Memory Consistency and Cache Coherence —— 内存一致性
随着CPU设计技术的提升,为了加快程序执行有了很多优化技术,1.流水线技术,经典的5级流水线(取指,译码,执行,访存,写回)。2.多发射技术,一个cpu内可以有多个同样的流水线部件,这样就可以在一个周期内发射多条指令,实现指令级并行。3.乱序执行技术,为了避免流水线中断,将不相关(数据相关,控制相关)的指令放到一块进行重新排序,这样可以使得不相关的指令并行执行,比如循环展开技术,指令动态调度技术,分支预测技术等避免数据冒险和控制冒险,使得流水线尽量满载。cpu越来越快,访存也不能拖后腿,所以有了cache技术,L1,L2,L3cache。
这些优化技术在单核cpu下对程序不会有任何影响,但是在多核cpu下编写多线程程序如果不加保护,会发生一些意想不到的结果。比如下面这段代码
public static int x,y,r1,r2;
public static int count = 0;
public static void main(String[] args) throws InterruptedException {
do{
Thread t1 = new Thread(()->{
x = 1;
r1 = y;
});
Thread t2 = new Thread(()->{
y = 1;
r2 = x;
});
t1.start();
t2.start();
t1.join();
t2.join();
count++;
x = y = 0;
}while(!(r1 == 0 && r2 == 0));
System.out.printf("r1 = %d, r2 = %d, count = %d",r1,r2,count);
}两个线程执行,如果按照程序顺序执行有以下情况,t1先执行t2后执行,t2先执行t1后执行,t1,t2同时执行,则r1,r2会出现以下组合,r1 = 0,r2 = 1;r1 = 1,r2 = 0; r1 = 1, r2 = 1。不可能出现r1 = 0, r2 = 0的情况。但是此程序会出现,是因为load比store先访问内存,也就是r1 = y在x = 1之前执行, r2 = x在 y = 1之前执行。为什么会出现这种情况呢?先了解下cpu访存会出现访存指令重排序的情况,LOAD —— LOAD重排序,STORE —— STORE重排序,LOAD —— STORE重排序,STORE —— LOAD重排序,这些都是在非数据相关下出现的重排序,也就是这四种情况都是访问的不同的地址,相同的地址不会重排序,比如load x load x不会重排序,而load y load x 可能会重排序。X86 cpu只会出现STORE —— LOAD重排序,就像上面的程序一样,在X86下就会出现r1和r2同时为0。
内存顺序一致性:
也叫强一致性模型,顺序一致性也就是访存顺序和程序执行顺序一样,不会出现内存排序,这种一致性对程序员非常友好,不需要额外的保护代码,和写单线程程序一样,MIPS R10000就实现了顺序一致性模型。刚开始思考顺序一致性模型会有一个误区,会认为顺序一致性模型不会发生指令重排,乱序执行,性能会降低,其实不是这样的。cpu乱序执行,但是通过推测来隐藏顺序一致性访存的延迟技术,反应到访存顺序上和程序顺序一致。这就是cpu设计人员利用推测处理器的延迟提交功能实现乱序执行下具有顺序一致性的特性。如果处理器对存储器请求进行重新排序后,新执行顺序的结果不同于在顺序一致性下看到的结果,处理器会撤销此次执行,撤销后的推测重启会影响一些性能,但是推测重启发生概率很低,当然这样的cpu设计复杂度也更高。所以乱序执行和内存排序没必然联系,一切都看cpu如何设计。
TSO(完全存储排序):
TSO允许STORE —— LOAD内存重排序,也就是load操作可以在store前发生,比如X86就是这种模型,x86没有使用推测技术,读写指令重排只支持STORE-LOAD重排序,但是其它非读写指令还是可以重排的。上面的程序就是这种情况,X86 cpu内置了一个fifo的write buffer,比如在store操作时会先写入write buffer如果在write buffer刷新到cache时发生了cache miss(写未命中)则会触发cache一致性协议,此时load操作不会因为store操作发生cache miss而阻塞,而是会继续执行,所以load的访存可能会在store之前。TSO模型相对SC模型设计上简单一点,对程序员也友好,因为只有store load一种情况会发生重排序,其它情况和SC模型一样,属于一种折中方案。
TSO模型的cpu在编写多线程同步代码时需要在一些地方加入内存屏障,内存屏障的作用就是防止内存排序,强制访存顺序和程序顺序一样,这样也会造成流水线阻塞,降低性能。X86提供了LFENCE, SFENCE, MFENCE指令做为内存屏障,防止指令越过内存屏障先执行。比如LFENCE会阻止LFENCE后的读指令越过LFENCE先执行,SFENCE会阻止SFENCE后的写指令越过SFENCE先执行,这里TSO模型未定义STORE操作会先执行,但是X86下一些特殊的写入指令会比其他写入指令先执行而发生重排序,比如MOVNTI, MOVNTQ,MOVNTDQ, MOVNTPS, 和 MOVNTPD指令还有字符串操作指令,会发生重排序,还有CFLUSH,CLFLUSHOPT也会发生重排序,这些重排序需要使用SFENCE指令做为屏障。MFENCE是通用屏障对读写都有用。对于上述代码可以在x = 1,LFENCE, r1 = y之间加入内存屏障,y = 1, LFENCE, r1 = y之间加入内存屏障,对应到java中就是变量加入volatile关键字。
TSO模型示意图

