详解nginx的原生被动健康检查机制&灾备使用(含测试)
nginx作为一个集web服务器、cache、7层lb于一身的全能型选手,已经应用到互联网各种领域,其高性能、易使用的技术品质深得人心,连同在其基础上二开的tengine、openresty都有很大的用户量,今天剖开讲一下nginx健康检查和灾备的机制。
先简单说一下在生产环境的应用场景,健康检查就不多讲了,目的是为了实时摘掉有问题的后端。说一下灾备,我们业务上是为了做专线和公网的互备,因为有海外的服务,平时国内外系统内部的通信走专线,专线在公司内部所有业务共享使用,但专线也有异常的时候,比如说突然有业务使用不合理跑满了,比如说光纤断了,跨国专线出现这种问题并不意外,很难控制的,所以这时候就需要业务有一个切换机制,双保险,当专线出问题时可以迅速走公网,虽然公网质量差点,但起码是可以服务的,比起不可用来说稍微慢点已经不是问题了(尴尬的是多次将专线跑满是自己负责的另一A业务)。
继续分析问题,国内外是通过Http Api的方式进行相互调用的,同样的业务属性,本着用最简单优雅的方式解决问题,用nginx自身的backup配置是最合适不过了,简单高效,大家都能迅速看懂,将来变更也利于传承。
既然要用nginx,我们就需要了解详细机制,只有了解了在出问题时才知道各种参数如何配置,在出了问题后怎么排查,现在就拆开讲一下nginx这个健康检查和灾备是如何触发如何生效的。
nginx的健康检查有两种,一种是nginx原生的,这种健康检查是一种被动的健康检查,通过线上流量的做测试,另一种是主动的健康检查,需要编译安装的第三方模块,通过主动周期性向后端发送请求来判断后端的健康情况,探测的方式可以是TCP和HTTP,灵活配置,现在主要剖析一下原生被动的健康检查和灾备触发。
原生被动健康检查&灾备原理
为了方便理解,画了一张流程图:

在nginx里,控制健康检查的指令主要有3个,控制灾备的质量是1个,上图以配置了3个upstream server的情况为例,画了下概要逻辑,以图为例说一下具体的流程判断。
max_fails和fail_timeout是搭配使用的一组命令,指的是请求过来后,fail_timout时间内出现max_fails次fails本server就不可用,并惩罚fail_timeout时间不分发请求过来(就是把后端摘掉一个周期),代码实现上是nginx内部有一个对fails的计数,每增加一次错误计数就加1,同时做是否健康判断,当惩罚一个fail_timeout周期后,fails的计数清零,请求重新分发到这台后端,循环健康检查,有两个注意的点,同一次请求在每个upstrem server不会重复重试,在没有backup server的情况下,当所有的upstream server都不可用后,fails的计数清零,一次性将所有server恢复到健康状态。
那么这个fails怎么定义呢?如图,是由永久错误和选择性定义错误来控制的,选择性定义是由proxy_next_uptream指令控制,这个指令定义了哪种类型会也被认为是错误,默认是error timout,就是错误和超时,看一下英文描述很清楚,有些错误是双刃剑,比如500,很多时候线上就有500错误,是否要用作其摘掉后端的标准,得斟酌考虑。:
● error — an error has occurred while connecting to the server, sending a request to it, or reading its response;
● timeout — occurred timeout during the connection with the server, transfer the requst or while reading response from the server;
● invalid_header — server returned a empty or incorrect answer;
● http_500 — server returned answer with code 500
● http_503 — server returned answer with code 503
● http_404 — server returned answer with code 404
那么timeout有哪些指令来触发呢?对应图看,主要是3个,proxy_connect_timeout proxy_read_timeout proxy_send_timeout,含义看图。
什么情况下要把proxy_next_upstream关掉呢?关掉就是取消自定义错误,同时不会进行下一个server的重试,有些情况必须关掉的,比如会产生重复提交,简单说充钱的场景,如果冲1000块钱,请求已经传到后端,但当前后端太慢nginx判断后端超时后又将请求转到第二个后端,但其实第一个充钱逻辑后端还在执行,比如在第二个后端充钱成功,这样就会出现充了2000块钱的情况。
backup啥时生效,啥时失效?如图当所有upstrem server不可用时,backup server生效,一但有server恢复,就使用正常server,backup生效期间不会走一次性server全部恢复的逻辑。
实验环境测试
场景1nginx的相关配置如下,不加backend,随便写了2个网络不可达的后端
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
|
测试命令
| 1 |
|
连续访问,访问日志如下
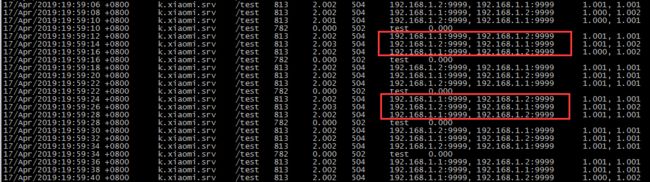
通过访问日志发现,每次访问都是重试了1.1和1.2两个后端server,且访问3次后,从504切换成一次502,然后循环如此,同时每个后端的访问时间都是1s左右。
查看error日志对应如下:

通过error查看每次502时,出现一个没有存活的error日志,继而继续循环。
场景2nginx的相关配置如下,加上灾备backend
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
|
access的访问日志如下

通过日志可以看到,第一次访问由于1.1、1.2都不可用,就走到backend了,访问3次后两个server都不可用,直接只走backup,时间间隔大概10s后再次进行全部探测。