hadoop学习笔记3:分布式搭建及测试
hadoop学习笔记3:集群/分布式搭建及测试
- hadoop学习笔记3集群分布式搭建及测试
- 节点网络配置
- ssh无密码登陆节点
- Hadoop分布式配置
- hadoop分布式实例测试
记录一下hadoop集群搭建,使用3个虚拟机做为节点来搭建集群环境,并进行测试。
环境:
虚拟机ubuntun16.0.4,
jdk1.8.0_111,
hadoop-2.7.3, 下载地址见:
http://blog.csdn.net/yhhyhhyhhyhh/article/details/53945810
准备:
- 在3个虚拟机或者3台机器上安装java环境、安装ssh server、安装hadoop(也有其他方法)。可参见:Hadoop学习笔记1:伪分布式环境搭建
与hadoop伪分布式环境搭建不同的是:
- master节点能无密码ssh登录其他slave节点
- 需要选择1个虚拟机作为master节点,在其上进行hadoop集群配置,然后将master节点上的整个hadoop目录复制到其他slave节点。
1.节点网络配置
三个虚拟机如下:
| ip | 命名 |
|---|---|
| 虚拟机1(做为主节点) | 192.168.0.106 |
| 虚拟机2 | 192.168.0.107 |
| 虚拟机3 | 192.168.0.109 |
1)修改用户名和ip映射
虚拟机设置桥接模式,如果节点的系统是在虚拟机中直接复制的,要确保各个节点的 Mac 地址不同。
2)在3个虚拟机上都操作
修改节点的主机名:sudo vim /etc/hostname
虚拟机1、虚拟机2、虚拟机3hostname中的名字分别改为:master,slave1,slave2
修改所用节点的IP映射:sudo vim /etc/hosts
将3个节点hosts都修改为如下(一般该文件中只有一个 127.0.0.1,其对应名为 localhost,如果有多余的应删除):

注:修改过主机名后重启才能生效。
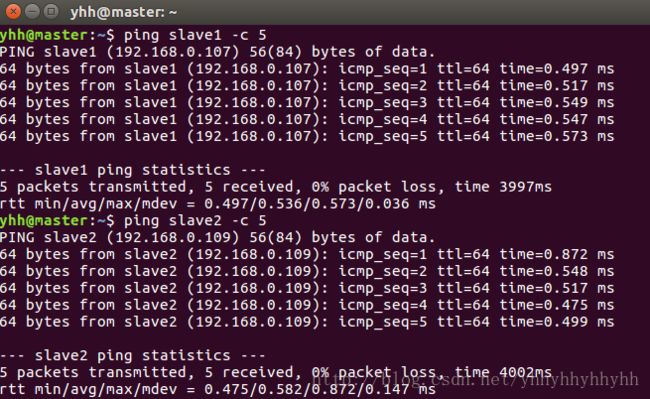
3)测试是否相互 ping 通
ping master -c 5 # 只ping 5次
ping slave1 -c 5
ping slave2 -c 5
测试如下:
2.ssh无密码登陆节点
将 master 节点的公匙scp到各个slave节点上,然后在各个节点上进行ssh配置,让以便master 节点可以无密码 ssh 登陆到各个 slave 节点上。
1)master ssh无密码登录本机
cd ~/.ssh # 如果没有该目录,先执行一次ssh localhost
rm ./id_rsa* # 删除之前生成的公匙(如果有)
ssh-keygen -t rsa # 一直按回车就可以cat ./id_rsa.pub >> ./authorized_keys #让master节点能无密码ssh登录本机2)master ssh无密码登录slave节点
- 将master节点的ssh公匙复制到slave1和slave2中并授权(复制到/home/yhh/目录下,yhh@slave1:/home/yhh/ ,yhh为slave1节点ubuntun用户名):
scp ~/.ssh/id_rsa.pub yhh@slave1:/home/yhh/
scp ~/.ssh/id_rsa.pub yhh@slave2:/home/yhh/如下图:

