Flink on Zeppelin (3) - Streaming 篇
继之前 入门篇 和 Batch 篇 之后,今天这篇 Flink on Zeppelin 主要讲述如何在 Zeppelin 中使用 Flink 的 Streaming 功能,我们会以 2 个主要的场景来讲:
Streaming ETL
Streaming Data Analytics
准备工作
本文我们会用 Kafka 作为我们的数据源,使用 Flink SQL 处理 Kafka 中的某个 topic 数据,然后写入到另外一个 Kafka Topic。为了使用 Flink 的 Kafka connector,你需要在 Flink Interpreter 中配置 flink.execution.packages。
flink.execution.packages org.apache.flink:flink-connector-kafka_2.11:1.10-SNAPSHOT,org.apache.flink:flink-connector-kafka-base_2.11:1.10-SNAPSHOT,org.apache.flink:flink-json:1.10-SNAPSHOT
本文使用的 kafka 数据源是 json 格式,所以需要添加 org.apache.flink:flink-json。
另外本文的例子会使用这个 docker compose 来创建 Kafka Cluster,https://github.com/xushiyan/kafka-connect-datagen/
需要运行下面2个命令来启动kafka集群和创建kafka topic:
docker-compose up -d
curl -X POST http://localhost:8083/connectors \
-H 'Content-Type:application/json' \
-H 'Accept:application/json' \
-d @connect.source.datagen.json
具体请参考这个官方链接:https://kafka-connect-datagen.readthedocs.io/en/latest/
Streaming ETL
接下里我们会用 Flink SQL 来做基于 Kafka 的 Streaming ETL。首先我们需要创建 Kafka source table 代表 kafka 中的源数据。
%flink.ssql
DROP TABLE IF EXISTS source_kafka;
CREATE TABLE source_kafka (
status STRING,
direction STRING,
event_ts BIGINT
) WITH (
'connector.type' = 'kafka',
'connector.version' = 'universal',
'connector.topic' = 'generated.events',
'connector.startup-mode' = 'earliest-offset',
'connector.properties.zookeeper.connect' = 'localhost:2181',
'connector.properties.bootstrap.servers' = 'localhost:9092',
'connector.properties.group.id' = 'testGroup',
'connector.startup-mode' = 'earliest-offset',
'format.type'='json',
'update-mode' = 'append'
);
然后创建 Kafka sink table,代表清洗后的数据 (这里我们定义了 WATERMARK,是为了下一步做基于 window 的流式数据分析)。
%flink.ssql
DROP TABLE IF EXISTS sink_kafka;
CREATE TABLE sink_kafka (
status STRING,
direction STRING,
event_ts TIMESTAMP(3),
WATERMARK FOR event_ts AS event_ts - INTERVAL '5' SECOND
) WITH (
'connector.type' = 'kafka',
'connector.version' = 'universal',
'connector.topic' = 'generated.events2',
'connector.properties.zookeeper.connect' = 'localhost:2181',
'connector.properties.bootstrap.servers' = 'localhost:9092',
'connector.properties.group.id' = 'testGroup',
'format.type'='json',
'update-mode' = 'append'
)
接下来我们就可以用 Insert Into 语句来做 Streaming ETL 的工作了。
%flink.ssql
insert into sink_kafka select status, direction, cast(event_ts/1000000000 as timestamp(3)) from source_kafka where status <> 'foo'
这条 Insert into 语句非常简单,我们过滤掉了status 为 foo 的数据,以及将 event_ts 转化为 timestamp 类型。

