MySQL锁问题
MySQL锁概述
相对于其他数据库而言,MySQL的锁机制比较简单,其最显著的特点是不同的存储引擎支持不同的锁机制。比如,MyISAM和MEMORY存储引擎采用的是表级锁(table-level locking);BDB存储引擎使用的是页面锁(page-level locking),但也支持表级锁;InnoDB存储引擎既支持行级锁(row-level locking),也支持表级锁,但默认情况下使用的是行级锁。
- 表级锁:开销小,加锁快;不会出现死锁;锁定粒度大,发生锁冲突的概率最高,并发度最低。
- 行级锁:开销大,加锁慢;会出现死锁;锁定粒度最小,发生锁冲突的概率最低,并发度也最高。
- 页面锁:开销和加锁时间界于表锁和行锁之间;会出现死锁;锁定粒度界于表锁和行锁之间,并发度一般。
MyISAM 表锁
MyISAM 存储引擎只支持表锁
可以通过检查 table_locks_waited 和 table_locks_immediate 状态变量来分析系统上的表锁定争夺:
mysql> show status like 'table%';
+-----------------------+-------+
| Variable_name
| Value |
+-----------------------+-------+
| Table_locks_immediate | 2979 |
| Table_locks_waited
| 0
|
+-----------------------+-------+如果 Table_locks_waited 的值比较高,则说明存在着较严重的表级锁争用情况。
MySQL 的表级锁有两种模式:表共享读锁(Table Read Lock)和表独占写锁(Table Write Lock)。锁模式的兼容性如表 20-1 所示。

可见,对 MyISAM 表的读操作,不会阻塞其他用户对同一表的读请求,但会阻塞对同一表的写请求;对 MyISAM 表的写操作,则会阻塞其他用户对同一表的读和写操作;MyISAM 表的读操作与写操作之间,以及写操作之间是串行的!
也就是说,当一个线程获得对一个表的写锁后,只有持有锁的线程可以对表进行更新操作。其他线程的读、写操作都会等待,直到锁被释放为止。
如何加表锁?
MyISAM 在执行查询语句(SELECT)前,会自动给涉及的所有表加读锁,在执行更新操作(UPDATE、DELETE、INSERT 等)前,会自动给涉及的表加写锁,这个过程并不需要用户干预。
MySQL 不支持锁升级。也就是说,在执行 LOCK TABLES 后,只能访问显式加锁的这些表,不能访问未加锁的表;同时,如果加的是读锁,那么只能执行查询操作,而不能执行更新操作。其实,在自动加锁的情况下也基本如此,MyISAM 总是一次获得 SQL 语句所需要的全部锁。这也正
是 MyISAM 表不会出现死锁(Deadlock Free)的原因。
并发插入
上文提到过 MyISAM 表的读和写是串行的,但这是就总体而言的。在一定条件下,MyISAM表也支持查询和插入操作的并发进行。
MyISAM存储引擎有一个系统变量concurrent_insert,专门用以控制其并发插入的行为,其值分别可以为0、1或2。
- 当concurrent_insert设置为0时,不允许并发插入。
- 当concurrent_insert设置为1时,如果MyISAM表中没有空洞(即表的中间没有被删除的行),MyISAM允许在一个进程读表的同时,另一个进程从表尾插入记录。这也是MySQL的默认设置。
- 当concurrent_insert设置为2时,无论MyISAM表中有没有空洞,都允许在表尾并发插入记录。
MyISAM 的锁调度