在slave1 、slave2节点上进行ssh配置
cat ~/id_rsa.pub >> ~/.ssh/authorized_keys
注意:在准备阶段的的ssh配置时,执行过ssh localhost在用户目录下存在 /.ssh文件夹,如果不存在可以先执行mkdir ~/.ssh(如果不存在该文件夹需先创建,若已存在则忽略)
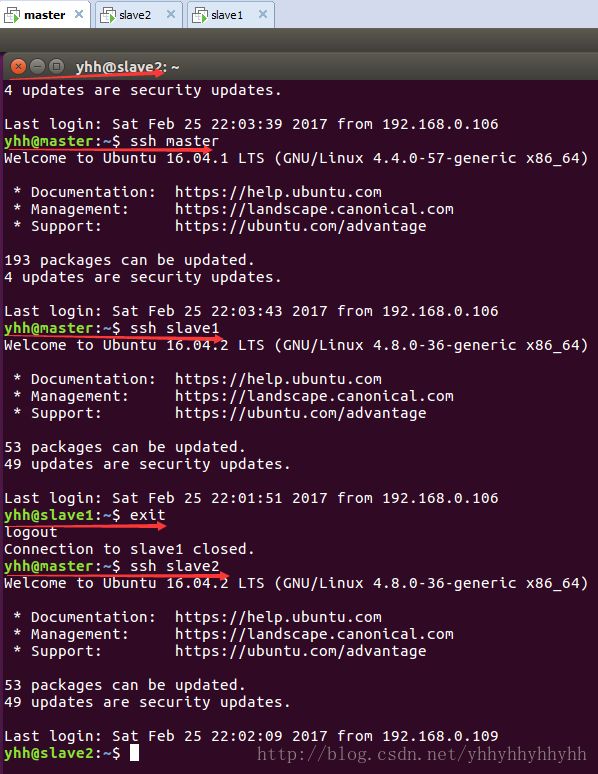
在master节点上测试:
ssh master
ssh slave1
ssh slave2
3.Hadoop分布式配置
1)master节点上hadoop分布式环境配置
集群/分布式模式需要修改 /usr/local/hadoop/etc/hadoop 中的5个配置文件,更多设置项可点击查看hadoop集群官方说明仅设置了正常启动所必须的设置项: slaves、core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml 。
命令如下图:

- slaves
修改为如下:
slave1
slave2
- core-site.xml
修改为如下:
<configuration>
<property>
<name>hadoop.tmp.dirname>
<value>file:/usr/local/hadoop/tmpvalue>
<description>Abase for other temporary directories.description>
property>
<property>
<name>fs.defaultFSname>
<value>hdfs://master:9000value>
property>
configuration>
- hdfs-site.xml
修改为如下:
<configuration>
<property>
<name>dfs.namenode.secondary.http-addressname>
<value>master:50090value>
property>
<property>
<name>dfs.replicationname>
<value>3value>
property>
<property>
<name>dfs.namenode.name.dirname>
<value>file:/usr/local/hadoop/tmp/dfs/namevalue>
property>
<property>
<name>dfs.datanode.data.dirname>
<value>file:/usr/local/hadoop/tmp/dfs/datavalue>
property>
configuration>
- mapred-site.xml
可能需要先重命名,默认文件名为 mapred-site.xml.template;然后修改为如下:
<configuration>
<property>
<name>mapreduce.framework.namename>
<value>yarnvalue>
property>
<property>
<name>mapreduce.jobhistory.addressname>
<value>master:10020value>
property>
<property>
<name>mapreduce.jobhistory.webapp.addressname>
<value>master:19888value>
property>
configuration>
- yarn-site.xml
修改为如下:
<configuration>
<property>
<name>yarn.resourcemanager.hostnamename>
<value>mastervalue>
property>
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>
configuration>2)slave节点上hadoop分布式环境配置
master节点配置好后,将 master 上的 /usr/local/hadoop 文件夹复制到各个slave节点上。
在master节点上执行:
yhh@master:/usr/local/hadoop$ cd ..
yhh@master:/usr/local$ sudo rm -r ./hadoop/tmp # 删除hadoop临时文件
yhh@master:/usr/local$ sudo rm -r ./hadoop/logs/* # 删除日志文件
yhh@master:/usr/local$ tar -zcf ~/hadoop.master.tar.gz ./hadoop # 先压缩再复制
yhh@master:/usr/local$ cd ~
yhh@master:~$ scp ./hadoop.master.tar.gz slave1:/home/yhh
yhh@master:~$ scp ./hadoop.master.tar.gz slave2:/home/yhh在 slave1 节点上执行:
yhh@slave1:~$sudo rm -r /usr/local/hadoop # 删掉旧的(如果存在)
yhh@slave1:~$sudo tar -zxf ~/hadoop.master.tar.gz -C /usr/local
yhh@slave1:~$sudo chown -R yhh /usr/local/hadoop #yhh为你的ubuntun用户名在 slave2节点上执行:
yhh@slave2:~$sudo rm -r /usr/local/hadoop # 删掉旧的(如果存在)
yhh@slave2:~$sudo tar -zxf ~/hadoop.master.tar.gz -C /usr/local
yhh@slave2:~$sudo chown -R yhh /usr/local/hadoop #yhh为你的ubuntun用户名3)hadoop分布式环境测试
首次运行hadoop需要格式化(在master节点):
yhh@master:/usr/local/hadoop$ ./bin/hdfs namenode -format
在master节点上启动hadoop。
yhh@master:/usr/local/hadoop$ ./sbin/start-dfs.sh
yhh@master:/usr/local/hadoop$ ./sbin/start-yarn.sh
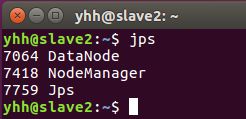
yhh@master:/usr/local/hadoop$ ./sbin/mr-jobhistory-daemon.sh start historyserver- 查看各个节点所启动的进程:
yhh@master:/usr/local/hadoop$ jps


