浅谈JPA三:开始使用Spring-Data-JPA
抛砖引玉
先看一段常用配置文件,看看使用Spring-Data-JPA需要使用到哪些东西吧!
<beans>
<context:property-placeholder location="classpath:your-config.properties" ignore-unresolvable="true" />
<context:component-scan base-package="your service package" />
<aop:aspectj-autoproxy proxy-target-class="true" />
<tx:annotation-driven transaction-manager="transactionManager" proxy-target-class="true" />
<jpa:repositories base-package="your dao package" repository-impl-postfix="Impl" entity-manager-factory-ref="entityManagerFactory" transaction-manager-ref="transactionManager" />
<bean id="entityManagerFactory" class="org.springframework.orm.jpa.LocalContainerEntityManagerFactoryBean">
<property name="dataSource" ref="dataSource" />
<property name="packagesToScan" value="your entity package" />
<property name="persistenceProvider">
<bean class="org.hibernate.ejb.HibernatePersistence" />
property>
<property name="jpaVendorAdapter">
<bean class="org.springframework.orm.jpa.vendor.HibernateJpaVendorAdapter">
<property name="generateDdl" value="false" />
<property name="database" value="MYSQL" />
<property name="databasePlatform" value="org.hibernate.dialect.MySQL5InnoDBDialect" />
bean>
property>
<property name="jpaDialect">
<bean class="org.springframework.orm.jpa.vendor.HibernateJpaDialect" />
property>
<property name="jpaPropertyMap">
<map>
<entry key="hibernate.query.substitutions" value="true 1, false 0" />
<entry key="hibernate.default_batch_fetch_size" value="16" />
<entry key="hibernate.max_fetch_depth" value="2" />
<entry key="hibernate.generate_statistics" value="true" />
<entry key="hibernate.bytecode.use_reflection_optimizer" value="true" />
<entry key="hibernate.cache.use_second_level_cache" value="false" />
<entry key="hibernate.cache.use_query_cache" value="false" />
map>
property>
bean>
<bean id="transactionManager" class="org.springframework.orm.jpa.JpaTransactionManager">
<property name="entityManagerFactory" ref="entityManagerFactory"/>
bean>
<bean id="dataSource" class="com.alibaba.druid.pool.DruidDataSource" init-method="init" destroy-method="close">
<property name="driverClassName" value="${driver}" />
<property name="url" value="${url}" />
<property name="username" value="${userName}" />
<property name="password" value="${password}" />
<property name="initialSize" value="${druid.initialSize}" />
<property name="maxActive" value="${druid.maxActive}" />
<property name="maxIdle" value="${druid.maxIdle}" />
<property name="minIdle" value="${druid.minIdle}" />
<property name="maxWait" value="${druid.maxWait}" />
<property name="removeAbandoned" value="${druid.removeAbandoned}" />
<property name="removeAbandonedTimeout" value="${druid.removeAbandonedTimeout}" />
<property name="timeBetweenEvictionRunsMillis" value="${druid.timeBetweenEvictionRunsMillis}" />
<property name="minEvictableIdleTimeMillis" value="${druid.minEvictableIdleTimeMillis}" />
<property name="validationQuery" value="${druid.validationQuery}" />
<property name="testWhileIdle" value="${druid.testWhileIdle}" />
<property name="testOnBorrow" value="${druid.testOnBorrow}" />
<property name="testOnReturn" value="${druid.testOnReturn}" />
<property name="poolPreparedStatements" value="${druid.poolPreparedStatements}" />
<property name="maxPoolPreparedStatementPerConnectionSize" value="${druid.maxPoolPreparedStatementPerConnectionSize}" />
<property name="filters" value="${druid.filters}" />
bean>
<tx:advice id="txAdvice" transaction-manager="transactionManager">
<tx:attributes>
<tx:method name="*" />
<tx:method name="get*" read-only="true" />
<tx:method name="find*" read-only="true" />
<tx:method name="select*" read-only="true" />
<tx:method name="delete*" propagation="REQUIRED" />
<tx:method name="update*" propagation="REQUIRED" />
<tx:method name="add*" propagation="REQUIRED" />
<tx:method name="insert*" propagation="REQUIRED" />
tx:attributes>
tx:advice>
<aop:config>
<aop:pointcut id="allServiceMethod" expression="execution(* your service implements package.*.*(..))" />
<aop:advisor pointcut-ref="allServiceMethod" advice-ref="txAdvice" />
aop:config>
beans>
介绍
由上面的配置文件可以看出,Spring-Data-JPA并不是一个ORM框架,也不是一个规范,而是一个遵守JPA规范、且借助Hibernate作为实现的框架。它对Hibernate进行进一步封装简化,使开发者通过声明接口即可完成CRUD操作。
这里和Hibernate、Mybatis做个对比:
| hibernate | mybatis | spring-data-jpa |
|---|---|---|
| 需写Dao接口 | 需写Mapper接口 | 需写Repository接口 |
| 需写Dao实现(可使用HQL或Criteria) | 不写Mapper实现(由XML实现:通过ID属性关联接口方法) | 不写Repository实现(根据其接口命名自动生成、@Query注解自写jpql语句或动态查询Predicate) |
注:
- 接口命名自动生成规范详见网络。
- @Query是Spring-data-jpa带有的注解,动态查询Predicate底层即是使用JPA的Criteria。
提供的查询API
Spring data项目所支持的NoSql存储:
- MongoDB 文档数据库
- Neoj4 图形数据库
- Redis 键/值数据库
- Hbase 列族数据库
Spring data项目所支持的关系数据存储:
- Jdbc
- JPA
根据属性名定义查询方法
Spring Data JPA 支持通过定义在Repository 接口中的方法名来定义查询,而方法名是根据实体类的属性名来确定的。
根据属性名来定义查询方法,示例如下:

从代码可以看出,这里使用了findBy 、Like 、And 这样的关键字。其中findBy 可以用find 、read、readBy 、query 、queryBy 、get、getBy 来代替。而Like 和and 这类查询关键字,如表所示:
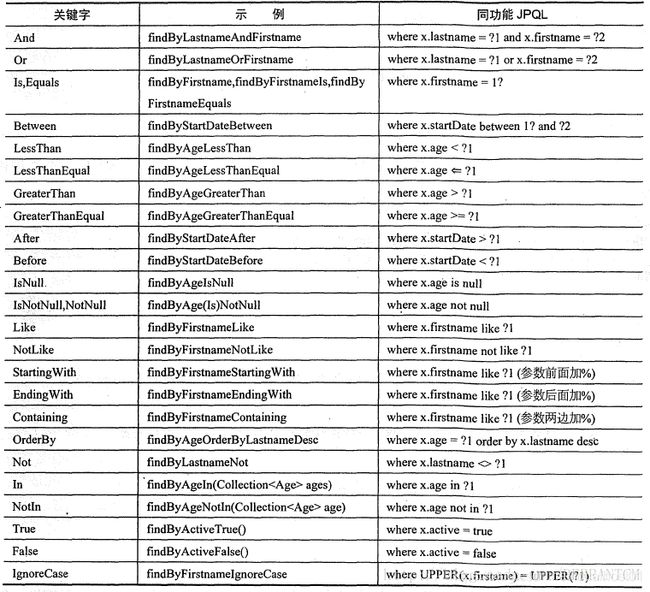
限制结果数量。结果数量是用top 和first 关键字来实现的:


使用JPA的NamedQuery查询
Spring Data JPA 支持用 JPA 的NameQuery 来定义查询方法,即一个名称映射一个查询语句。定义如下:

使用@Query查询
Spring Data JPA 还支持用@Query 注解在接口的方法上实现查询。
- 使用参数索引,例如:

- 使用命名参数。上面的例子是使用参数的索引号来查询的,在Spring Data JPA 里还支持在语句里用名称来匹配查询参数,例如:

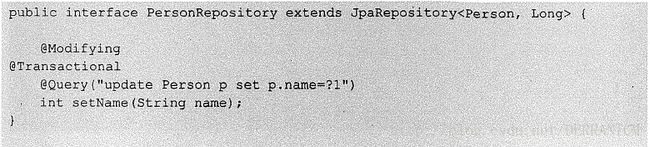
- 更新查询。Spring Data JPA 支持@Modifying 和@Query 注解组合来实现更新查询,其中返回值int 表示更新语句影响的行数
Specification
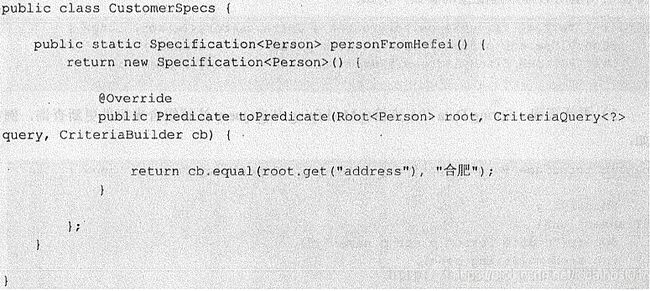
JPA 提供了基于准则查询的方式,即Criteria 查询。而Spring Data JPA 提供了一个Specification (规范)接口让我们可以更方便地构造准则查询, Specification 接口定义了一个toPredicate 方法用来构造查询条件。
我们的接口类必需实现JpaSpecificationExecutor 接口,代码如下:

然后需要定义Criterial查询,代码如下:
Spring Data JPA 充分考虑了在实际开发中所必需的排序和分页的场景,为我们提供了Sort类以及Page 接口和Pageable 接口。

