十四:使用子查询
1:子查询是嵌套在其他查询中的查询。
2:需要列出订购TNT2的所有客户信息,需要下面几步:
a:从orderitems表中检索出包含物品TNT2的所有订单号;
b:根据上一步得出的订单号,从orders表中,检索出的所有客户ID;
c:根据上一步的客户ID,从customers中检索出客户信息;
它们针对的sql语句分别是:
a:select order_num from orderitems where prod_id = ‘TNT2’; 得到结果

b:select cust_id from orders where order_num in (20005, 20007); 得到结果如下:

c:select cust_name,cust_contact from customers where cust_id in (10001, 10004); 结果如下:
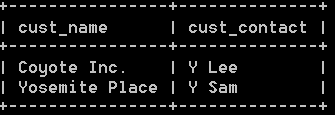
上面的三个sql语句,可以合为一句:
select cust_name, cust_contact from customers where cust_id in
(select cust_id from orders where order_num in
(select order_num from orderitems where prod_id =’TNT2’)
);
这就是子查询的例子,为了执行上面的sql语句,mysql实际上执行的就是一开始的那三条语句。子查询总是由内而外处理。
3:另外一个例子,比如要查询customers中,每个客户的订单总数,sql语句如下:
select cust_name, cust_state, (select count(*) from orders where orders.cust_id = customers.cust_id)as orders from customers order by orders; 结果如下:
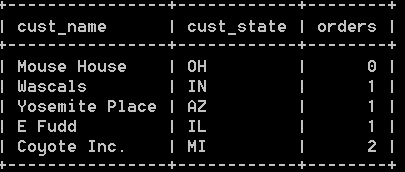
本例中的子查询,使用了完全限定名orders.cust_id和customers.cust_id。因为单单使用列名cust_id会有多义性。
4:注意,使用子查询并不是执行该查询最有效的方法。
十五:联接表
1:sql最强大的功能之一就是,能在数据检索查询的执行中联接表。联接表是利用SQL的select能执行的最重要的操作。
2:假如有这样的场景,有一个包含产品目录的表,每种类别的物品占一行,包括产品描述,价格,以及供应商的信息。
如果同一个供应商能生产多种物品,那么如何存储供应商信息?比如供应商名,地址,联系方法等。
将供应商信息和产品信息分开存储,理由如下:
a:因为同一供应商生产的每个产品的供应商信息都是相同的,对每个产品重复此信息既浪费时间,又浪费存储空间。
b:如果供应商信息改变,比如电话或地址变动,则只需改动一次即可;
c:如果有重复数据,则很难保证每次输入该数据的方式都相同。
关键是,相同数据出现多次,绝不是一个好事,这是关系数据库设计的基础。这个例子中,可建立两个表,一个存储供应商信息,一个存储产品信息。
vendors表存储供应商信息,每个供应商占一行,具有唯一标示。此标识称为主键。
products表存储产品信息,只存储供应商ID。vendors表的主键,又叫做products表的外键,它将vendors表和products表关联。
外键是某个表的一列,它包含另一个的主键值,定义了两个表的关系。
3:数据分成多个表存储有好处,但是也有代价,就是:如果数据存储在多个表中,如何用单条select语句检索出数据。这时,就要使用联接。它是一种机制,用来在一条select语句中关联表。联接在运行时关联表中正确的行。
联接不是物理实体,它在实际的数据库表中不存在,联接有mysql根据需要建立,存在于查询的执行当中。
4:select vend_name, prod_name, prod_price from vendors, products where vendors.vend_id = products.vend_id order by vend_name, prod_name; 结果如下:

5:在一条select语句中联接几个表时,相应的关系是在运行中构造的。在数据库的定义中不存在能指示mysql如何对表进行联接的东西,必须自己做这些事情。
在联接两个表时,实际上是将第一个表的每一行与第二个表的每一行配对。where子句使得只返回哪些匹配给定条件的行。如果没有where子句,则第一个表中的每行将与第二个表中的每行配对。返回的行数将是第一个表的行数乘以第二个表中的行数。
所以,应该保证所有联接都有where子句。
6:目前为止使用的联接称为等值联接,它基于两个表的相等测试,也称为内部联接。也可以使用另外一种语法:
select vend_name, prod_name, prod_price from vendors INNER JOIN products on vendors.vend_id = products.vend_id;
ANSI SQL规范首选inner join语法。
7:一条select语句中,可以联接的表的数目没有限制,比如:
select prod_name, vend_name, prod_price, quantity from orderitems, products, vendors where
products.vend_id= vendors.vend_id and orderitems.prod_id = products.prod_id and order_num =20005; 结果如下, 它列出了订单为20005的物品信息:
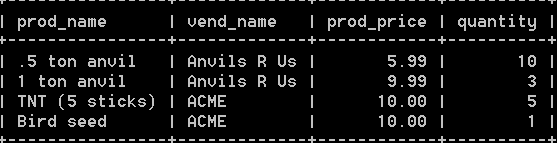
