry is fairly large, we aim for a small
// average linked list length (<= 1).
Resize();
}
}
return old;
}
LRUHandle* Remove(const Slice& key, uint32_t hash) {
LRUHandle** ptr = FindPointer(key, hash);
LRUHandle* result = *ptr;
if (result != nullptr) {
*ptr = result->next_hash;
--elems_;
}
return result;
}
private:
// The table consists of an array of buckets where each bucket is
// a linked list of cache entries that hash into the bucket.
uint32_t length_; //当前hash桶的个数
uint32_t elems_; //整个hash表一共存在了多少个元素
LRUHandle** list_; //二维指针,每个指针指向一个桶的表头位置
// Return a pointer to slot that points to a cache entry that
// matches key/hash. If there is no such cache entry, return a
// pointer to the trailing slot in the corresponding linked list.
LRUHandle** FindPointer(const Slice& key, uint32_t hash) {
LRUHandle** ptr = &list_[hash & (length_ - 1)];
while (*ptr != nullptr &&
((*ptr)->hash != hash || key != (*ptr)->key())) {
ptr = &(*ptr)->next_hash;
}
return ptr;
}
void Resize() {
uint32_t new_length = 4;
while (new_length < elems_) {
new_length *= 2;
}
LRUHandle** new_list = new LRUHandle*[new_length];
memset(new_list, 0, sizeof(new_list[0]) * new_length);
uint32_t count = 0;
for (uint32_t i = 0; i < length_; i++) {
LRUHandle* h = list_[i];
while (h != nullptr) {
LRUHandle* next = h->next_hash;
uint32_t hash = h->hash;
LRUHandle** ptr = &new_list[hash & (new_length - 1)];
h->next_hash = *ptr;
*ptr = h; //将某个hash对应的新桶的链表头指向h,h的next_hash为刚刚建立的新桶,相当于逐步往桶的头部插入节点。
h = next;
count++;
}
}
assert(elems_ == count);
delete[] list_;
list_ = new_list;
length_ = new_length;
}
};该类的数据成员有哈希桶列表list_、哈希桶的个数length_、整个列表拥有的数据的总数elems_。它的方法通俗易懂,解析如下:
HandleTable() : length_(0), elems_(0), list_(nullptr) { Resize(); }
void Resize() {
uint32_t new_length = 4;
while (new_length < elems_) {
new_length *= 2;
}
LRUHandle** new_list = new LRUHandle*[new_length];
memset(new_list, 0, sizeof(new_list[0]) * new_length);
uint32_t count = 0;
for (uint32_t i = 0; i < length_; i++) {
LRUHandle* h = list_[i];
while (h != nullptr) {
LRUHandle* next = h->next_hash;
uint32_t hash = h->hash;
LRUHandle** ptr = &new_list[hash & (new_length - 1)];
h->next_hash = *ptr;
*ptr = h; //将某个hash对应的新桶的链表头指向h,h的next_hash为刚刚建立的新桶,相当于逐步往桶的头部插入节点。
h = next;
count++;
}
}
assert(elems_ == count);
delete[] list_;
list_ = new_list;
length_ = new_length;
}
};其构造函数会先进行Resize()操作,第一次Reisze()会创建一个长度为4的哈希桶列表,每个列表的元素是LRUHandle*类型的指针,由于第一次Reisze(),其各个桶当中的指针会指向nullptr。而之后的Reisze()操作会适当的扩大哈希桶列表的长度,然后将旧的哈希桶列表当中的数据重新分散到新的列表当中,以确保一直能够保证每个桶当中只存储一个数据以保证查询的时间复杂度为0(1)。
// Return a pointer to slot that points to a cache entry that
// matches key/hash. If there is no such cache entry, return a
// pointer to the trailing slot in the corresponding linked list.
LRUHandle** FindPointer(const Slice& key, uint32_t hash) {
LRUHandle** ptr = &list_[hash & (length_ - 1)];
while (*ptr != nullptr &&
((*ptr)->hash != hash || key != (*ptr)->key())) {
ptr = &(*ptr)->next_hash;
}
return ptr;
}
LRUHandle* Lookup(const Slice& key, uint32_t hash) {
return *FindPointer(key, hash);
}而FindPointer就是根据提供的hash值和key值去哈希桶列表list_中寻找数据,规则如下:先通过hash值和哈希桶列表的长度length_确定所要寻找的数据在哈希桶列表中的位置hash & (length_ - 1)。然后遍历此桶的链表找寻数据,若无返回nullptr。
Lookup接口实际上就是FindPointer的封装
LRUHandle* Insert(LRUHandle* h) {
LRUHandle** ptr = FindPointer(h->key(), h->hash);
LRUHandle* old = *ptr;
h->next_hash = (old == nullptr ? nullptr : old->next_hash);
*ptr = h;
if (old == nullptr) {
++elems_;
if (elems_ > length_) {
// Since each cache entry is fairly large, we aim for a small
// average linked list length (<= 1).
