招商银行2020FinTech精英训练营数据赛道参赛回顾
招商银行2020FinTech精英训练营数据赛道参赛回顾
- 比赛简介
- 参赛背景
- 比赛过程
- 1、流程熟悉
- 2、模块导入,数据读取
- 3、数据初探、概览
- 3.1 标签数据集数据预处理
- 3.2 交易行为数据集数据预处理
- 3.3 APP行为数据集数据预处理
- 4、图形探索
- 4.1 标签数据集
- 4.2 交易行为数据集
- 4.3 APP行为数据集
- 5、数据清洗函数构建
- 5.1 异常值处理函数
- 5.2 缺失值处理函数
- 6、 数据清洗
- 6.1 异常值处理
- 6.2 缺失值处理
- 6.3 去除共线性
- 6.4 合并三表格
- 6.5 修改名字会导致训练异常的列
- 6.6 去掉与训练无关的用户标识列
- 6.7 重新采样,平衡类别
- 6.8 划分训练集和测试集,为建模训练模型作准备
- 7、 模型训练-xgboost模型
- 8、预测并生成结果
比赛简介
比赛规则
1.竞赛时间:4月29日11:00-5月12日17:00;
2.采用数据竞赛的形式,4月29日11:00-5月9日24:00,赛道开放A榜数据,预测结果数据每天限提交5次;5月10日00:00-5月12日17:00,赛道开放B榜数据,预测结果数据每天限提交3次。结果提交后请务必点击“运行”按钮,方可查看当前个人排名,最终排名以B榜成绩为准;
比赛任务
基于训练数据集,通过有效的特征提取,构建信用违约预测模型,并将模型应用在评分数据集上,输出评分数据集中每个用户的违约概率
比赛数据
训练集和评分(测试)集各分为三组数据,放在三个csv文件里。
分别为:
- 用户标签表
- 交易行为表
- APP行为表
参赛背景
个人基础:数据分析实战零基础小白一枚,文科僧,本科经济类。认为未来职业发展懂一些IT知识会比较有益,遂想学一些技术。自学一年略懂一些Python,Java,SQL 和 HTML/CSS/JavaScript。
可想而知我基础很差非常菜,流程上肯定会有很捉鸡很不专业的地方。只是一个通过比赛对学习到知识和技能的回顾与汇总,轻喷。
花费大约十天的时间网上搜索相关资料,边看边学。
比赛过程
1、流程熟悉
因对数据分析一无所知,所以首先网上搜索数据分析相关流程,重点收藏关注与比赛案例相似的文章。
此次比赛主要参考以下几篇文章:
债务违约预测之一:数据探索
债务违约预测之二:图形探索
债务违约预测之三:利用sklearn进行预测
债务违约预测之四:利用人工神经网络进行预测
我信你个拐 ! — 信用违约预测模型 | Kaggle
非常感谢作者们的思路,流程很清晰,受益匪浅。
2、模块导入,数据读取
经过大致搜索,数据分析一般需要用到numpy,pandas, matplotlib, seaborn, sklearn 这些模块。 并且xgboost貌似在kaggle等竞赛中被广泛应用。
首先先引用下列模块,后续还会根据需要增加
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
import seaborn as sns
import xgboost as xgb
import warnings
warnings.filterwarnings('ignore')
特别指出我当前的Mac版本 (MacOS Catalina Version10.15.4) 不知怎的在网上查了很多资料都无法直接正常安装上xgboost模块。
我的解决方法是安装Anaconda,然后PyCharm内选择Conda Environment作为Interpreter,然后再在PyCharm内才成功安装了xgboost.
但是貌似免费版PyCharm不能用Conda Environment?如果只有免费版的情况下我可能会选择用Anaconda内整合的Jupyter Notebook.
文件读取:
df1 = pd.read_csv('训练数据集_tag.csv')
df2 = pd.read_csv('训练数据集_trd.csv')
df3 = pd.read_csv('训练数据集_beh.csv')
重命名各列名为中文,更易读:
# translate columns names to Chinese
df1.rename(columns={'id': '用户标识',
'flag': '目标变量',
'cur_debit_cnt': '持有招行借记卡张数',
'cur_credit_cnt': '持有招行信用卡张数',
'cur_debit_min_opn_dt_cnt': '持有招行借记卡天数',
'cur_credit_min_opn_dt_cnt': '持有招行信用卡天数',
'cur_debit_crd_lvl': '招行借记卡持卡最高等级代码',
'hld_crd_card_grd_cd': '招行信用卡持卡最高等级代码',
'crd_card_act_ind': '信用卡活跃标识',
'l1y_crd_card_csm_amt_dlm_cd': '最近一年信用卡消费金额分层',
'atdd_type': '信用卡还款方式',
'perm_crd_lmt_cd': '信用卡永久信用额度分层',
'age': '年龄',
'gdr_cd': '性别',
'mrg_situ_cd': '婚姻',
'edu_deg_cd': '教育程度',
'acdm_deg_cd': '学历',
'deg_cd': '学位',
'job_year': '工作年限',
'ic_ind': '工商标识',
'fr_or_sh_ind': '法人或股东标识',
'dnl_mbl_bnk_ind': '下载并登录招行APP标识',
'dnl_bind_cmb_lif_ind': '下载并绑定掌上生活标识',
'hav_car_grp_ind': '有车一族标识',
'hav_hou_grp_ind': '有房一族标识',
'l6mon_agn_ind': '近6个月代发工资标识',
'frs_agn_dt_cnt': '首次代发工资距今天数',
'vld_rsk_ases_ind': '有效投资风险评估标识',
'fin_rsk_ases_grd_cd': '用户理财风险承受能力等级代码',
'confirm_rsk_ases_lvl_typ_cd': '投资强风评等级类型代码',
'cust_inv_rsk_endu_lvl_cd': '用户投资风险承受级别',
'l6mon_daim_aum_cd': '近6个月月日均AUM分层',
'tot_ast_lvl_cd': '总资产级别代码',
'pot_ast_lvl_cd': '潜力资产等级代码',
'bk1_cur_year_mon_avg_agn_amt_cd': '本年月均代发金额分层',
'l12mon_buy_fin_mng_whl_tms': '近12个月理财产品购买次数',
'l12_mon_fnd_buy_whl_tms': '近12个月基金购买次数',
'l12_mon_insu_buy_whl_tms': '近12个月保险购买次数',
'l12_mon_gld_buy_whl_tms': '近12个月黄金购买次数',
'loan_act_ind': '贷款用户标识',
'pl_crd_lmt_cd': '个贷授信总额度分层',
'ovd_30d_loan_tot_cnt': '30天以上逾期贷款的总笔数',
'his_lng_ovd_day': '历史贷款最长逾期天数'}, inplace=True)
df2.rename(columns={'id': '用户标识',
'flag': '目标变量',
'Dat_Flg1_Cd': '交易方向',
'Dat_Flg3_Cd': '支付方式',
'Trx_Cod1_Cd': '收支一级分类代码',
'Trx_Cod2_Cd': '收支二级分类代码',
'trx_tm': '交易时间',
'cny_trx_amt': '交易金额'}, inplace=True)
df3.rename(columns={'id': '用户标识',
'flag': '目标变量',
'page_no': '页面编码',
'page_tm': '访问时间'}, inplace=True)
加起来可能得有50个列左右,也就是大概50个特征值,非常多,数据维度很大。
3、数据初探、概览
加入这三行代码可以让打印结果全部显示出来:
pd.options.display.max_columns = None
pd.options.display.max_rows = None
np.set_printoptions(threshold=np.inf)
3.1 标签数据集数据预处理
一个一个来,先观察标签数据集df1
Input:
print(df1.目标变量.value_counts())
Output:
# 类别分布不平衡,会影响建模效果,可能需要过采样或欠采样处理
0 30970
1 8953
Input:
print(df1.info())