自定义Repository的实现
Spring Data JPA提供了CrudRepository 、PagingAndSortingRepository,Spring Data JPA 也提供了JpaRepository。我们也可以自定义Repository的实现。为了享受 Spring Data JPA 带给我们的便利,同时又能够为部分方法提供自定义实现,我们可以采用如下的方法:
- 将需要开发者手动实现的方法从持久层接口(假设为 AccountDao )中抽取出来,独立成一个新的接口(假设为 AccountDaoPlus ),并让 AccountDao 继承 AccountDaoPlus;
- 为 AccountDaoPlus 提供自定义实现(假设为 AccountDaoPlusImpl );
- 将 AccountDaoPlusImpl 配置为 Spring Bean:
<jpa:repositories base-package="footmark.springdata.jpa.dao">
<jpa:repository id="accountDao" repository-impl-ref=" accountDaoPlus " />
jpa:repositories>
<bean id="accountDaoPlus" class="......."/>
此外,
<jpa:repositories base-package="footmark.springdata.jpa.dao" repository-impl-postfix="Impl"/>
则在框架扫描到 AccountDao 接口时,它将尝试在相同的包目录下查找 AccountDaoImpl.java,如果找到,便将其中的实现方法作为最终生成的代理类中相应方法的实现。
应该继承哪个接口?
持久层接口继承 Repository 并不是唯一选择。Repository 接口是 Spring Data 的一个核心接口,它不提供任何方法,开发者需要在自己定义的接口中声明需要的方法。与继承 Repository 等价的一种方式,就是在持久层接口上使用 @RepositoryDefinition 注解,并为其指定 domainClass 和 idClass 属性。如下两种方式是完全等价的:
public interface UserDao extends Repository<AccountInfo, Long> { …… }
@RepositoryDefinition(domainClass = AccountInfo.class, idClass = Long.class) public interface UserDao { …… }
CrudRepository
如果持久层接口较多,且每一个接口都需要声明相似的增删改查方法,直接继承Repository就显得有些啰嗦,这时可以继承CrudRepository,它会自动为域对象创建增删改查方法,供业务层直接使用。开发者只是多写了 “Crud” 四个字母,即刻便为域对象提供了开箱即用的十个增删改查方法。
但是,使用 CrudRepository 也有副作用,它可能暴露了你不希望暴露给业务层的方法。比如某些接口你只希望提供增加的操作而不希望提供删除的方法。针对这种情况,开发者只能退回到 Repository 接口,然后到** CrudRepository 中把希望保留的方法声明复制到自定义的接口**中即可。
PagingAndSortingRepository
分页查询和排序是持久层常用的功能,Spring Data 为此提供了 PagingAndSortingRepository 接口,它继承自 CrudRepository 接口,在 CrudRepository 基础上新增了两个与分页有关的方法。但是,我们很少会将自定义的持久层接口直接继承自 PagingAndSortingRepository,而是在继承 Repository 或 CrudRepository 的基础上,在自己声明的方法参数列表最后增加一个 Pageable 或 Sort 类型的参数,用于指定分页或排序信息即可,这比直接使用 PagingAndSortingRepository 提供了更大的灵活性。
JpaRepository
JpaRepository 是继承自 PagingAndSortingRepository 的针对 JPA 技术提供的接口,它在父接口的基础上,提供了其他一些方法,比如 flush(),saveAndFlush(),deleteInBatch() 等。如果有这样的需求,则可以继承该接口。
总结
上述四个接口,开发者到底该如何选择?其实依据很简单,根据具体的业务需求,选择其中之一。笔者建议在通常情况下优先选择 Repository 接口。因为 Repository 接口已经能满足日常需求,其他接口能做到的在 Repository 中也能做到,彼此之间并不存在功能强弱的问题。只是 Repository 需要显示声明需要的方法,而其他则可能已经提供了相关的方法,不需要再显式声明,但如果对 Spring Data JPA 不熟悉,别人在检视代码或者接手相关代码时会有疑惑,他们不明白为什么明明在持久层接口中声明了三个方法,而在业务层使用该接口时,却发现有七八个方法可用,从这个角度而言,应该优先考虑使用 Repository 接口。
其他
JPA配置文件
我们知道原生的jpa的配置信息是必须放在META-INF目录下面的,并且名字必须叫做persistence.xml,这个叫做persistence-unit,就叫做持久化单元,放在这下面我们感觉不方便,不好,于是Spring提供了org.springframework.orm.jpa.LocalContainerEntityManagerFactoryBean
这样一个类,可以让你的随心所欲的起这个配置文件的名字,也可以随心所欲的修改这个文件的位置,只需要在这里指向这个位置就行。然而更加方便的做法是,直接把配置信息就写在这里更好,于是就有了这实体管理器这个bean。使用
<property name="packagesToScan" value="your entity package" />
来加载我们的entity。
参考:
-
https://blog.csdn.net/DERRANTCM/article/details/77618993?utm_source=blogxgwz7
-
https://blog.csdn.net/qq_28233015/article/details/80062538?utm_source=blogxgwz12
-
https://www.ibm.com/developerworks/cn/opensource/os-cn-spring-jpa/