用NEON intrinsic实现RGB转YUV420SP(NV12)
如题,现在要把RGB的格式转成YUV格式。
1. 数据的排列方式
先来看看两种数据在内存里是按什么方式排列的
1.1 RGB的排列
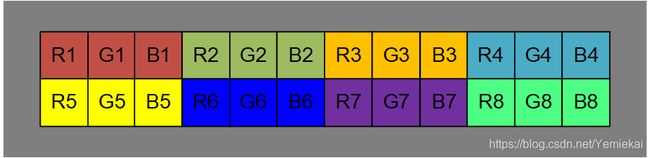
如图所示,1组RGB表示1个像素的颜色,每个像素依次排列。图中有8组RGB数据,即8个像素点。
1.2 YUV的排列
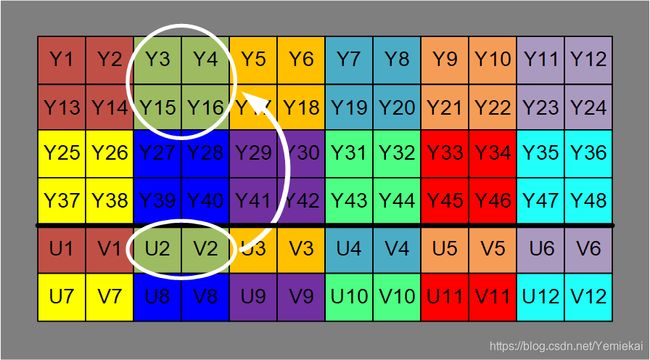
如图所示,这里是 YUV420SP(NV12) 的排列方式,YUV的比例为Y:U:V=4:1:1。Y代表像素点的明亮度(灰阶),图中有48个Y,即48个像素点。UV代表像素点的色度,1个U和1个V组合到一起能表示一种颜色,在YUV420格式里,1组UV决定了4个像素点的颜色,其对应关系如图所示。U和V加起来的数据量是Y的一半。
YUV的图片还有许多种格式,请参考其它资料。
实际上它在内存里面是按照 Y 1 Y 2 Y 3 Y 4 Y 5 Y 6 Y 7 Y 8 U 1 V 1 U 2 V 2 Y_1Y_2Y_3Y_4Y_5Y_6Y_7Y_8U_1V_1U_2V_2 Y1Y2Y3Y4Y5Y6Y7Y8U1V1U2V2的顺序排列的,如下图所示。存储的时候数据是连续排列的,解析的时候加上宽和高的信息才成为了一张矩形图片。写代码计算地址偏移的时候要注意行和列的关系。
![]()
2. RGB与YUV的转换公式
不知道哪里来的公式,但据说是总所周知的。
2.1 RGB转YUV
Y = (0.257*R) + (0.504*G) + (0.098*B) + 16
Cb = U = -(0.148*R) - (0.291*G) + (0.439*B) + 128
Cr = V = (0.439*R) - (0.368*G) - (0.071*B) + 128
这个公式里面有很多小数,运算起来效率不高,整数的运算会快一点。于是就有了下面的代码:
Y = ( ( 66*R + 129*G + 25*B) >> 8) + 16;
U = ( (-38*R - 74*G + 112*B) >> 8) + 128;
V = ( (112*R - 94*G - 18*B) >> 8) + 128;
什么原理呢?以Y为例,本来Y是:
Y = (0.257*R) + (0.504*G) + (0.098*B) + 16
乘以256,再除以256:
Y = ( 256*0.257*R + 256*0.504*G + 256*0.098*B )/256 + 16
Y = ( 65.792*R + 129.024*G + 25.088*B )/256 + 16
舍掉小数部分(因为已经放大256倍了,牺牲一点精度影响不大,后面计算用的无符号8Bit色深,不用太讲究小数点后的位数)。于是:
Y = ( 65*R + 129*G + 25*B )/256 + 16
众所周知,除法可以用位移来计算,而且速度更快。这里 256 = 2 8 256=2^8 256=28 ,数据在计算机中以二进制的形式存储,因此除以256即向右移8位。于是:
Y = ( ( 65*R + 129*G + 25*B ) >> 8 ) + 16
U和V同理。
2.2 YUV转RGB
也是两个版本:
R = 1.164(Y - 16) + 1.596(V - 128)
G = 1.164(Y - 16) - 0.391(U - 128) - 0.813(V - 128)
B = 1.164(Y - 16) + 2.018(U - 128)
R = Y + ((360 * (V - 128))>>8) ;
G = Y - (( ( 88 * (U - 128) + 184 * (V - 128)) )>>8) ;
B = Y + ((455 * (U - 128))>>8) ;
3. 代码
这里参考https://www.jianshu.com/p/e498326a55b1?utm_campaign的代码:
3.1 常规版本:
typedef unsigned char byte;
void RGBtoNV12(byte* pNV12, byte* pRGB, int width, int height)
{
int frameSize = width * height;
int yIndex = 0;
int uvIndex = frameSize;
int R, G, B, Y, U, V;
int index = 0;
for (int j = 0; j < height; j++)
{
for (int i = 0; i < width; i++)