MyISAM 存储引擎的读锁和写锁是互斥的,读写操作是串行的。那么,一个进程请求某个 MyISAM 表的读锁,同时另一个进程也请求同一表的写锁,MySQL 如何处理呢?答案是写进程先获得锁。不仅如此,即使读请求先到锁等待队列,写请求后到,写锁也会插到读锁请求之前!这是因为 MySQL 认为写请求一般比读请求要重要。这也正是 MyISAM 表不太适合于有大量更新操作和查询操作应用的原因,因为,大量的更新操作会造成查询操作很难获得读锁,从而可能永远阻塞。这种情况有时可能会变得非常糟糕。
InnoDB 锁问题
InnoDB 与 MyISAM 的最大不同有两点:一是支持事务(TRANSACTION);二是采用了行级锁。行级锁与表级锁本来就有许多不同之处,另外,事务的引入也带来了一些新问题。
在了解InnoDB锁问题之前需要先了解事务(Transaction)及其 ACID 属性
- 原子性(Atomicity):事务是一个原子操作单元,其对数据的修改,要么全都执行,要么全都不执行。
- 一致性(Consistent):在事务开始和完成时,数据都必须保持一致状态。这意味着所有相关的数据规则都必须应用于事务的修改,以保持数据的完整性;事务结束时,所有的内部数据结构(如 B 树索引或双向链表)也都必须是正确的。
- 隔离性(Isolation):数据库系统提供一定的隔离机制,保证事务在不受外部并发操作影响的“独立”环境执行。这意味着事务处理过程中的中间状态对外部是不可见的,反之亦然。
- 持久性(Durable):事务完成之后,它对于数据的修改是永久性的,即使出现系统故障也能够保持。
相对于串行处理来说,并发事务处理能大大增加数据库资源的利用率,提高数据库系统的事务吞吐量。但并发事务处理也会带来一些问题:
- 更新丢失(Lost Update):当两个或多个事务选择同一行,然后基于最初选定的值更新该行时,由于每个事务都不知道其他事务的存在,就会发生丢失更新问题--最后的更新覆盖了由其他事务所做的更新。例如,两个编辑人员制作了同一文档的电子副本。每个编辑人员独立地更改其副本,然后保存更改后的副本,这样就覆盖了原始文档。最后保存其更改副本的编辑人员覆盖另一个编辑人员所做的更改。如果在一个编辑人员完成并提交事务之前,另一个编辑人员不能访问同一文件,则可避免此问题。
- 脏读(Dirty Reads):一个事务正在对一条记录做修改,在这个事务完成并提交前,这条记录的数据就处于不一致状态;这时,另一个事务也来读取同一条记录,如果不加控制,第二个事务读取了这些“脏”数据,并据此做进一步的处理,就会产生未提交的数据依赖关系。这种现象被形象地叫做"脏读"。
- 不可重复读(Non-Repeatable Reads):一个事务在读取某些数据后的某个时间,再次读取以前读过的数据,却发现其读出的数据已经发生了改变、或某些记录已经被删除了!这种现象就叫做“不可重复读”。
- 幻读(Phantom Reads):一个事务按相同的查询条件重新读取以前检索过的数据,却发现其他事务插入了满足其查询条件的新数据,这种现象就称为“幻读”。
上面讲到的并发事务处理带来的问题中,“更新丢失”通常是应该完全避免的。但防止更新丢失,并不能单靠数据库事务控制器来解决,需要应用程序对要更新的数据加必要的锁来解决,因此,防止更新丢失应该是应用的责任。“脏读”、“不可重复读”和“幻读”,其实都是数据库读一致性问题,必须由数据库提供一定的事务隔离机制来解决。数据库实现事务隔离的方式,基本上可分为以下两种。
- 一种是在读取数据前,对其加锁,阻止其他事务对数据进行修改。
- 另一种是不用加任何锁,通过一定机制生成一个数据请求时间点的一致性数据快照(Snapshot),并用这个快照来提供一定级别(语句级或事务级)的一致性读取。从用户的角度来看,好象是数据库可以提供同一数据的多个版本,因此,这种技术叫做数据多版本并发控制(MultiVersion Concurrency Control,简称 MVCC 或MCC),也经常称为多版本数据库。