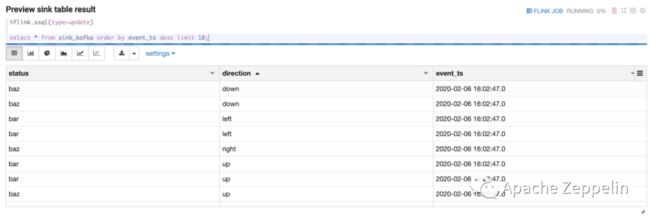
然后可以用 select 语句来预览 sink table 中的数据来确认 Streaming ETL 正常工作。
Streaming Data Analytics
在完成了上面的 Streaming ETL 工作之后,我们就可以在 Zeppelin 中做流式数据分析了。在 Zeppelin 中可以用 Select 语句来做 Flink 流数据分析,Select 的结果会 push 到 Zeppelin 前端展示,可以用来做流式数据的 dashboard。
Zeppelin 支持 3 种模式的流式数据分析:
Single 模式
Update 模式
Append 模式
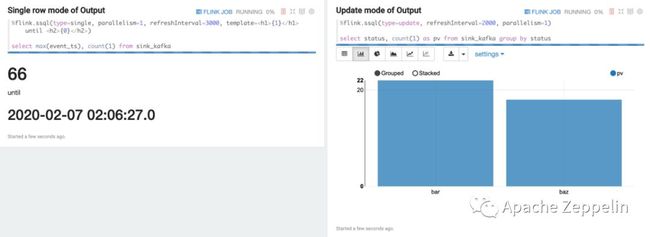
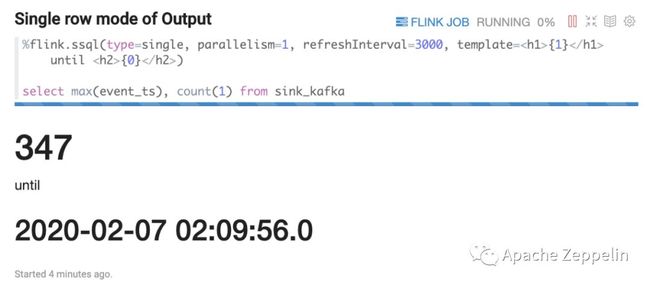
Single 模式
Single 模式适合当输出结果是一行的情况,比如下面的 Select 语句。这条 SQL 语句永远只有一行数据,但这行数据会持续不断的更新。这种模式的数据输出格式是 html 形式,用户可以用 template 来指定输出模板,{i} 是第 i 列的 placeholder。
%flink.ssql(type=single, parallelism=1, refreshInterval=3000, template={1}
until {0}
)
select max(event_ts), count(1) from sink_kafka
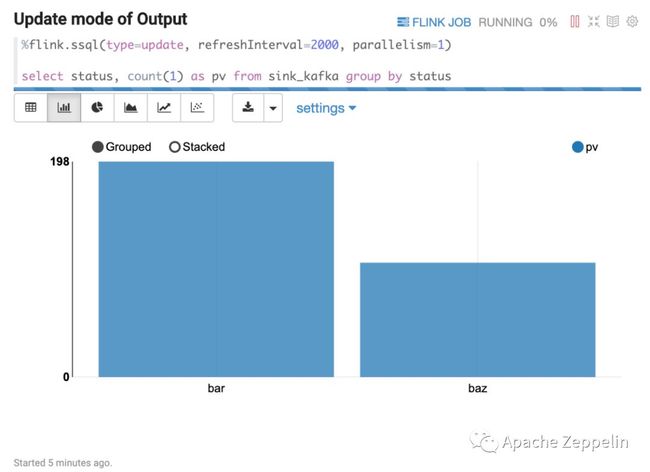
Update 模式
Update 模式适合多行输出的情况,比如下面的 select group by 语句。这种模式会定期更新这多行数据,输出是 Zeppelin 的 table 格式,所以可以用 Zeppelin 自带的可视化控件。
%flink.ssql(type=update, refreshInterval=2000, parallelism=1)
select status, count(1) as pv from sink_kafka group by status
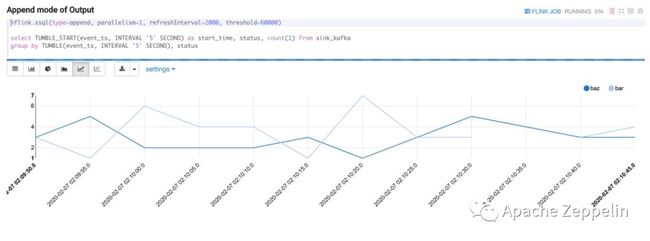
Append 模式
Append 模式适合不断有新数据输出,但不会覆盖原有数据,只会不断 append 的情况。比如下面的基于窗口的 group by 语句。Append 模式要求第一列数据类型是 timestamp,这里的 start_time 就是 timestamp 类型。
%flink.ssql(type=append, parallelism=1, refreshInterval=2000, threshold=60000)
select TUMBLE_START(event_ts, INTERVAL '5' SECOND) as start_time, status, count(1) from sink_kafka
group by TUMBLE(event_ts, INTERVAL '5' SECOND), status
更多 Flink SQL 资料
本文只是简单介绍如何在 Zeppelin 中使用 Flink Streaming SQL,关于更多 Flink SQL 请参考 Flink 官方文档
https://ci.apache.org/projects/flink/flink-docs-master/dev/table/sql/
https://ci.apache.org/projects/flink/flink-docs-master/dev/table/connect.html
Zeppelin on Flink 系列
Zeppelin on Flink (1) 入门篇
Zeppelin on Flink (2)Batch 篇
如果有碰到任何问题,请加入下面这个钉钉群讨论。后续我们会有更多 Tutorial 的文章,敬请期待。

关注 Flink 中文社区,获取更多技术干货

你也「在看」吗?????