{
R = pRGB[index++];
G = pRGB[index++];
B = pRGB[index++];
Y = ((66 * R + 129 * G + 25 * B + 128) >> 8) + 16;
U = ((-38 * R - 74 * G + 112 * B + 128) >> 8) + 128;
V = ((112 * R - 94 * G - 18 * B + 128) >> 8) + 128;
// NV12 YYYYYYYY UVUV
// NV21 YYYYYYYY VUVU
pNV12[yIndex++] = (byte)((Y < 0) ? 0 : ((Y > 255) ? 255 : Y));
if (j % 2 == 0 && index % 2 == 0)
{
pNV12[uvIndex++] = (byte)((U < 0) ? 0 : ((U > 255) ? 255 : U));
pNV12[uvIndex++] = (byte)((V < 0) ? 0 : ((V > 255) ? 255 : V));
}
}
}
}
3.2 NEON版本:
typedef unsigned char byte;
void RGB_to_NV12_intrinsic(byte* pNV12, byte* pRGB, int width, int height)
{
const uint8x8_t u8_zero = vdup_n_u8(0);
const uint8x8_t u8_16 = vdup_n_u8(16);
const uint16x8_t u16_rounding = vdupq_n_u16(128);
const int16x8_t s16_zero = vdupq_n_s16(0);
const int8x8_t s8_rounding = vdup_n_s8(-128);
const int16x8_t s16_rounding = vdupq_n_s16(128);
byte* UVPtr = pNV12 + width * height;
int pitch = width >> 4;
for (int j = 0; j < height; ++j)
{
for (int i = 0; i < pitch; ++i)
{
// Load RGB 16 pixel
uint8x16x3_t pixel_rgb = vld3q_u8(pRGB);
uint8x8_t high_r = vget_high_u8(pixel_rgb.val[0]);
uint8x8_t low_r = vget_low_u8(pixel_rgb.val[0]);
uint8x8_t high_g = vget_high_u8(pixel_rgb.val[1]);
uint8x8_t low_g = vget_low_u8(pixel_rgb.val[1]);
uint8x8_t high_b = vget_high_u8(pixel_rgb.val[2]);
uint8x8_t low_b = vget_low_u8(pixel_rgb.val[2]);
// NOTE:
// declaration may not appear after executable statement in block
uint16x8_t high_y;
uint16x8_t low_y;
uint8x8_t scalar = vdup_n_u8(66); // scalar = 66
high_y = vmull_u8(high_r, scalar); // Y = R * 66
low_y = vmull_u8(low_r, scalar);
scalar = vdup_n_u8(129);
high_y = vmlal_u8(high_y, high_g, scalar); // Y = Y + R*129
low_y = vmlal_u8(low_y, low_g, scalar);
scalar = vdup_n_u8(25);
high_y = vmlal_u8(high_y, high_b, scalar); // Y = Y + B*25
low_y = vmlal_u8(low_y, low_b, scalar);
high_y = vaddq_u16(high_y, u16_rounding); // Y = Y + 128
low_y = vaddq_u16(low_y, u16_rounding);
uint8x8_t u8_low_y = vshrn_n_u16(low_y, 8); // Y = Y >> 8