8:注意,运行时进行关联多个表,是非常耗费资源的。
9:上一章的例子中,返回订购TNT2产品的客户信息,可以用联接处理:
select cust_name, cust_contact from customers, orders, orderitems where
customers.cust_id= orders.cust_id and
orders.order_num= orderitems.order_num and
orderitems.prod_id= ‘TNT2’; 结果如下:
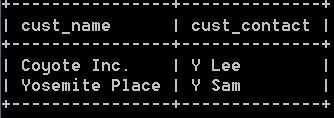
十六:创建高级联接
1:sql允许给表起别名,这样可以:缩短SQL语句;允许在单条select语句中多次使用相同的表。比如:
select cust_name, cust_contact from customers as c, orders as o, orderitems as oi
where c.cust_id = o.cust_id and
oi.order_num = o.order_num and
andoi.prod_id = ‘TNT2’;
表别名不仅可用于where子句,还可以用于select列表,order by子句等。
2:自联结的例子:比如在products表中,查找生产‘DTNTR‘的生产商,生产的其他产品,可使用下面的子查询语句:
select prod_id, prod_name from products where
vend_id = (select vend_id from products where prod_id = ‘DTNTR’);
上面的例子,也可以使用自联结,比如:
select p1.prod_id, p1.prod_name from products as p1, products as p2
where p1.vend_id = p2.vend_id and p2.prod_id = ‘DTNTR’;
这个例子必须使用表别名。可以想象成两个完全相同的表进行联接的情况。自联结的方式应该会比使用子查询更快一些。
3:外部联接
联接是将一个表中的行与另一个表中的行相关联,将满足条件的行返回。但有时会需要包含没有关联行的那些行。比如对每个客户下了多少订单进行计数,包括未下订单的客户。这就是外联结。
比如,检索客户及其订单,使用内联接是:
select customers.cust_id, orders.order_num from customers inner join orders on
customers.cust_id= orders.cust_id; 得到结果如下:
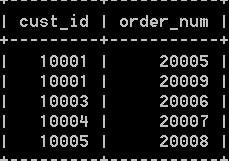
使用外联结:
select customers.cust_id, orders.order_num from customers left outer join orders on
customers.cust_id = order.cust_id; 得到结果如下:

可以明显的看出外联结和内联接的不同。使用outer join来指明外联结,外联结还必须指明right或left,指明需要包含所有行的表。left指明outer join左边的表,right指明outer join右边的表。使用right的例子是:
select customers.cust_id, orders.order_num from customers right outer join orders on
orders.cust_id = customers.cust_id;
4:如果要检索所有客户以及每个客户所下的订单数,可以如下:
select customers.cust_name, customers.cust_id, count(orders.order_num) as num_ord
from customers inner join orders on customers.cust_id = orders.cust_id
group by customers.cust_id; 结果如下:
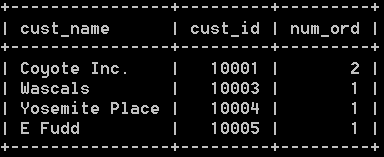
使用外联结的例子如下:
select customers.cust_name, customers.cust_id, count(orders.order_num) as num_ord
from customers left outer join orders on customers.cust_id = orders.cust_id
group by customers.cust_id; 结果如下:

十七:组合查询
1:mysql允许执行多个查询,并将结果作为单个查询结果集返回。这些组合查询称为union或组合查询。
2:使用union操作符来组合数条sql查询,比如需要找出价格小于等于5的所有物品的一个列表,而且还需包括供应商1001和1002生产的所有物品,可以使用如下的sql语句:
select vend_id, prod_id, prod_price from products where prod_price <= 5 union
select vend_id, prod_id, prod_price from products where vend_id in (1001, 1002); 结果如下:
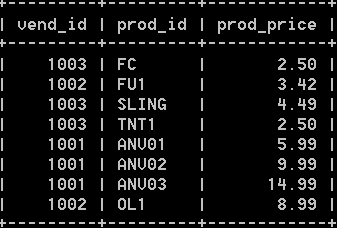
上面使用union的sql语句,也可以使用多条where子句完成:
select vend_id, prod_id, prod_price from products where prod_price <= 5 or vend_idin (1001, 1002).