数据库的事务隔离越严格,并发副作用越小,但付出的代价也就越大,因为事务隔离实质上就是使事务在一定程度上“串行化”进行,这显然与“并发”是矛盾的。

需要注意的是:各具体数据库并不一定完全实现了上述 4 个隔离级别,例如,Oracle 只提供 Read committed 和 Serializable 两个标准隔离级别,另外还提供自己定义的 Read only 隔离级别;SQL Server 除支持上述 ISO/ANSI SQL92 定义的 4 个隔离级别外,还支持一个叫做“快照”的隔离级别。
获取 InnoDB 行锁争用情况
可以通过检查 InnoDB_row_lock 状态变量来分析系统上的行锁的争夺情况:
mysql> show status like 'innodb_row_lock%';
+-------------------------------+-------+
| Variable_name
| Value |
+-------------------------------+-------+
| InnoDB_row_lock_current_waits | 0 |
| InnoDB_row_lock_time | 0 |
| InnoDB_row_lock_time_avg | 0 |
| InnoDB_row_lock_time_max | 0 |
| InnoDB_row_lock_waits | 0 |
+-------------------------------+-------+如果发现锁争用比较严重,如 InnoDB_row_lock_waits 和 InnoDB_row_lock_time_avg 的值比较高,还可以通过设置 InnoDB Monitors 来进一步观察发生锁冲突的表、数据行等,并分析锁争用的原因。
InnoDB 的行锁模式及加锁方法
InnoDB 实现了以下两种类型的行锁
- 共享锁(S):允许一个事务去读一行,阻止其他事务获得相同数据集的排他锁。
- 排他锁(X):允许获得排他锁的事务更新数据,阻止其他事务取得相同数据集的共享读锁和排他写锁。
为了允许行锁和表锁共存,实现多粒度锁机制,InnoDB 还有两种内部使用的意向锁(Intention Locks),这两种意向锁都是表锁。
- 意向共享锁(IS):事务打算给数据行加行共享锁,事务在给一个数据行加共享锁前必须先取得该表的 IS 锁。
- 意向排他锁(IX):事务打算给数据行加行排他锁,事务在给一个数据行加排他锁前必须先取得该表的 IX 锁。
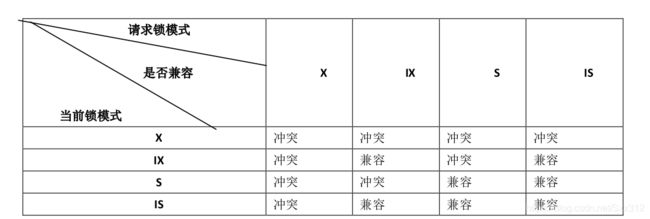
如果一个事务请求的锁模式与当前的锁兼容, InnoDB 就将请求的锁授予该事务;反之,如果两者不兼容,该事务就要等待锁释放。意向锁是 InnoDB 自动加的,不需用户干预。对于 UPDATE、 DELETE 和 INSERT 语句, InnoDB会自动给涉及数据集加排他锁(X);对于普通 SELECT 语句,InnoDB 不会加任何锁;事务可以通过以下语句显示给记录集加共享锁或排他锁。
- 共享锁(S):SELECT * FROM table_name WHERE ... LOCK IN SHARE MODE。
- 排他锁(X):SELECT * FROM table_name WHERE ... FOR UPDATE。
InnoDB 行锁实现方式
InnoDB 行锁是通过给索引上的索引项加锁来实现的,这一点 MySQL 与 Oracle 不同,后者是通过在数据块中对相应数据行加锁来实现的。InnoDB 这种行锁实现特点意味着:只有通过索引条件检索数据,InnoDB 才使用行级锁,否则,InnoDB 将使用表锁!
由于 MySQL 的行锁是针对索引加的锁,不是针对记录加的锁,所以虽然是访问不同行的记录,但是如果是使用相同的索引键,是会出现锁冲突的.