uint8x8_t u8_high_y = vshrn_n_u16(high_y, 8);
low_y = vaddl_u8(u8_low_y, u8_16); // Y = Y + 16
high_y = vaddl_u8(u8_high_y, u8_16);
uint8x16_t pixel_y = vcombine_u8(vqmovn_u16(low_y), vqmovn_u16(high_y));
// Store
vst1q_u8(pNV12, pixel_y);
if (j % 2 == 0)
{
uint8x8x2_t mix_r = vuzp_u8(low_r, high_r);
uint8x8x2_t mix_g = vuzp_u8(low_g, high_g);
uint8x8x2_t mix_b = vuzp_u8(low_b, high_b);
int16x8_t signed_r = vreinterpretq_s16_u16(vaddl_u8(mix_r.val[0], u8_zero));
int16x8_t signed_g = vreinterpretq_s16_u16(vaddl_u8(mix_g.val[0], u8_zero));
int16x8_t signed_b = vreinterpretq_s16_u16(vaddl_u8(mix_b.val[0], u8_zero));
int16x8_t signed_u;
int16x8_t signed_v;
int16x8_t signed_scalar = vdupq_n_s16(-38);
signed_u = vmulq_s16(signed_r, signed_scalar);
signed_scalar = vdupq_n_s16(112);
signed_v = vmulq_s16(signed_r, signed_scalar);
signed_scalar = vdupq_n_s16(-74);
signed_u = vmlaq_s16(signed_u, signed_g, signed_scalar);
signed_scalar = vdupq_n_s16(-94);
signed_v = vmlaq_s16(signed_v, signed_g, signed_scalar);
signed_scalar = vdupq_n_s16(112);
signed_u = vmlaq_s16(signed_u, signed_b, signed_scalar);
signed_scalar = vdupq_n_s16(-18);
signed_v = vmlaq_s16(signed_v, signed_b, signed_scalar);
signed_u = vaddq_s16(signed_u, s16_rounding);
signed_v = vaddq_s16(signed_v, s16_rounding);
int8x8_t s8_u = vshrn_n_s16(signed_u, 8);
int8x8_t s8_v = vshrn_n_s16(signed_v, 8);
signed_u = vsubl_s8(s8_u, s8_rounding);
signed_v = vsubl_s8(s8_v, s8_rounding);
signed_u = vmaxq_s16(signed_u, s16_zero);
signed_v = vmaxq_s16(signed_v, s16_zero);
uint16x8_t unsigned_u = vreinterpretq_u16_s16(signed_u);
uint16x8_t unsigned_v = vreinterpretq_u16_s16(signed_v);
uint8x8x2_t result;
result.val[0] = vqmovn_u16(unsigned_u);
result.val[1] = vqmovn_u16(unsigned_v);
vst2_u8(UVPtr, result);
UVPtr += 16;
}
pRGB += 3*16;
pNV12 += 16;
}
}
}
3.3 NEON版本解读:
先看看数据类型:
NEON向量数据类型根据以下模式命名:
例如:
int16x4_t是一个向量,其中包含4个16位的短整型变量(4个lane,每个lane存16位的数)。float32x4_t是一个向量,其中包含4个32位的浮点型变量(4个lane,每个lane存32位的数)。
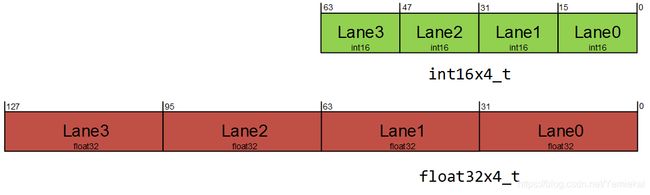