print(df1.head().T)
print(df1.describe())
运行
Output:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 39923 entries, 0 to 39922
Data columns (total 43 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 用户标识 39923 non-null object
1 目标变量 39923 non-null int64
2 性别 39923 non-null object
3 年龄 39923 non-null int64
4 婚姻 39923 non-null object
5 教育程度 27487 non-null object
6 学历 39922 non-null object
7 学位 18960 non-null object
8 工作年限 39923 non-null object
9 工商标识 39923 non-null object
10 法人或股东标识 39923 non-null object
11 下载并登录招行APP标识 39923 non-null object
12 下载并绑定掌上生活标识 39923 non-null object
13 有车一族标识 39923 non-null object
14 有房一族标识 39923 non-null object
15 近6个月代发工资标识 39923 non-null object
16 首次代发工资距今天数 39923 non-null object
17 有效投资风险评估标识 39923 non-null object
18 用户理财风险承受能力等级代码 39923 non-null object
19 投资强风评等级类型代码 39923 non-null object
20 用户投资风险承受级别 39923 non-null object
21 近6个月月日均AUM分层 39923 non-null int64
22 总资产级别代码 39923 non-null object
23 潜力资产等级代码 39923 non-null object
24 本年月均代发金额分层 39923 non-null int64
25 近12个月理财产品购买次数 39923 non-null object
26 近12个月基金购买次数 39923 non-null object
27 近12个月保险购买次数 39923 non-null object
28 近12个月黄金购买次数 39923 non-null object
29 贷款用户标识 39923 non-null object
30 个贷授信总额度分层 39923 non-null int64
31 30天以上逾期贷款的总笔数 39923 non-null object
32 历史贷款最长逾期天数 39923 non-null object
33 招行信用卡持卡最高等级代码 39923 non-null object
34 信用卡活跃标识 39923 non-null object
35 最近一年信用卡消费金额分层 39923 non-null object
36 信用卡还款方式 16266 non-null object
37 信用卡永久信用额度分层 39923 non-null int64
38 持有招行借记卡张数 39923 non-null int64
39 持有招行信用卡张数 39923 non-null int64
40 持有招行借记卡天数 39923 non-null int64
41 持有招行信用卡天数 39923 non-null int64
42 招行借记卡持卡最高等级代码 39923 non-null int64
dtypes: int64(11), object(32)
memory usage: 13.1+ MB
None
0 1 2 3 4
用户标识 U7A4BAD U557810 U1E9240 U6DED00 UDA8E28
目标变量 0 0 0 0 0
性别 M M M F F
年龄 41 35 53 41 42
婚姻 B A B B B
教育程度 B NaN A NaN B
学历 Z G C Z Z
学位 NaN NaN C NaN B
工作年限 3 4 9 0 3
工商标识 0 0 0 0 1
法人或股东标识 0 0 0 0 1
下载并登录招行APP标识 0 0 1 0 1
下载并绑定掌上生活标识 1 0 1 0 0
有车一族标识 0 0 0 0 0
有房一族标识 0 0 0 0 1
近6个月代发工资标识 0 0 1 0 0
首次代发工资距今天数 -1 -1 935 -1 -1
有效投资风险评估标识 0 0 1 0 0
用户理财风险承受能力等级代码 -1 -1 3 -1 -1
投资强风评等级类型代码 4 -1 3 -1 -1
用户投资风险承受级别 1 1 6 1 1
近6个月月日均AUM分层 0 0 7 0 5
总资产级别代码 -1 -1 -1 -1 -1
潜力资产等级代码 6 -1 2 6 3
本年月均代发金额分层 0 0 8 0 0
近12个月理财产品购买次数 0 0 6 0 0
近12个月基金购买次数 0 0 0 0 0
近12个月保险购买次数 0 0 0 0 0
近12个月黄金购买次数 0 0 0 0 0
贷款用户标识 0 0 0 0 1
个贷授信总额度分层 0 0 0 0 6
30天以上逾期贷款的总笔数 0 0 0 0 0
历史贷款最长逾期天数 0 0 0 0 4
招行信用卡持卡最高等级代码 -1 -1 -1 -1 -1
信用卡活跃标识 0 0 0 0 0
最近一年信用卡消费金额分层 0 0 0 0 0
信用卡还款方式 0 0 0 0 0
信用卡永久信用额度分层 3 1 7 1 2
持有招行借记卡张数 1 1 2 1 7
持有招行信用卡张数 0 0 0 0 0
持有招行借记卡天数 3492 4575 4894 4938 2378
持有招行信用卡天数 -1 -1 -1 -1 -1
招行借记卡持卡最高等级代码 10 10 40 10 20
目标变量 年龄 近6个月月日均AUM分层 本年月均代发金额分层 个贷授信总额度分层 \
count 39923.000000 39923.000000 39923.000000 39923.000000 39923.000000
mean 0.224257 34.325727 0.875235 0.403652 0.187060
std 0.417097 8.541069 1.354406 1.293567 0.963996
min 0.000000 19.000000 -1.000000 -1.000000 -1.000000
25% 0.000000 28.000000 0.000000 0.000000 0.000000
50% 0.000000 33.000000 0.000000 0.000000 0.000000
75% 0.000000 39.000000 1.000000 0.000000 0.000000
max 1.000000 84.000000 9.000000 10.000000 9.000000
信用卡永久信用额度分层 持有招行借记卡张数 持有招行信用卡张数 持有招行借记卡天数 持有招行信用卡天数 \
count 39923.000000 39923.000000 39923.000000 39923.000000 39923.000000
mean 3.690179 1.109110 1.440924 1221.380608 1293.431305
std 2.124529 2.521372 1.497116 1604.667054 1270.756497
min -1.000000 0.000000 0.000000 -1.000000 -1.000000
25% 2.000000 0.000000 1.000000 -1.000000 360.000000
50% 3.000000 1.000000 1.000000 493.000000 861.000000
75% 5.000000 1.000000 2.000000 1851.000000 1810.000000
max 8.000000 178.000000 173.000000 9538.000000 6086.000000
招行借记卡持卡最高等级代码
count 39923.000000
mean 8.700999
std 7.894769
min 0.000000
25% 0.000000
50% 10.000000
75% 10.000000
max 80.000000
Process finished with exit code 0
可以发现许多列都是object数据类型,不是int或float类型,这样无法直接计算。
但其实大部分列的数据本都是数值型数据,这是怎么回事呢?
