用HLS工具在PYNQ-Z2开发板上实现BNN(二值神经网络)硬件加速——毕设小结
用HLS工具在PYNQ-Z2开发板上实现BNN(二值神经网络)硬件加速——毕设小结
本文主要是本人本科毕业设计的主要工作。
主要工作有两部分,一是使用Vivado HLS工具实现二值卷积神经网络模型并完成硬件加速工作,二是将二值神经网络的前向计算过程部署到PYNQ-Z2板上,并在Jupyter Notebook上实现IP核的调用。
BNN参考论文《Binarized Neural Networks Training Neural Networks with Weights and Activations Constrainedto +1 or −1》、《FINN A Framework for Fast, Scalable Binarized Neural Network Inference》。因为毕设要求实现云图像分类的功能,所以训练集由灰度云图组成,格式与mnist数据集相同。训练采用深度学习框架theano,导出训练好的参数,然后在Vivado HLS上实现BNN前向计算的加速过程。

BNN由卷积层、池化层和全连接层组成,主要问题其实只有一个:如何加速卷积?(全连接层主要是乘累加运算,此处可参考卷积层的加速)
卷积加速
卷积的加速主要分为4个层面:位宽加速、算法加速、HLS优化指令加速、访存加速。
位宽加速
位宽加速其实就是用数据精度换取计算速度,这也是二值神经网络参数二值化的主要作用,参数二值化后大大降低了参数量。参数二值化是指我们在训练网络的时候将前向计算的权重进行二值化处理,但反向传播过程中会出现梯度消失的问题(sign函数的导数几乎处处为0),所以反向传播时会进行松弛化处理,将符号函数Sign变为可导函数Htanh,并更新全精度的权重,这里的相关内容可以参考XNOR-NET的论文或者相关文献。主要过程如下图所示:

算法加速
- 乘加优化
算法方面的加速其实就是充分使用二值神经网络的特点进行运算符优化,因为前面我们已经将参数二值化,所以在进行卷积操作的时候可以利用同或操作和计数器代替乘加运算,即使用XNOR和PopCount实现乘加运算,具体可以参考XNOR-Net。

以A=[1,-1,1,1,-1]和W=[-1,1,1,-1,-1]两个向量进行内积运算为例:
正常的乘法运算为1×(-1)+(-1)×1+1×1+1×(-1)+(-1)×(-1)= -1;
从同或运算的角度来看,A=[1,0,1,1,0],W=[0,1,1,0,0]
A 与W 进行异或的结果为A^W=[1,1,0,1,0](HLS 中不存在同或操作,需对异或取反进行同或操作)
PopCount 的作用是计算1的个数来对二进制的乘积进行求和。所以PopCount(A^W)= 3,即结果中有3个-1;所以最终二进制的乘积的结果为(5-PopCount)×1+PopCount×(-1)= 5-2×PopCount= -1.
伪代码如下,其中F 为卷积窗口大小,window_result 为当前卷积窗口的计算结果,weight_buff 为卷积核参数,bit_num 为卷积窗口内数据的总位数。
for (int c = 0; c < F; c++) {
for (int r = 0; r < F; r++) {
bit32 tmp = weight_buff[r][c]^window_buff[r][c];
count += popcount(tmp);
}
}
window_result = bit_num – (count << 1);
}
- 池化优化
普通的最大值池化就是对滑动窗口内的数据进行比较,将其中最大的数据作为该滑动窗口的结果。在BNN计算过程中,最大值池化后还要对输出结果再次进行二值化操作

因为滑动窗口内任意一个值满足大于s 的条件都可以使当前滑动窗口的输出为1,即最大池化操作与计算顺序没有关系,因此二值神经网络的最大值池化操作可以简化为或运算

访存加速
引入缓存,将缓存置于访存速度更快的内存块中,从而加速整个卷积层的计算速度。同时相邻的卷积窗口的数据重复率较高,无需读取大量重复使用的数据。

本文使用了行缓存器和窗缓存器实现了卷积窗口的流水操作,下图为窗口缓存结构示意图:

参数更新过程如下:

伪代码如下:
for (int i = 0; i < F; i++) {
for (int j = 0; j < F - 1; j++) {
window_buff[i][j] = window_buff[i][j + 1];
window_buff[i][F-1] = line_buff[i][next_x];
}
}
for (int i = 0; i < F-1; i++) {
line_buff[i][next_x] = line_buff[i + 1][next_x];
line_buff[F-1][next_x] = input[y + F][next_x];
}
HLS优化指令加速
本文中主要用到的HLS的优化指令主要包括以下三个方面:(详细过程可参考Xilinx官方文档UG902)
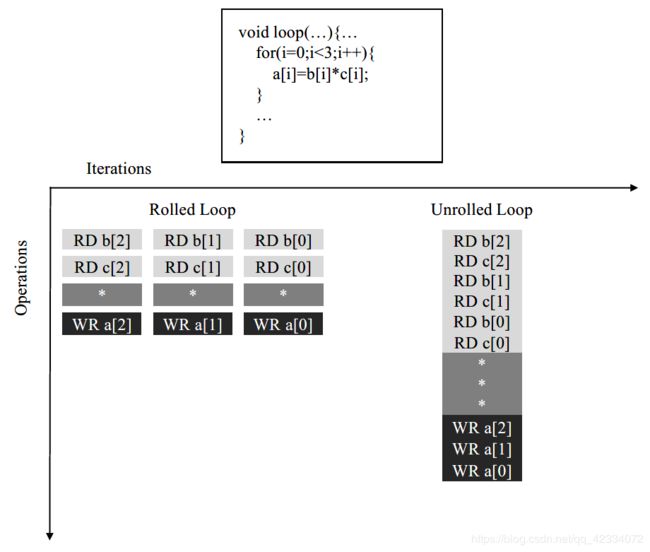
- 循环展开
循环展开是指将一个循环函数分为多个独立操作,对应的优化指令为#pragma HLS UNROLL。一般来说,对内层循环采用循环展开优化较合适,若对外层循环进行循环展开的话,会显著提高资源的使用率。
- 流水优化
在HLS 中,循环结构默认是折叠的,即只使用一组相同的硬件资源进行计算。流水线操作可以改善启动间隔与时延,对应的优化指令为#pragma HLS PIPELINE。

上图所示的函数,每三个时钟周期读取一个输入,两个时钟周期后输出一个值。使用Pipeline 优化指令后,每个时钟周期都可以读取一个新的输入,但输出的延迟不变。 - 数组分割
在进行上述优化后仍存在部分问题—读写操作的瓶颈问题。之前所示的循环展开中,对每个数组而言,每个时钟周期需要执行3个读操作或3个写操作,但是一个BRAM 最多只有两个端口,即一个时钟周期内最多执行两个读或写操作。

数组分割是通过将一个块RAM 资源分割成多个较小的阵列,从而提高带宽,有效增加端口的数量,提高读/写密集型算法的吞吐量。

改进后的Resource Viewer如下,此时不存在读写瓶颈。

实验结果
硬件系统模块的Block Design:

Jupyter Notebook结果:
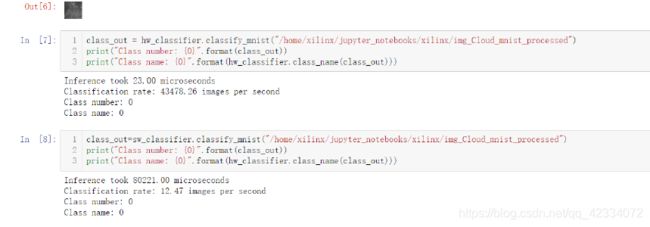
PYNQ-Z2板硬件加速效果:
| 硬件平台 | 图像数 | 时间/ms |
|---|---|---|
| CPU | 100 | 8032.8 |
| FPGA | 100 | 2.2 |
小结
论文前期用了一段时间学习HDL,用Verilog语言搭建了一些小模块熟悉硬件搭建流程,熟悉PYNQ-Z2开发板的开发流程。后来参考BNN-PYNQ在PYNQ-Z2板上跑通了BNN的例程,参考HLS-BNN学习BNN各模块在HLS的搭建及加速过程,实现BNN各模块的加速。
同时,毕设选择硬件开发时,可参考的中文资料较少,靠谱的英文文献有UG871(官方提供的HLS例程,建议跟着步骤都做一遍)以及UG902(当工具书查询)
论文中提及的工作占时不是很多 ,主要时间都在熟悉HDL、HLS开发工具以及PYNQ-Z2的开发流程,期间也遇到了很多问题,比如如何定义接口类型、如何调用板子以及如何在Jupyter Notebook进行数据格式转换等。
完成大部分毕设工作已是立夏,回顾大学四年,我努力着,付出着。
在此十分感谢女友,同我交流感受,为我加油打气;
非常感谢我的家人,替我烧水煮饭,唤我添衣保暖;
也很感谢大学挚友,与我交流思路,携我共同进步。
参考资料
PYNQ-Z2板卡简介与资源整理
Xilinx/BNN-PYNQ
板卡镜像下载地址
PYNQ官方Getting Started
PYNQ官方例程—熟悉PYNQ的开发流程
PYNQ入门中文资料
HLS生成IP进行硬件加速
FPGA并行编程
BitCount函数解释
BNN-PYNQ安装
模仿mnist制作数据集
FINN_Documentation
吴恩达深度学习课程第四课 — 卷积神经网络
HLS入门视频
正点原子ZYNQ系列