NEON向量结构体根据下列模式命名:
例如:
uint8x16x3_t是一个结构体,其中有一个数组叫val,数组的大小是3。数组中有3个uint8x16类型的向量。

Y的计算:
代码20行,for循环里,最开始有个vld3q_u8:
// 加载16个像素
uint8x16x3_t pixel_rgb = vld3q_u8(pRGB);
这里vld是加载操作,3表示3个元素的解交错(deinterleaving),Q表示使用Q寄存器,u8表示数据类型,也就是向量的一个通道(lane)为8位无符号数据。
所以它从rgb指针指向的地址开始,加载16个像素的RGB数据到3个Q寄存器里,同时解交错,使3个Q寄存器分别存放16个R值,16个G值,16个B值。(Q寄存器刚好128位,16*8=128),如下图所示:
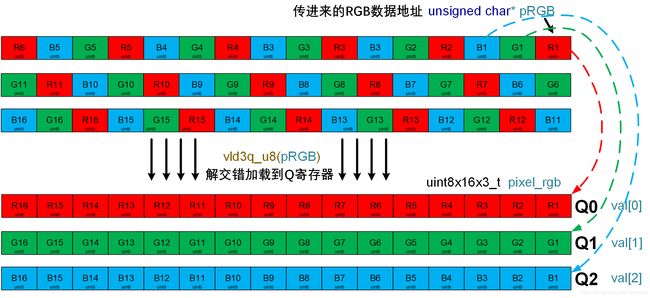
注意现在这里每个lane是u8类型的(8bit),如果直接对它做乘法,乘数较大时,结果可能超出8Bit。要是把结果存回原来的lane,宽度不够会导致结果损失。
因此这里用vget_high_u8和vget_low_u8分别取出高位和低位,分别对高位和低位做操作,按照公式Y = ( ( 65*R + 129*G + 25*B ) >> 8 ) + 16逐步计算,用长指令(指令加L后缀)将宽度增倍存储。
最后用vqmovn_u16将宽度减半,这是一条饱和指令(指令加Q前缀),超出8Bit的数据将被 saturated 到8Bit,即大于255的值结果都是255。然后用vcombine_u8将高位和低位合并,用vst1q_u8存储结果。
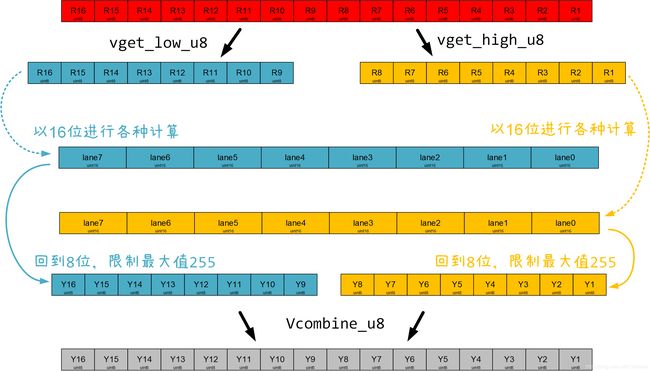
这样Y就计算完了,大概思路是这样,具体计算过程看代码。
UV的计算:
根据前面<1.2 YUV的排列>章节的配图,可以明确Y、UV数据对应关系。结论是:每次到了RGB图片行号为偶数且列号为偶数的位置,就计算一次UV数据,这个UV刚好对应了4个像素点的颜色。(这里的偶数指索引,索引是从0开始的)

偶数行容易判断,在for循环里面判断 j % 2 即可。
偶数列不需要判断,可以直接获取。因为每次循环都加载了处于同一行的16个像素,在到达偶数行的时候,间隔提取16个像素中的数据,该数据就满足了偶数行且偶数列的条件。用vuzp_up可以提取16个像素中偶数列的数据:
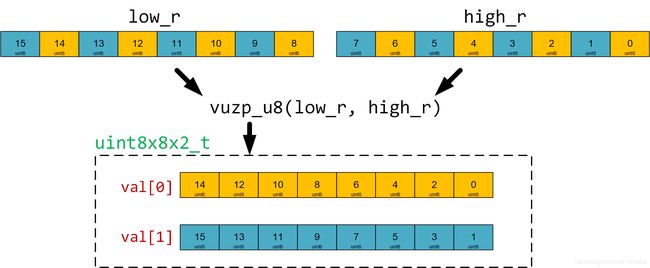
如上图所示,val[0]就是我们要的数据。像这样把对应位置的R、G、B都找出来,就可以愉快地计算UV了,按照公式一步一步计算即可,具体过程看代码。
注意,在unsigned类型转成signed类型,完成计算后再转回signed类型,把结果存到UV指针所指向的地址。
3.4 性能测试
在双核ARM Corte-A7@900MHz的机器上(32位ARMv7架构),用OpenCV 3.4.10加载一张 512 × 288 512\times288 512×288 的RGB24图片,用cv::cvtColor(src, dst, CV_BGR2RGB)转成RGBRGBRGB格式。然后用3种方式对它的data进行转换,各循环100次:
(1) 用OpenCVcv::cvtColor(src, dst, CV_RGB2YUV_I420): 949.69 m s 949.69ms 949.69ms
(2) 用本文代码<常规版本>: 708.81 m s 708.81ms 708.81ms
(2) 用本文代码
相比之下NEON版本速度遥遥领先,图片越大领先越多。
3.5 后话
用汇编对指令进行Schedule后,把对相同寄存器的操作错开,让流水线马力全开,速度更快。但是汇编代码不利于移植,不同的ARM架构之间指令集或有不同,切换平台后需要重新审查代码。而NEON Intrinsic C代码是经过封装了的,比较固定和统一,代码写好后由编译器生成汇编代码并适当地Optimize,能以较低的成本享受NEON带来的加速。
本文代码是基于ARMv7架构的,在64位的ARMv8上速度应该会更快。ARMv8有32个128位NEON寄存器,数量翻了一倍,可以对更多数据并行处理。但是它的NEON寄存器访问形式和支持的数据类型有所改变,代码也要对应修改,目前还没有进行探究。
对齐问题: 本文代码每次取16个像素,如果图片的宽不是16的倍数,就会出问题。有一种方法,把原始数据每行用零padding到16的倍数,就能应对这种问题。OpenCV的IplImage类里面就有这个属性:widthStep。本文代码未对此进行处理。
文中若有不当之处请指出