还有一种是弱内存一致性模型,也叫宽松一致性模型。
Relaxed Memory Consistency(宽松内存一致性模型):
弱一致性模型,对以上四种访存方式都可以重新排序,所以在编写并发程序时会增加难度,要将可能出现的一致性情况都要考虑清除,在ARM, IBM POWER, DEC ALPHA等上的系统程序要考虑的更多一些。宽松一致性模型常见的优化有:
1.非FIFO,合并写缓冲区,TSO允许使用FIFO写缓冲区,通过隐藏已提交存储的部分或全部延迟来提高性能。尽管FIFO写入缓冲器改善了性能,但是更优化的设计将使用允许写入的合并的非FIFO写入缓冲器(即,以程序顺序不连续的两个存储可以写入缓冲器中的相同条目,store store可以重排序)。但是,非FIFO合并写缓冲区违反了TSO,因为TSO要求存储按程序顺序出现。
2.支持cpu简单的推测, 在具有强一致性模型的系统中,cpu可以在准备好提交之前,推测性地乱序执行load。支持SC的MIPS R10000就是使用了这种特性提高了性能。但是支持SC的推测cpu必须包括检查推测是否正确的机制,即使误推测很少。 R10000通过将要被替换的高速缓存块的地址与cpu已经推测性地加载但尚未提交的地址列表(即核心的加载队列的内容)进行比较来检查。这种机制增加了硬件的成本和复杂性,它消耗了额外的功率,并且它可能限制指令级并行。但是在具有宽松的内存一致性模型的系统中,cpu可以乱序执行load,而无需将这些加载的地址与传入的一致性请求的地址进行比较。对于宽松一致性模型,这些load不是推测性的。
看一在宽松一致性模型个例子

data1 data2初始化为0,flag不等于set,r2和r3会全部等于0吗。按照SC和TSO,r2和r3不可能等于0的,但是在宽松一致性模型下r2和r3可能全部为0,因为宽松一致性模型支持store store重排序则S3可能比S1 S2先执行,这时data1和data2还为0,flag是set则r2和r3就全为0。这个显然不符合我们的预期,所以需要在S2和S3之间加FENCE内存屏障不让store store重新排序,如果未加B1控制依赖,则还需要在L2之前加内存屏障,不让load load重新排序。
此程序执行顺序有以下可能

FENCE后的S3不能提前到FENCE前执行,但是FENCE前的store store可以重新排序,load load也是类似。

还有一种可能就是FENCE前后的操作都未重排序。
三种内存一致性模型的比较:
TSO内存模型和SC内存模型对比:
执行:所有SC执行都是TSO执行,TSO执行有些不是SC执行,所以SC执行是TSO执行的子集。
好的内存一致性模型应该具有以下特点:
1.可编程性:一个好的模型应该(相对)容易编写多线程程序。 对于大多数用户来说,该模型应该是直观的,即使是那些没有阅读过细节的用户。 并且应该是精确的。
2.性能:良好的模型应该以合理的功率,成本等方式促进高性能实现。它应该为实现者提供广泛的选择范围。比如MIPS R10000(SC模型),x86(TSO模型),ARM(宽松一致性模型),它们的功耗和性能都需要做相应的折中。
3.可移植性:一个好的模型将被广泛采用或至少提供向后兼容性或在模型之间进行适配的能力。
4.精确度:一个好的模型应该用数学精确定义。 自然语言太含糊不清,无法让使用者了解。
可以从以上四个方面比较SC和TSO:
1.可编程性:SC是最直观的。 TSO很接近,因为它对于常见的编程习惯用语就像SC一样。 然而,其他的非SC执行需要加特殊指令。SC略胜TSO。
2.性能:对于简单的cpu,TSO可以提供比SC更好的性能,但是可以通过推测来缩小差异(CPU设计相对更复杂些),TSO优于SC。
3.可移植性:SC被广泛理解,而TSO被广泛采用。SC优于TSO
4.精确度:SC,TSO和x86-TSO都是被精确定义的。打平。
宽松一致性模型:
1.可编程性:对于那些使用SC的人来说,宽松的模型可编程性是可以接受的。深入理解宽松的模型(例如,编写编译器和运行时系统)是很困难的,所以宽松一致性模型是在可编程性是劣于SC和TSO的
2.性能:宽松的内存模型可以提供比TSO更好的性能,但是对于许多核心微架构而言,差异很小。
3.可移植性:宽松一致性模型相对于SC和TSO限制很多,移植相对困难。
4.精确度:许多宽松一致性模型是非正式定义的,精确度差于TSO和SC。
SC代表cpu:MIPS R10000
TSO代表cpu:x86
Relaxed Memory Models代表cpu:ARM, POWER, dec alpha,其中dec alpha是最弱的,支持Dependent loads reordered,也就是依赖加载也会重新排序。比如这个程序
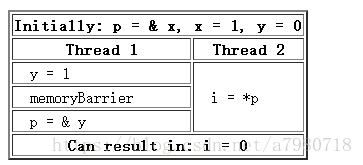
如果不加内存屏障,p可能会先取y的地址,这样可能会导致i = 0,这种情况只会在alpha下出现,其它cpu都不支持依赖加载重新排序。