Resize();
}
}
return old;
}
LRUHandle* Remove(const Slice& key, uint32_t hash) {
LRUHandle** ptr = FindPointer(key, hash);
LRUHandle* result = *ptr;
if (result != nullptr) {
*ptr = result->next_hash;
--elems_;
}
return result;
}Insert操作先通过Key和hash值确认哈希表中是否已有此数据,若有则占有他的位置并返回旧的数据(更新操作),若无则插入到相应的哈希桶当中并更新哈希桶的头节点为此节点。同时注意!假如哈希桶列表拥有的元素超过哈希桶列表的长度了就再次进行Resize()操作重新分散数据
Remove操作就更简单了,先通过key和hash值查询列表当中是否有此数据,有就更新其所在的桶的头节点为此节点的下一个节点,然后返回此节点(用于在LRUCache中删除此节点在lru_双向链表或in_use_双向链表中的位置)。
至此整个LRUCache的核心就解析完毕。
虽然LRUCache的实现基本解析完毕,但在leveldb中实际上这只是一个LRUCache的具体的实现,leveldb为了提高并发量,还提供了一个类ShardedLRUCache维护有16个LRUCache,当需要容量创造大小为kCacheSize的cache的时候,会将其均分为16份,每份生成容量为kCacheSize / 16的LRUCache,同时在插入和删除等操作的时候其不是围绕整个大的容量的cache进行加锁操作,而是按照分区的粒度去进行锁操作,提高了并发量(按区进行锁操作不同分区的操作可以并发执行,不按区进行锁操作不同线程无法并发进行cache相关操作)
其类定义和实现很简单,如下所示:
static const int kNumShardBits = 4;
static const int kNumShards = 1 << kNumShardBits;
class ShardedLRUCache : public Cache {
private:
LRUCache shard_[kNumShards];
port::Mutex id_mutex_;
uint64_t last_id_;
static inline uint32_t HashSlice(const Slice& s) {
return Hash(s.data(), s.size(), 0);
}
static uint32_t Shard(uint32_t hash) {
//hash右移28位,提取高4位的值,4位二进制最大值为2^4 - 1。
return hash >> (32 - kNumShardBits);
}
public:
explicit ShardedLRUCache(size_t capacity)
: last_id_(0) {
//为什么减1呢?试想一下,总容量capacity为16,正常情况下,16个分区,每个分区的容量为1个就可以了,但是假如不减1,则
//(16+16)/16 =2 ,就变成每个分区有2个容量,这会造成冗余,于是(16+(16-1)) / 16 =1 ,满足每个区只有一个容量且不冗余
//即只有每超过一个kNumShards时候,才会增加一个分区。
const size_t per_shard = (capacity + (kNumShards - 1)) / kNumShards;
for (int s = 0; s < kNumShards; s++) {
shard_[s].SetCapacity(per_shard);
}
}
/*
使用哈希值的前4位进行路由, 路由到2^4(0-15) 个独立的缓存区, 各个缓存区维护自己的mutex进行并发控制;
哈希表在插入节点时判断空间使用率, 并进行自动扩容, 保证查找效率在O(1)
*/
virtual ~ShardedLRUCache() { }
virtual Handle* Insert(const Slice& key, void* value, size_t charge,
void (*deleter)(const Slice& key, void* value)) {
const uint32_t hash = HashSlice(key);
return shard_[Shard(hash)].Insert(key, hash, value, charge, deleter);
}
virtual Handle* Lookup(const Slice& key) {
const uint32_t hash = HashSlice(key);
printf("hash->%u, Shard(hash)->%d\n",hash, Shard(hash));
return shard_[Shard(hash)].Lookup(key, hash);
}
virtual void Release(Handle* handle) {
LRUHandle* h = reinterpret_cast(handle);
shard_[Shard(h->hash)].Release(handle);
}
virtual void Erase(const Slice& key) {
const uint32_t hash = HashSlice(key);
shard_[Shard(hash)].Erase(key, hash);
}
virtual void* Value(Handle* handle) {
return reinterpret_cast(handle)->value;
}
virtual uint64_t NewId() {
MutexLock l(&id_mutex_);
return ++(last_id_);
}
virtual void Prune() {
for (int s = 0; s < kNumShards; s++) {
shard_[s].Prune();
}
}
virtual size_t TotalCharge() const {
size_t total = 0;
for (int s = 0; s < kNumShards; s++) {
total += shard_[s].TotalCharge();
}
return total;
}
}; 这里不得不说一下 NewId() 的作用,NewId() 接口可以生成一个唯一的 id,多线程环境下可以使用这个 id 与自己的键值拼接起来,防止不同线程之间互相覆写,以提高其线程安全性。
至此,Leveldb有关LRUCache的实现终于解析完毕,可以看到大神的代码浅显易懂但又亮点多多,从数据结构和算法的使用,从到线程安全性到提高并发性的技巧,都让我受益匪浅。