- 通过命令查看 DataNode 是否正常启动:
yhh@master:/usr/local/hadoop$ ./bin/hdfs dfsadmin -report

- 通过 Web 页面看到查看 DataNode 和 NameNode 的状态:
http://master:50070/
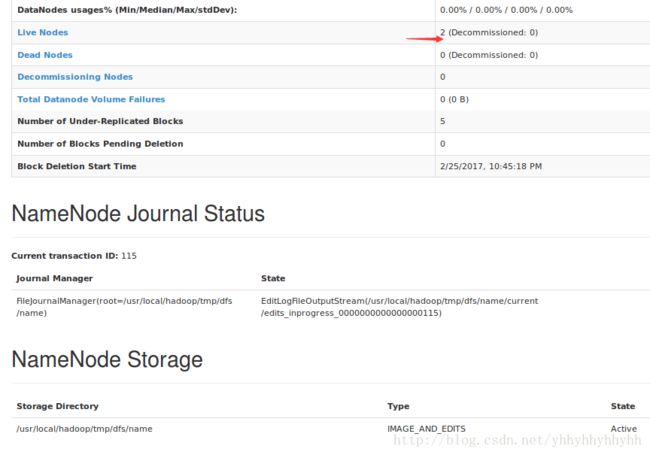
停止hadoop命令:
yhh@master:/usr/local/hadoop$ ./sbin/stop-yarn.sh
yhh@master:/usr/local/hadoop$ ./sbin/stop-dfs.sh
yhh@master:/usr/local/hadoop$ ./sbin/mr-jobhistory-daemon.sh stop historyserver4.hadoop分布式实例测试
分布式运行和伪分布式运行步骤类似。
1.数据准备
1)在hdfs下创建存储数据的文件夹(这里创建一个/input)
yhh@master:/usr/local/hadoop$./bin/hdfs dfs -mkdir /input
2)在master节点上,/usr/local下创建一个文件夹(这里随便创个文件夹叫input),在/input下建两个txt文件,输入一些测试用的单词,然后将/usr/local/input下的两个txt文件上传到hdfs下的input文件夹下,作为wordcount例子的输入。
cd /usr/local
mkdir ./input
cd ./input
sudo vim f1.txt
#f1中输入:
hello f1
hello hadoop
hello hdfs
hello mapreduce
hello yarn
sudo vim f2.txt
#f2中输入:
hello f2
hello hadoop
hello hdfs
hello mapreduce
hello yarn3)上传文件到hdfs下的input文件夹
yhh@master:/usr/local/hadoop$./bin/hdfs dfs -put /usr/local/input/f*.txt /input2.运行wordcount例子
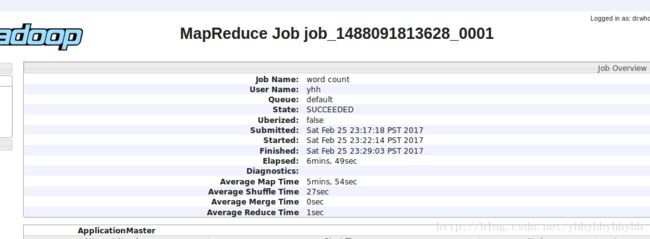
yhh@master:/usr/local/hadoop$
./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar wordcount /input/f*.txt /output查看输出命令:yhh@master:/usr/local/hadoop$./bin/hdfs dfs -cat /output/*
结果:

同样可以通过 Web 界面查看任务进度 http://master:8088/cluster,在 Web 界面点击 “Tracking UI” 下的 History ,可以看到任务的运行信息