观察csv文件发现是因为有部分非数值型数据混入了这些数值当中。拿“工作年限”列来作例子:
Input:
print(df1.工作年限.value_counts())
Output:
0 17235
1 6270
2 4128
3 2789
5 1565
4 1495
6 892
10 816
8 649
7 604
\N 493
15 335
9 314
12 273
20 261
14 218
13 215
16 203
11 201
17 145
18 115
30 96
25 87
22 58
19 51
21 48
28 47
24 43
23 41
26 40
27 36
32 24
35 23
29 20
31 19
33 17
37 12
34 12
36 10
38 7
40 6
39 4
43 2
41 2
42 1
99 1
Name: 工作年限, dtype: int64
Process finished with exit code 0
发现有493个 ‘\N’ 值。其他未被识别成数值型的列也是同样这种情况。
此外“教育程度”,“学位”,“信用卡还款方式” 列都有大量的null值。
第九列以后都是混有非数值型的数值型数据,因此直接把他们强制转为数值,非数值型的填充为Nan值
第九列以前的五个特征值本身为非数值型数据,用pandas自带的方法转为独热编码(One-Hot Encoding)标识
# 转换列dtype从object到int或float数据
df1.iloc[:, 8:] = df1.iloc[:, 8:].apply(pd.to_numeric, errors='coerce')
df1_object = df1[['性别', '婚姻', '教育程度', '学历', '学位']]
df1.drop(columns=['性别', '婚姻', '教育程度', '学历', '学位'], inplace=True)
# One-Hot Encoding
df1 = df1.join(pd.get_dummies(df1_object))
3.2 交易行为数据集数据预处理
接着观察df2
Input:
print(df2.info())
print(df2.head().T)
print(df2.describe())
Output:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 1367211 entries, 0 to 1367210
Data columns (total 8 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 用户标识 1367211 non-null object
1 目标变量 1367211 non-null int64
2 交易方向 1367211 non-null object
3 支付方式 1367211 non-null object
4 收支一级分类代码 1367211 non-null int64
5 收支二级分类代码 1367211 non-null int64
6 交易时间 1367211 non-null object
7 交易金额 1367211 non-null float64
dtypes: float64(1), int64(3), object(4)
memory usage: 83.4+ MB
None
0 1 2 \
用户标识 UFDC88A UFDC88A UFDC88A
目标变量 0 0 0
交易方向 B B B
支付方式 B B B
收支一级分类代码 1 1 1
收支二级分类代码 116 116 136
交易时间 2019-06-20 07:15:28 2019-06-16 10:09:13 2019-05-14 16:11:32
交易金额 -127.99 -55.88 -557
3 4
用户标识 UFDC88A UFDC88A
目标变量 0 0
交易方向 B B
支付方式 B B
收支一级分类代码 1 1
收支二级分类代码 136 113
交易时间 2019-05-19 21:54:40 2019-06-18 08:23:59
交易金额 -77.8 -271.62
目标变量 收支一级分类代码 收支二级分类代码 交易金额
count 1.367211e+06 1.367211e+06 1.367211e+06 1.367211e+06
mean 1.573503e-01 1.475148e+00 1.666500e+02 4.892947e+00
std 3.641308e-01 7.740244e-01 7.177708e+01 6.997166e+04
min 0.000000e+00 1.000000e+00 1.010000e+02 -2.390000e+07
25% 0.000000e+00 1.000000e+00 1.170000e+02 -2.000000e+02
50% 0.000000e+00 1.000000e+00 1.340000e+02 -2.400000e+01
75% 0.000000e+00 2.000000e+00 2.090000e+02 -2.000000e+00
max 1.000000e+00 3.000000e+00 3.110000e+02 3.389516e+07
Process finished with exit code 0
观察原csv文件和打印信息,发现此表数据包含大量同一用户的多行信息,这样是没办法和标签数据集直接合并的。
因为此债务违约预测是基于每个用户数据行为进行预测,所以我这里的处理方法是根据用户ID对他们的交易行为进行汇总统计。
首先先把时间数据由object转为datetime格式:
df2['交易时间'] = pd.to_datetime(df2['交易时间'])
然后拆解交易行为表,根据不同的列做不同的统计汇总:
# 拆解交易行为表
# 计算每个用户的交易金额的总值,平均值,最小值和最大值
df2_left = pd.pivot_table(df2,
index=['用户标识'],
values=['交易金额'],
aggfunc={'交易金额': [np.sum, np.mean, np.min, np.max]})
# 重命名列使其更易读
df2_left.rename(columns={'amax': '最大交易金额',
'amin': '最小交易金额',
'mean': '平均交易金额',
'sum': '总交易金额'}, inplace=True)
# 计算交易次数和最后一次交易距第一次交易的时间跨度
df2_mid = pd.pivot_table(df2,
index=['用户标识'],
values=['交易时间'],
aggfunc={'交易时间': ['count', lambda x: x.max() - x.min()]})
# 重命名列使其更易读
df2_mid.rename(columns={'count': '交易次数',
'' : '交易时间跨度'}, inplace=True)
# 计算交易频繁度(平均一次交易间隔多少天)
df2_mid['交易频繁度', '平均n天一次'] = df2_mid['交易时间', '交易时间跨度']/df2_mid['交易时间', '交易次数']
# datetime 数据类型转为 float型,用于后续的样本训练,因为训练模型无法直接训练日期型数据
df2_mid['交易时间', '交易时间跨度'] = df2_mid['交易时间', '交易时间跨度']/timedelta(days=1)
df2_mid['交易频繁度', '平均n天一次'] = df2_mid['交易频繁度', '平均n天一次']/timedelta(days=1)