当表有多个索引的时候,不同的事务可以使用不同的索引锁定不同的行,另外,不论是使用主键索引、唯一索引或普通索引,InnoDB 都会使用行锁来对数据加锁。
即便在条件中使用了索引字段,但是否使用索引来检索数据是由 MySQL 通过判断不同执行计划的代价来决定的,如果 MySQL 认为全表扫描效率更高,比如对一些很小的表,它就不会使用索引,这种情况下 InnoDB 将使用表锁,而不是行锁。因此,在分析锁冲突时,
别忘了检查 SQL 的执行计划,以确认是否真正使用了索引。
间隙锁(Next-Key锁)
当我们用范围条件而不是相等条件检索数据,并请求共享或排他锁时,InnoDB 会给符合条件的已有数据记录的索引项加锁;对于键值在条件范围内但并不存在的记录,叫做“间隙(GAP)”,InnoDB 也会对这个“间隙”加锁,这种锁机制就是所谓的间隙锁(Next-Key 锁)。
举例来说,假如 emp 表中只有 101 条记录,其 empid 的值分别是 1,2,...,100,101,下面的 SQL:
Select * from emp where empid > 100 for update;是一个范围条件的检索,InnoDB 不仅会对符合条件的 empid 值为 101 的记录加锁,也会对empid 大于 101(这些记录并不存在)的“间隙”加锁。
InnoDB 使用间隙锁的目的,一方面是为了防止幻读,以满足相关隔离级别的要求,对于上面的例子,要是不使用间隙锁,如果其他事务插入了 empid 大于 100 的任何记录,那么本事务如果再次执行上述语句,就会发生幻读;另外一方面,是为了满足其恢复和复制的需要。
恢复和复制的需要,对 InnoDB 锁机制的影响
MySQL 通过 BINLOG 录执行成功的 INSERT、UPDATE、DELETE 等更新数据的 SQL 语句,并由此实现 MySQL 数据库的恢复和主从复制。MySQL 的恢复机制(复制其实就是在 Slave Mysql 不断做基于 BINLOG 的恢复)有以下特点。
- 一是 MySQL 的恢复是 SQL 语句级的,也就是重新执行 BINLOG 中的 SQL 语句。这与Oracle 数据库不同,Oracle 是基于数据库文件块的。
- 二是 MySQL 的 Binlog 是按照事务提交的先后顺序记录的,恢复也是按这个顺序进行的。这点也与 Oralce 不同,Oracle 是按照系统更新号(System Change Number,SCN)来恢复数据的,每个事务开始时,Oracle 都会分配一个全局唯一的 SCN,SCN 的顺序与事务开始的时间顺序是一致的。
从上面两点可知,MySQL 的恢复机制要求:在一个事务未提交前,其他并发事务不能插入满足其锁定条件的任何记录,也就是不允许出现幻读,这已经超过了 ISO/ANSISQL92“可重复读”隔离级别的要求,实际上是要求事务要串行化。这也是许多情况下,InnoDB 要用到间隙锁的原因,比如在用范围条件更新记录时,无论在 Read Commited 或是 Repeatable Read 隔离级别下,InnoDB 都要使用间隙锁,但这并不是隔离级别要求的。
InnoDB 在不同隔离级别下的一致性读及锁的差异
前面讲过,锁和多版本数据是 InnoDB 实现一致性读和 ISO/ANSI SQL92 隔离级别的手段,因此,在不同的隔离级别下,InnoDB 处理 SQL 时采用的一致性读策略和需要的锁是不同的。同时,数据恢复和复制机制的特点,也对一些 SQL 的一致性读策略和锁策略有很大影响。
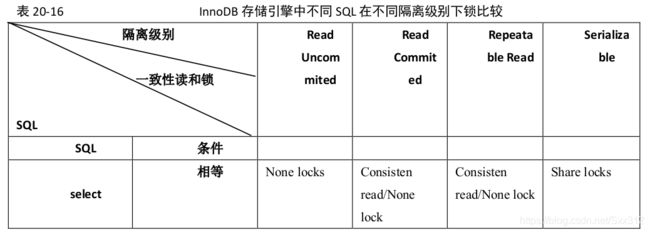