3:union的每个查询必须包含相同的列、表达式或聚集函数。
4:union从查询结果集中自动去除了重复的行,如果需要显示重复的行,可以使用union all,比如:
select vend_id, prod_id, prod_price from products where prod_price <= 5 union all
select vend_id, prod_id, prod_price from products where vend_id in (1001, 1002); 结果如下:
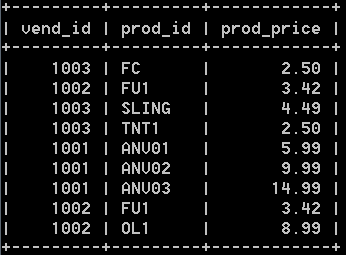
5:再用union组合查询时,只能使用一条order by子句,它必须出现在最后一条select语句之后。它会排序所有select语句返回的所有结果。比如:
select vend_id, prod_id, prod_price from products where prod_price <= 5 union
select vend_id, prod_id, prod_price from products where vend_id in (1001, 1002)
order by vend_id, prod_price; 结果如下:
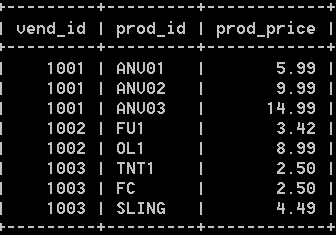
十八:全文本搜索
1:mysql支持几种基本的数据库引擎,并非所有的引擎支持全文本搜索,比如引擎myisam和innodb,只有myisam引擎支持全文本搜索。全文本搜索比like 和正则表达式具有更强的控制能力。
2:为了进行全文本搜索,必须索引被搜索的列,而且要随着数据的改变不断的更新索引。在对表进行适当的设计后,mysql会自动进行所有的索引和重新索引。
3:一般在创建表时启用全文本搜索。create table语句接受fulltext子句,他给出被索引列的一个逗号分隔的列表。比如:
create table productnotes
(
note_id int NOT NULL AUTO INCREMENT,
prod_id char(10) NOT NULL,
note_date datetime NOT NULL,
note_text text NULL,
primary key(note_id),
fulltext(note_text)
)
为了进行全文本搜索,mysql根据子句fulltext(note_text)的指示,对它进行索引。这里fulltext索引单个列,如果需要也可以指定多个列。
定义之后,mysql自动维护该索引。在增加、更新和删除行时,索引随之自动更新。
4:在索引之后,使用两个函数match和against进行全文本搜索,其中match指定被搜索的列,against指定要使用的搜索表达式。 比如:
select note_text from productnotes where match(note_text) against(‘rabbit’);

match(note_text)指定mysql针对指定的列进行搜索, against(‘rabbit’)指定词rabbit作为搜索文本。传递给match的值必须与fulltext定义中的相同。如果指定多个列,则必须列出它们,而且次序必须正确。
5:全文本搜索的时候,返回的顺序是按照匹配的良好程度进行排序的数据。尽管两个行都包含rabbit,但是包含词rabbit作为第3个词的行要比作为第20个词的行高。全文本搜索的一个重要部分就是对结果配需,具有较高等级的行先返回。比如:
select note_text match(note_text) against(‘rabbit’) as rank from productnotes; 其中,每个行的rank值如下:
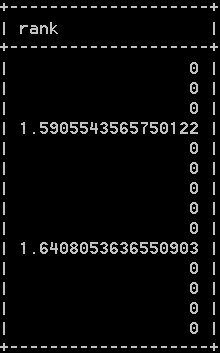
rank列包含全文本搜索计算出的等级值。不包含rabbit行等级为0,确实包含rabbit的两个行每行都有一个等级值。
6:查询扩展用来设法放宽所返回的全文本搜索结果的范围,比如想找出包含anvils的行,还想找出与anvils有关的所有其他行,即使它们不包含anvils。在使用查询扩展时,mysql对数据和索引进行两遍扫描来完成搜索:
a:进行一个基本的全文本搜索,搜索出匹配的所有行;
b:mysql检查这些匹配行并选择所有有用的词;
c:mysql再次进行全文本搜索,这次不仅使用原来的条件,而且还使用所有有用的词。
比如:select note_text from productnotes where match(note_text) against(‘anvils’ with query expansion); 返回结果如下:
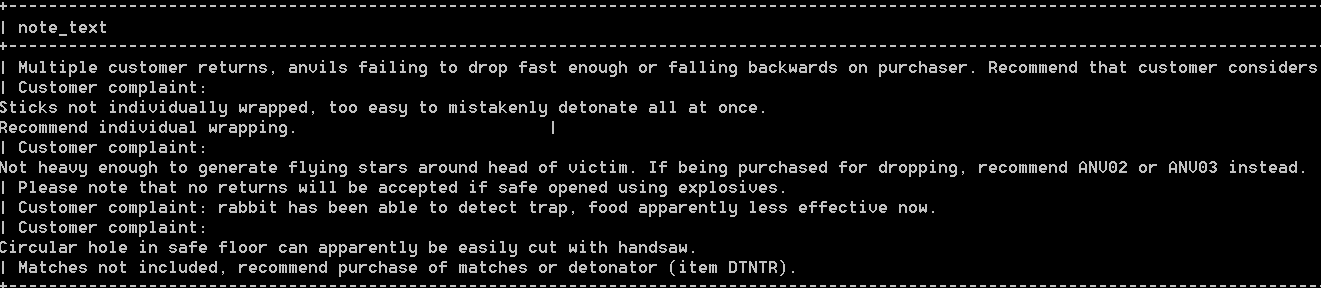
可见,不仅包含anvils的第一行返回了,还返回了与anvils无关的行。
7:mysql支持全文本搜索的另一种形式:布尔方式。布尔方式可以提供:要匹配的词;要排斥的词;排列提示;表达式分组;另外一些内容。
即使没有定义fulltext索引,也可以使用布尔方式,但是比较慢。
8:比如为了匹配包含heavy但不包含任意以rope开始的词的行,可以:
select note_text from productnotes where match(note_text) against(‘heavy –rope*’ inboolean mode);其他布尔方式,查阅其他资料,不再赘述。
if(btnReadmore.length>0){
var winH = ("#btn-readmore"); if(btnReadmore.length>0){ var winH = (window).height(); var articleBox = ("div.article_content");
var artH = articleBox.height();
if(artH > winH*2){
articleBox.css({
'height':winH*2+'px',
'overflow':'hidden'
})
btnReadmore.click(function(){
articleBox.removeAttr("style"); ("div.article_content"); var artH = articleBox.height(); if(artH > winH*2){ articleBox.css({ 'height':winH*2+'px', 'overflow':'hidden' }) btnReadmore.click(function(){ articleBox.removeAttr("style"); (this).parent().remove(); }) }else{ btnReadmore.parent().remove(); } } })()