# 计算每个用户各种交易方向、支付方式等的次数
df2_right = df2[['用户标识', '交易方向', '支付方式', '收支一级分类代码', '收支二级分类代码']]
df2_right = df2_right.melt('用户标识')
df2_right = pd.pivot_table(df2_right,
index=['用户标识'],
columns=['variable', 'value'],
aggfunc="size",
fill_value=0)
将上述拆分并交易行为数据进行合并
df2_pivot = pd.merge(df2_left, df2_mid, how='left', on='用户标识')
df2_pivot = pd.merge(df2_pivot, df2_right, how='left', on='用户标识')
3.3 APP行为数据集数据预处理
df3表格初始列名与应对应数据有一点错位,需要进行修复:
df3.drop(columns='访问时间', inplace=True)
df3.rename(columns={'Unnamed: 3': '访问时间'}, inplace=True)
然后数据处理的思路同df2基本一样,也是基于用户ID进行统计汇总。
# 拆解交易行为表
df3_left = pd.pivot_table(df3,
index=['用户标识'],
values=['目标变量'],
aggfunc='count')
df3_left.rename(columns={'目标变量': '访问总次数'}, inplace=True)
df3_left.drop(columns='访问总次数', inplace=True)
df3_mid = df3[['用户标识', '页面编码']]
df3_mid = df3_mid.melt('用户标识')
df3_mid = pd.pivot_table(df3_mid,
index=['用户标识'],
columns=['variable', 'value'],
aggfunc='size',
fill_value=0)
df3_right = df3[['用户标识', '访问时间']]
df3_right = pd.pivot_table(df3_right,
index=['用户标识'],
values=['访问时间'],
aggfunc={'访问时间': ['count', lambda x: x.max()-x.min()]})
df3_right.rename(columns={'' : '浏览时间跨度',
'count': '浏览总次数'}, inplace=True)
df3_right['浏览频率', '平均n天一次'] = df3_right['访问时间', '浏览时间跨度']/df3_right['访问时间', '浏览总次数']
df3_right['访问时间', '浏览时间跨度'] = df3_right['访问时间', '浏览时间跨度']/timedelta(days=1)
df3_right['浏览频率', '平均n天一次'] = df3_right['浏览频率', '平均n天一次']/timedelta(days=1)
合并APP行为表:
df3_pivot = pd.merge(df3_left, df3_mid, how='left', on='用户标识')
df3_pivot = pd.merge(df3_pivot, df3_right, how='left', on='用户标识')
4、图形探索
因为各个表格特征值过多,所以三个表格分开绘图分析
加入此行代码解决matplotlib中文显示为方块的问题
plt.rcParams['font.sans-serif'] = ['Arial Unicode MS']
4.1 标签数据集
画出标签数据集各列的的数据分布柱状图:
Input:
plt.figure(figsize=(200, 140), dpi=50)
plt.subplots_adjust(wspace=0.5, hspace=0.5)
for n, i in enumerate(df1.iloc[:, 1:].columns):
plt.subplot(9, 9, n+1)
plt.title(i, fontsize=9)
plt.grid(linestyle='--')
df1[i].hist(color='grey', alpha=0.5)
plt.show()
plt.close()
Output:

许多特征分布偏态,后续建模需考虑纠偏处理
画出箱型图:
Input:
plt.figure(figsize=(200, 140), dpi=50)
plt.subplots_adjust(wspace=0.5, hspace=0.5)
for n, i in enumerate(df1.iloc[:, 1:].columns):
plt.subplot(9, 9, n+1)
plt.title(i, fontsize=9)
plt.grid(linestyle='--')
df1[[i]].boxplot(sym='.')
plt.show()
plt.close()
Output:
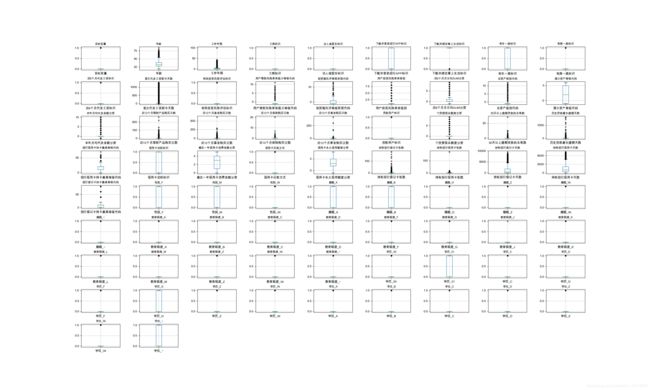
大部分数据看起来都存在异常值,需要根据具体情况做不同的后续处理。
画出热力图:
因数据维度过大,无法全部清晰显示,先画出原始值为数值型数据的热力图
Input:
plt.figure(figsize=(80, 80), dpi=50)
sns.heatmap(df1.iloc[:, 1:37].corr(), cmap='Reds', annot=True)
plt.show()
plt.close()
Output:
独热编码后的数据热力图:
Input:
plt.figure(figsize=(60, 60), dpi=50)
sns.heatmap(df1.iloc[:, 37:].corr(), cmap='Reds', annot=True)
plt.show()
plt.close()
Output:
大于0.8的数值之间共线性可能比较高,可考虑后续去共线性
4.2 交易行为数据集
与标签数据集类似,也是绘制出柱状分布图,箱型图,热力图进行观察
分布图
Input:
plt.figure(figsize=(100, 100), dpi=50)
plt.subplots_adjust(wspace=0.5, hspace=0.5)
for n, i in enumerate(df2_pivot.iloc[:, :].columns):
plt.subplot(9, 9, n+1)
plt.title(i, fontsize=9)
plt.grid(linestyle='--')
df2_pivot[i].hist(color='grey', alpha=0.5)
plt.show()
plt.close()
Output:

箱型图:
Input:
plt.figure(figsize=(100, 100), dpi=50)
plt.subplots_adjust(wspace=0.5, hspace=0.5)
for n, i in enumerate(df2_pivot.iloc[:, 1:].columns):
plt.subplot(9, 9, n+1)
plt.title(i, fontsize=11)
plt.grid(linestyle='--')
df2_pivot[[i]].boxplot(sym='.')