可以看出:对于许多 SQL,隔离级别越高,InnoDB 给记录集加的锁就越严格(尤其是使用范围条件的时候),产生锁冲突的可能性也就越高,从而对并发性事务处理性能的影响也就越大。因此,我们在应用中,应该尽量使用较低的隔离级别,以减少锁争用的机率。实际上,通过优化事务逻辑,大部分应用使用 Read Commited 隔离级别就足够了。对于一些确实需要更高隔离级别的事务,可以通过在程序中执行 SET SESSION TRANSACTION ISOLATIONLEVEL REPEATABLE READ 或 SET SESSION TRANSACTION ISOLATION LEVEL SERIALIZABLE 动态改变隔离级别的方式满足需求。
什么时候使用表锁
对于 InnoDB 表,在绝大部分情况下都应该使用行级锁,因为事务和行锁往往是我们之所以选择 InnoDB 表的理由。但在个别特殊事务中,也可以考虑使用表级锁。
- 第一种情况是:事务需要更新大部分或全部数据,表又比较大,如果使用默认的行锁,不仅这个事务执行效率低,而且可能造成其他事务长时间锁等待和锁冲突,这种情况下可以考虑使用表锁来提高该事务的执行速度。
- 第二种情况是:事务涉及多个表,比较复杂,很可能引起死锁,造成大量事务回滚。这种情况也可以考虑一次性锁定事务涉及的表,从而避免死锁、减少数据库因事务回滚带来的开销。
当然,应用中这两种事务不能太多,否则,就应该考虑使用 MyISAM 表了。
关于死锁
MyISAM 表锁是 deadlock free 的,这是因为 MyISAM 总是一次获得所需的全部锁,要么全部满足,要么等待,因此不会出现死锁。但在 InnoDB 中,除单个 SQL 组成的事务外,锁是逐步获得的,这就决定了在 InnoDB 中发生死锁是可能的。

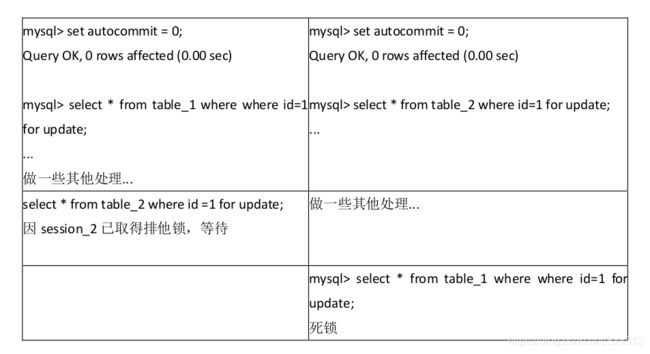
在上面的例子中,两个事务都需要获得对方持有的排他锁才能继续完成事务,这种循环锁等待就是典型的死锁。
发生死锁后,InnoDB 一般都能自动检测到,并使一个事务释放锁并回退,另一个事务获得锁,继续完成事务。但在涉及外部锁,或涉及表锁的情况下,InnoDB 并不能完全自动检测到死锁,这需要通过设置锁等待超时参数 innodb_lock_wait_timeout 来解决。需要说明的是,这个参数并不是只用来解决死锁问题,在并发访问比较高的情况下,如果大量事务因无法立即获得所需的锁而挂起,会占用大量计算机资源,造成严重性能问题,甚至拖跨数据库。我们通过设置合适的锁等待超时阈值,可以避免这种情况发生。
那么如何尽量避免死锁呢?
(1)在应用中,如果不同的程序会并发存取多个表,应尽量约定以相同的顺序来访问表,这样可以大大降低产生死锁的机会。
(2)在程序以批量方式处理数据的时候,如果事先对数据排序,保证每个线程按固定的顺序来处理记录,也可以大大降低出现死锁的可能。
(3)在事务中,如果要更新记录,应该直接申请足够级别的锁,即排他锁,而不应先申请共享锁,更新时再申请排他锁,因为当用户申请排他锁时,其他事务可能又已经获得了相同记录的共享锁,从而造成锁冲突,甚至死锁。
(4)前面讲过,在 REPEATABLE-READ 隔离级别下,如果两个线程同时对相同条件记录用 SELECT...FOR UPDATE 加排他锁,在没有符合该条件记录情况下,两个线程都会加锁成功。程序发现记录尚不存在,就试图插入一条新记录,如果两个线程都这么做,就会出现死锁。这种情况下,将隔离级别改成 READ COMMITTED,就可避免问题。
尽管通过上面介绍的设计和 SQL 优化等措施,可以大大减少死锁,但死锁很难完全避免。因此,在程序设计中总是捕获并处理死锁异常是一个很好的编程习惯。如果出现死锁,可以用 SHOW INNODB STATUS 命令来确定最后一个死锁产生的原因。返回结果中包括死锁相关事务的详细信息,如引发死锁的 SQL 语句,事务已经获得的锁,正在等待什么锁,以及被回滚的事务等。