plt.show()
plt.close()
Output:

热力图:
Input:
plt.figure(figsize=(60, 60), dpi=50)
sns.heatmap(df2_pivot.iloc[:, :].corr(), cmap='Reds', annot=True)
plt.show()
plt.close()
Output:
4.3 APP行为数据集
同上
分布柱状图:
Input:
plt.figure(figsize=(100, 100), dpi=50)
plt.subplots_adjust(wspace=0.5, hspace=0.5)
for n, i in enumerate(df3_pivot.iloc[:, :].columns):
plt.subplot(6, 6, n+1)
plt.title(i, fontsize=10)
plt.grid(linestyle='--')
df3_pivot[i].hist(color='grey', alpha=0.5)
plt.show()
plt.close()

箱型图:
Input:
plt.figure(figsize=(100, 100), dpi=50)
plt.subplots_adjust(wspace=0.5, hspace=0.5)
for n, i in enumerate(df3_pivot.iloc[:, :].columns):
plt.subplot(6, 6, n+1)
plt.title(i, fontsize=11)
plt.grid(linestyle='--')
df3_pivot[[i]].boxplot(sym='.')
plt.show()
plt.close()
Output:

热力图:
Input:
plt.figure(figsize=(60, 60), dpi=50)
sns.heatmap(df3_pivot.iloc[:, :].corr(), cmap='Reds', annot=True)
plt.show()
plt.close()
Output:

5、数据清洗函数构建
5.1 异常值处理函数
将异常值替换为该列的众数,平均值或指定值
def error_filling(df, col, condition, value=0, func=1):
"""
:param df: DataFrame resouce
:param col: column to be modified
:param condition: error condition
:param value to be filled when func = 2
:param func: 1(deafault): fill with mode; 0: fill with mean
:return:
"""
if func == 1:
df.loc[df[col] > condition, col] = df[col].mode()[0]
elif func == 0:
df.loc[df[col] > condition, col] = df[col].mean()
elif func == 2:
df.loc[df[col] > condition, col] = value
else:
print('Value error!')
5.2 缺失值处理函数
将缺失值替换为该列的众数或平均数
def missing_values_processing(df, col, func=1):
"""
缺失值处理
:param df: DataFrame resource
:param func: 默认为1, 众数填充; 0, 去除带空值
:return:
"""
if func == 1:
df.loc[:, col].fillna(df.loc[:, col].mode()[0], inplace=True)
elif func == 0:
df.loc[:, col].fillna(df.loc[:, col].mean(), inplace=True)
else:
print('parameter wrong!')
6、 数据清洗
6.1 异常值处理
df1_train = df1
# 工作年限,卡持有天数都与年龄有一定关系
error_filling(df1_train, '工作年限', df1_train.年龄-16)
error_filling(df1_train, '持有招行借记卡天数', df1_train.年龄*366)
error_filling(df1_train, '持有招行信用卡天数', (df1_train.年龄-17)*366)
# 将过大的值都限定到一个上限
error_filling(df1_train, '年龄', 55, value=55, func=2)
error_filling(df1_train, '工作年限', 25, value=25, func=2)
error_filling(df1_train, '首次代发工资距今天数', 50, value=50, func=2)
error_filling(df1_train, '近12个月理财产品购买次数', 20, value=20, func=2)
error_filling(df1_train, '近12个月基金购买次数', 20, value=20, func=2)
error_filling(df1_train, '近12个月保险购买次数', 5, value=5, func=2)
error_filling(df1_train, '近12个月黄金购买次数', 15, value=15, func=2)
error_filling(df1_train, '30天以上逾期贷款的总笔数', 10, value=10, func=2)
error_filling(df1_train, '历史贷款最长逾期天数', 50, value=50, func=2)
error_filling(df1_train, '招行信用卡持卡最高等级代码', 40, value=40, func=2)
error_filling(df1_train, '持有招行借记卡张数', 25, value=25, func=2)
error_filling(df1_train, '持有招行信用卡张数', 20, value=20, func=2)
6.2 缺失值处理
将缺失的值都填充为该列众数
missing_values_processing(df1_train, '工作年限')
missing_values_processing(df1_train, '工商标识')
missing_values_processing(df1_train, '法人或股东标识')
missing_values_processing(df1_train, '下载并登录招行APP标识')
missing_values_processing(df1_train, '下载并绑定掌上生活标识')
missing_values_processing(df1_train, '有车一族标识')
missing_values_processing(df1_train, '有房一族标识')
missing_values_processing(df1_train, '近6个月代发工资标识')
missing_values_processing(df1_train, '首次代发工资距今天数')
missing_values_processing(df1_train, '有效投资风险评估标识')
missing_values_processing(df1_train, '用户理财风险承受能力等级代码')
missing_values_processing(df1_train, '投资强风评等级类型代码')
missing_values_processing(df1_train, '用户投资风险承受级别')
missing_values_processing(df1_train, '总资产级别代码')
missing_values_processing(df1_train, '潜力资产等级代码')
missing_values_processing(df1_train, '近12个月理财产品购买次数')
missing_values_processing(df1_train, '近12个月基金购买次数')
missing_values_processing(df1_train, '近12个月保险购买次数')
missing_values_processing(df1_train, '近12个月黄金购买次数')
missing_values_processing(df1_train, '贷款用户标识')
missing_values_processing(df1_train, '30天以上逾期贷款的总笔数')
missing_values_processing(df1_train, '历史贷款最长逾期天数')
missing_values_processing(df1_train, '招行信用卡持卡最高等级代码')
missing_values_processing(df1_train, '信用卡活跃标识')
missing_values_processing(df1_train, '最近一年信用卡消费金额分层')
missing_values_processing(df1_train, '信用卡还款方式')
6.3 去除共线性
将相互之间热力值高的特征列去掉,仅保留一列
# 标签数据
df1_train.drop(columns='本年月均代发金额分层', inplace=True)
df1_train.drop(columns='用户理财风险承受能力等级代码', inplace=True)
df1_train.drop(columns='个贷授信总额度分层', inplace=True)
df1_train.drop(columns=r'婚姻_\N', inplace=True)
df1_train.drop(columns=r'教育程度_\N', inplace=True)
df1_train.drop(columns=r'学历_\N', inplace=True)
df1_train.drop(columns=r'学位_\N', inplace=True)
# 交易行为数据
df2_pivot.drop('交易次数', axis=1, level=1, inplace=True)
df2_pivot.drop(('交易方向', 'B'), axis=1, inplace=True)
df2_pivot.drop(('收支一级分类代码', 2), axis=1, inplace=True)
df2_pivot.drop(('交易方向', 'C'), axis=1, inplace=True)
df2_pivot.drop(('支付方式', 'A'), axis=1, inplace=True)
df2_pivot.drop(('收支一级分类代码', 1), axis=1, inplace=True)
df2_pivot.drop(('收支二级分类代码', 134), axis=1, inplace=True)
# APP行为数据
df3_pivot.drop(columns=('页面编码', 'FTR'), inplace=True)
df3_pivot.drop(columns=('访问时间', '浏览总次数'), inplace=True)
df3_pivot.drop(columns=('页面编码', 'BWA'), inplace=True)
df3_pivot.drop(columns=('页面编码', 'EGA'), inplace=True)
df3_pivot.drop(columns=('页面编码', 'LCT'), inplace=True)
6.4 合并三表格
合并后无交易行为或APP行为的用户该部分数据会变为Nan值,需要进行填充。既然没有该行为,那么用0来填充。
df_total = pd.merge(df1_train, df2_pivot, how='left', on='用户标识')
df_total = pd.merge(df_total, df3_pivot, how='left', on='用户标识')
# 将df1中无交易行为或APP行为的用户数据填充为零
df_total.fillna(0, inplace=True)
6.5 修改名字会导致训练异常的列
后续训练中发现,xgboost训练模型会对列名中’[’, ‘<’ 和 ‘]’ 字符的列报错,所以需要修改相应列的名字,用正则表达式修改:
import re
regex = re.compile(r"\[|\]|<", re.IGNORECASE)
df_total.columns = [regex.sub("_", str(col)) if any(str(x) in str(col) for x in set(('[', ']', '<'))) else str(col) for col in df_total.columns.values]
6.6 去掉与训练无关的用户标识列
df_total.drop(columns='用户标识', inplace=True)
6.7 重新采样,平衡类别
from imblearn.over_sampling import RandomOverSampler
# 分离训练特征和标签
X = df_total.drop(['目标变量'], axis=1)
y = df_total['目标变量']
ros =RandomOverSampler(random_state=0)
X_resample, y_resample = ros.fit_sample(X, y)
检验一下:
Input:
print(X_resample.shape[0])
print(y_resample.shape[0])
print(y_resample.value_counts())
Output:
61940
61940
1 30970
0 30970
Name: 目标变量, dtype: int64
Process finished with exit code 0
6.8 划分训练集和测试集,为建模训练模型作准备
x_train, x_test, y_train, y_test = train_test_split(X_resample, y_resample, test_size=0.2)
# 分层k折交叉拆分器 - 用于网格搜索
cv = StratifiedKFold(n_splits=3,shuffle=True)
# 分类模型性能查看函数
def performance_clf(model, X, y, name=None):
y_predict = model.predict(X)
if name:
print(name, ':')
print(f'accuracy score is: {accuracy_score(y,y_predict)}')
print(f'precision score is: {precision_score(y,y_predict)}')
print(f'recall score is: {recall_score(y,y_predict)}')
print(f'auc: {roc_auc_score(y,y_predict)}')
print('- - - - - - ')
7、 模型训练-xgboost模型
鉴于时间和提交次数有限,本次比赛只使用了这一个模型,广泛用于Kaggle比赛中
Input:
# xgboost 模型
xgb_clf = xgb.XGBClassifier(objective='binary:logistic',
n_jobs=-1,
booster='gbtree',
n_estimators=1000,
learning_rate=0.01)
# 参数设定
xgb_params = {'max_depth':[6, 9],
'subsample': [0.6, 0.9],
'colsample_bytree': [0.5, 0.6],
'reg_alpha': [0.05, 0.1]}
# 参数搜索
xgb_gridsearch = GridSearchCV(xgb_clf, xgb_params, cv=cv, n_jobs=-1,
scoring='roc_auc', verbose=10, refit=True)
# 工作流管道
pipe_xgb = Pipeline([
('sc', StandardScaler()), # 标准化Z-score
('pow_trans', PowerTransformer()), # 纠偏
('xgb_grid', xgb_gridsearch)
])
# 搜索参数并训练模型
pipe_xgb.fit(x_train, y_train)
# 最佳参数组合
print(pipe_xgb.named_steps['xgb_grid'].best_params_)
# 训练集性能指标
performance_clf(pipe_xgb, x_train, y_train, name='train')
# 测试集性能指标
performance_clf(pipe_xgb, x_test, y_test, name='test')
Output:
Fitting 3 folds for each of 16 candidates, totalling 48 fits
[Parallel(n_jobs=-1)]: Using backend LokyBackend with 8 concurrent workers.
[CV] colsample_bytree=0.5, max_depth=6, reg_alpha=0.1, subsample=0.6 .
[CV] colsample_bytree=0.5, max_depth=6, reg_alpha=0.05, subsample=0.9
[CV] colsample_bytree=0.5, max_depth=6, reg_alpha=0.05, subsample=0.9
[CV] colsample_bytree=0.5, max_depth=6, reg_alpha=0.05, subsample=0.6
[CV] colsample_bytree=0.5, max_depth=6, reg_alpha=0.05, subsample=0.6
[CV] colsample_bytree=0.5, max_depth=6, reg_alpha=0.1, subsample=0.6 .
[CV] colsample_bytree=0.5, max_depth=6, reg_alpha=0.05, subsample=0.6
[CV] colsample_bytree=0.5, max_depth=6, reg_alpha=0.05, subsample=0.9
[CV] colsample_bytree=0.5, max_depth=6, reg_alpha=0.05, subsample=0.6, score=0.824, total= 7.4min
[CV] colsample_bytree=0.5, max_depth=6, reg_alpha=0.1, subsample=0.6 .
[CV] colsample_bytree=0.5, max_depth=6, reg_alpha=0.1, subsample=0.6, score=0.824, total= 7.4min
[CV] colsample_bytree=0.5, max_depth=6, reg_alpha=0.05, subsample=0.6, score=0.827, total= 7.4min
[Parallel(n_jobs=-1)]: Done 2 tasks | elapsed: 7.4min
[CV] colsample_bytree=0.5, max_depth=6, reg_alpha=0.1, subsample=0.9 .
[CV] colsample_bytree=0.5, max_depth=6, reg_alpha=0.1, subsample=0.9 .
[CV] colsample_bytree=0.5, max_depth=6, reg_alpha=0.05, subsample=0.6, score=0.827, total= 7.4min
[CV] colsample_bytree=0.5, max_depth=6, reg_alpha=0.1, subsample=0.6, score=0.828, total= 7.4min
[CV] colsample_bytree=0.5, max_depth=6, reg_alpha=0.1, subsample=0.9 .
[CV] colsample_bytree=0.5, max_depth=9, reg_alpha=0.05, subsample=0.6
[CV] colsample_bytree=0.5, max_depth=6, reg_alpha=0.05, subsample=0.9, score=0.824, total= 7.4min
[CV] colsample_bytree=0.5, max_depth=9, reg_alpha=0.05, subsample=0.6
[CV] colsample_bytree=0.5, max_depth=6, reg_alpha=0.05, subsample=0.9, score=0.829, total= 7.4min
[CV] colsample_bytree=0.5, max_depth=6, reg_alpha=0.05, subsample=0.9, score=0.828, total= 7.4min
[CV] colsample_bytree=0.5, max_depth=9, reg_alpha=0.05, subsample=0.6
[CV] colsample_bytree=0.5, max_depth=9, reg_alpha=0.05, subsample=0.9
[CV] colsample_bytree=0.5, max_depth=6, reg_alpha=0.1, subsample=0.6, score=0.827, total= 7.1min
[Parallel(n_jobs=-1)]: Done 9 tasks | elapsed: 14.5min
[CV] colsample_bytree=0.5, max_depth=9, reg_alpha=0.05, subsample=0.9
[CV] colsample_bytree=0.5, max_depth=6, reg_alpha=0.1, subsample=0.9, score=0.824, total= 7.1min
[CV] colsample_bytree=0.5, max_depth=9, reg_alpha=0.05, subsample=0.9
[CV] colsample_bytree=0.5, max_depth=6, reg_alpha=0.1, subsample=0.9, score=0.829, total= 7.1min
[CV] colsample_bytree=0.5, max_depth=9, reg_alpha=0.1, subsample=0.6 .
[CV] colsample_bytree=0.5, max_depth=6, reg_alpha=0.1, subsample=0.9, score=0.828, total= 7.1min
[CV] colsample_bytree=0.5, max_depth=9, reg_alpha=0.1, subsample=0.6 .
[CV] colsample_bytree=0.5, max_depth=9, reg_alpha=0.05, subsample=0.6, score=0.887, total=10.2min
[CV] colsample_bytree=0.5, max_depth=9, reg_alpha=0.1, subsample=0.6 .
[CV] colsample_bytree=0.5, max_depth=9, reg_alpha=0.05, subsample=0.6, score=0.886, total=10.2min
[CV] colsample_bytree=0.5, max_depth=9, reg_alpha=0.1, subsample=0.9 .
[CV] colsample_bytree=0.5, max_depth=9, reg_alpha=0.05, subsample=0.6, score=0.883, total=10.2min
[CV] colsample_bytree=0.5, max_depth=9, reg_alpha=0.1, subsample=0.9 .
[CV] colsample_bytree=0.5, max_depth=9, reg_alpha=0.05, subsample=0.9, score=0.891, total=10.3min
[Parallel(n_jobs=-1)]: Done 16 tasks | elapsed: 17.7min
[CV] colsample_bytree=0.5, max_depth=9, reg_alpha=0.1, subsample=0.9 .
[CV] colsample_bytree=0.5, max_depth=9, reg_alpha=0.1, subsample=0.6, score=0.887, total=10.5min
[CV] colsample_bytree=0.6, max_depth=6, reg_alpha=0.05, subsample=0.6
[CV] colsample_bytree=0.5, max_depth=9, reg_alpha=0.1, subsample=0.6, score=0.883, total=10.5min
[CV] colsample_bytree=0.6, max_depth=6, reg_alpha=0.05, subsample=0.6
[CV] colsample_bytree=0.5, max_depth=9, reg_alpha=0.05, subsample=0.9, score=0.886, total=10.5min
[CV] colsample_bytree=0.6, max_depth=6, reg_alpha=0.05, subsample=0.6
[CV] colsample_bytree=0.5, max_depth=9, reg_alpha=0.05, subsample=0.9, score=0.890, total=10.5min
[CV] colsample_bytree=0.6, max_depth=6, reg_alpha=0.05, subsample=0.9
[CV] colsample_bytree=0.5, max_depth=9, reg_alpha=0.1, subsample=0.6, score=0.886, total= 9.8min
[CV] colsample_bytree=0.6, max_depth=6, reg_alpha=0.05, subsample=0.9
[CV] colsample_bytree=0.5, max_depth=9, reg_alpha=0.1, subsample=0.9, score=0.891, total= 9.9min
[CV] colsample_bytree=0.6, max_depth=6, reg_alpha=0.05, subsample=0.9
[CV] colsample_bytree=0.5, max_depth=9, reg_alpha=0.1, subsample=0.9, score=0.886, total= 9.9min
[CV] colsample_bytree=0.6, max_depth=6, reg_alpha=0.1, subsample=0.6 .
[CV] colsample_bytree=0.5, max_depth=9, reg_alpha=0.1, subsample=0.9, score=0.890, total= 9.8min
[CV] colsample_bytree=0.6, max_depth=6, reg_alpha=0.1, subsample=0.6 .
[CV] colsample_bytree=0.6, max_depth=6, reg_alpha=0.05, subsample=0.6, score=0.825, total= 7.7min
[CV] colsample_bytree=0.6, max_depth=6, reg_alpha=0.1, subsample=0.6 .
[Parallel(n_jobs=-1)]: Done 25 tasks | elapsed: 32.7min
[CV] colsample_bytree=0.6, max_depth=6, reg_alpha=0.05, subsample=0.6, score=0.829, total= 7.7min
[CV] colsample_bytree=0.6, max_depth=6, reg_alpha=0.1, subsample=0.9 .
[CV] colsample_bytree=0.6, max_depth=6, reg_alpha=0.05, subsample=0.6, score=0.829, total= 7.8min
[CV] colsample_bytree=0.6, max_depth=6, reg_alpha=0.1, subsample=0.9 .
[CV] colsample_bytree=0.6, max_depth=6, reg_alpha=0.05, subsample=0.9, score=0.830, total= 7.8min
[CV] colsample_bytree=0.6, max_depth=6, reg_alpha=0.1, subsample=0.9 .
[CV] colsample_bytree=0.6, max_depth=6, reg_alpha=0.05, subsample=0.9, score=0.824, total= 7.8min
[CV] colsample_bytree=0.6, max_depth=9, reg_alpha=0.05, subsample=0.6
[CV] colsample_bytree=0.6, max_depth=6, reg_alpha=0.05, subsample=0.9, score=0.829, total= 7.8min
[CV] colsample_bytree=0.6, max_depth=9, reg_alpha=0.05, subsample=0.6
[CV] colsample_bytree=0.6, max_depth=6, reg_alpha=0.1, subsample=0.6, score=0.829, total= 7.8min
[CV] colsample_bytree=0.6, max_depth=9, reg_alpha=0.05, subsample=0.6
[CV] colsample_bytree=0.6, max_depth=6, reg_alpha=0.1, subsample=0.6, score=0.825, total= 7.8min
[CV] colsample_bytree=0.6, max_depth=9, reg_alpha=0.05, subsample=0.9
[CV] colsample_bytree=0.6, max_depth=6, reg_alpha=0.1, subsample=0.6, score=0.828, total= 7.8min
[CV] colsample_bytree=0.6, max_depth=9, reg_alpha=0.05, subsample=0.9
[CV] colsample_bytree=0.6, max_depth=6, reg_alpha=0.1, subsample=0.9, score=0.829, total= 7.9min
[CV] colsample_bytree=0.6, max_depth=9, reg_alpha=0.05, subsample=0.9
[CV] colsample_bytree=0.6, max_depth=6, reg_alpha=0.1, subsample=0.9, score=0.824, total= 7.9min
[CV] colsample_bytree=0.6, max_depth=9, reg_alpha=0.1, subsample=0.6 .
[CV] colsample_bytree=0.6, max_depth=6, reg_alpha=0.1, subsample=0.9, score=0.829, total= 7.9min
[CV] colsample_bytree=0.6, max_depth=9, reg_alpha=0.1, subsample=0.6 .
[Parallel(n_jobs=-1)]: Done 38 out of 48 | elapsed: 46.2min remaining: 12.2min
[CV] colsample_bytree=0.6, max_depth=9, reg_alpha=0.05, subsample=0.6, score=0.888, total=10.8min
[CV] colsample_bytree=0.6, max_depth=9, reg_alpha=0.1, subsample=0.6 .
[CV] colsample_bytree=0.6, max_depth=9, reg_alpha=0.05, subsample=0.6, score=0.884, total=10.8min
[CV] colsample_bytree=0.6, max_depth=9, reg_alpha=0.1, subsample=0.9 .
[CV] colsample_bytree=0.6, max_depth=9, reg_alpha=0.05, subsample=0.6, score=0.888, total=10.8min
[CV] colsample_bytree=0.6, max_depth=9, reg_alpha=0.1, subsample=0.9 .
[CV] colsample_bytree=0.6, max_depth=9, reg_alpha=0.05, subsample=0.9, score=0.892, total=10.9min
[CV] colsample_bytree=0.6, max_depth=9, reg_alpha=0.1, subsample=0.9 .
[CV] colsample_bytree=0.6, max_depth=9, reg_alpha=0.05, subsample=0.9, score=0.886, total=10.9min
[CV] colsample_bytree=0.6, max_depth=9, reg_alpha=0.1, subsample=0.6, score=0.888, total=10.8min
[CV] colsample_bytree=0.6, max_depth=9, reg_alpha=0.1, subsample=0.6, score=0.884, total=10.8min
[Parallel(n_jobs=-1)]: Done 43 out of 48 | elapsed: 51.5min remaining: 6.0min
[CV] colsample_bytree=0.6, max_depth=9, reg_alpha=0.05, subsample=0.9, score=0.890, total=10.9min
[CV] colsample_bytree=0.6, max_depth=9, reg_alpha=0.1, subsample=0.6, score=0.888, total= 8.7min
[CV] colsample_bytree=0.6, max_depth=9, reg_alpha=0.1, subsample=0.9, score=0.886, total= 8.8min
[CV] colsample_bytree=0.6, max_depth=9, reg_alpha=0.1, subsample=0.9, score=0.892, total= 8.8min
[CV] colsample_bytree=0.6, max_depth=9, reg_alpha=0.1, subsample=0.9, score=0.891, total= 8.8min
[Parallel(n_jobs=-1)]: Done 48 out of 48 | elapsed: 55.0min remaining: 0.0s
[Parallel(n_jobs=-1)]: Done 48 out of 48 | elapsed: 55.0min finished
{'colsample_bytree': 0.6, 'max_depth': 9, 'reg_alpha': 0.1, 'subsample': 0.9}
train :
accuracy score is: 0.8878955440749112
precision score is: 0.8931096859069232
recall score is: 0.8802625714169942
auc: 0.8878657769238713
- - - - - -
test :
accuracy score is: 0.8361317403939296
precision score is: 0.8516256808054135
recall score is: 0.8202193609918932
auc: 0.8363848978159398
- - - - - -
Process finished with exit code 0
8、预测并生成结果
评分集数据需要从头进行数据预处理,过程同训练集基本一致。
唯一需要注意的是pandas内置的get_dummies()方法会使所以非数值型数据的种类各占一列。因为训练集和测试集不是一起处理的,会导致部分列不同,无法直接预测。
这时需要手动在在训练集和测试集插入彼此缺失的列,或者删除不同的列。
我的解决方案是先用insert方法插入值为None的缺失列,再用to_numeric方法,errors=‘coerce’,将其转换为Nan值。最后用fillna方法将所以Nan值转为0
文章过长,评分集的具体操作就不赘述了。