目标检测系列:R-FCN、Mask RCNN、Cascade RCNN
- R-FCN
- Mask RCNN
- Cascade RCNN
R-FCN
动机
Faster RCNN中加入了RPN,但网络中仍然可以分为两部分,一部分是RPN与检测网络部分共享特征的卷积层,还有一部分就是RPN迷你网络以及检测网络部分分别连接分类和回归分支的全连接层,这些隐藏层是不共享参数的,而且全连接层的参数量非常大,因此会影响计算量,造成检测速度不够快。
卷积网络部分之前的AlexNet以及VGG网络都是由多个卷积层加上全连接层组成的,而后来的GoogleNet和ResNet则都用卷积层代替全连接层,因此是全卷积网络,也取得了更好的分类效果,因此想到在检测网络结构中构建一个共享计算的全卷积子网络。
目标检测里存在着分类平移不变性以及检测时平移转变性的矛盾。平移不变性指的是对于图中的目标,比如一只猫无论目标如何移动,对于它的类别仍然是猫,也就是不必在意目标的位置。而平移转变性是指检测时对于目标所在的区域位置希望能够准确定位。而目标检测使用的模型大多基于ImageNet上的模型微调得到的,由于主要基于分类任务,会比较偏向平移不变性,所以提出一种位置信息比较敏感的投票层。
主要创新点
Score Map
为了比较好的表明位置信息,把每个ROI 矩形区域通过规则的网络划分成kxk个,如果矩形的大小为wxh,那么每一个小网格的大小为w/k x h/k。
在R-FCN网络中,将最后一层卷积层构建成对于每一个类提供k^2个得分映射(score maps),
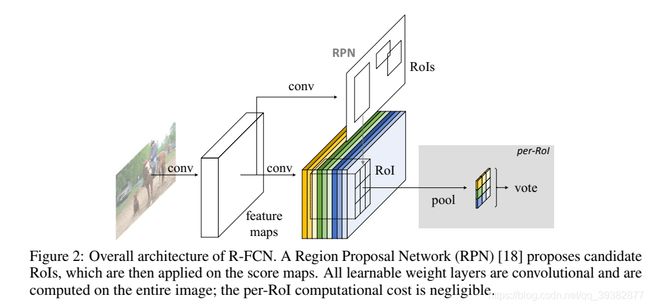
在文中k=3也就是每一个类3x3=9,分别代表九个位置区域小网格,例如图中黄色的score map代表的是左上角小网格,蓝色代表右下角等等。
对于数据集中如果存在C个类别,那么对于每一个位置的score map则存在(C+1)个通道,分别代表每一个类别的得分(1是指背景类)。
因此RPN得到的候选区域将构建成k^2x(C+1)个通道,WxH维度的特征张量。
对于每一个位置的score map进行ROI池化,
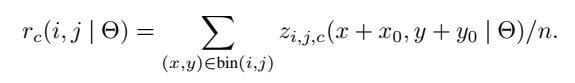
其中(I,j)表示score map对应的位置,例如(i=1,j=1)表示的是淡黄色左上角位置,r_c(I,j)表示的对于c类(I,j)位置池化的结果,z_(i,j,c)表示的c类(I,j)位置的一张得分映射图,n表示的是一个网格中的像素总数,θ表示的是网络中所有可学习参数,(x0,y0)表示的一个候选区域的左上角。
因此score map的ROI池化就是对于每一个score map求均值。得到了k^2 个(c+1)通道的特征图,将k^2个按照位置拼接成一个(C+1)个通道kxk维的特征图,(对应位置:例如淡黄色放在左上角)。
接着简单的将每一个通道的kxk个得分求和得到C+1维向量表示每一类的得分,通过softmax进行分类。
对于k^2 x(C+1)个通道卷积层还连接一个4k^2维卷积层来负责位置的回归。
算法

R-FCN算法主要如上图所示,由一个卷积网络、一个RPN、一个Score Maps层以及一个投票层组成,当然还有一个图中没有涉及的边框回归的分支。
首先将一张待检测的图像输入卷积网络ResNet-101,这里将原始网络中均值池化层以及全连接层移除,只使用卷积层来计算特征。
接着将卷积网络求得的特征图输入RPN,得到一系列的候选区域,RPN的运算过程同4.2小节。
之后构建一个k^2x(C+1)个通道的Score Maps层,通过将每一个特征图进行ROI池化得到(C+1)通道的kk维特征图。
通过对kk维求和来实现投票机制,得到(C+1)维向量,分别表示每一个类别的得分,最后通过一个softmax来实现分类。
图中未涉及的边框回归的分支是连接在Score Maps层之后的,4k^2 维的卷积层,分别表示k^2个小网格的位置回归修正信息。
优点
R-FCN的准确率以及检测的速度都有很大的提升。
准确率
由于使用了分类性能更好的ResNet101代替VGG网络、以及对于位置更加敏感的Score Maps,R-FCN的准确率也有了明显的提升,在VOC07的数据集上能达到83.6%的准确率。
运行速度
由于去除了全连接层,采用共享参数的卷积层代替,因此检测速度也有了显著的提升,仅为Faster RCNN+ResNet101结构的1/2.5。对于一张图像,检测速度可达到170ms。
Mask RCNN
动机
目标检测以及语义分割在短期内取得了飞速的发展,很大程度上依赖于Fast/Faster RCNN以及全卷积网络结构的发展。这些方法直观、便捷并且在训练和实施上的速度也十分快速。因此文章的目的就是想在这些框架的基础上发展一种新的结构能够实现实例的分割,例如行人检测。
于是基于Faster RCNN的框架上,对于每一个感兴趣区域增加一条用来预测分割的分支,这个分支主要是通过感兴趣区域之后添加一个全卷积网络来在像素级上预测一个分割的模板。
因为只增加一个小的卷积网络,所以没有增加多少额外的运算,对于检测速度的影响很小。
主要创新点
Mask RCNN主要在于在Faster RCNN的基础上增加了第三条分割的分支来实现实例的分割,因此主要创新点在于分割分支中的模板表示,代替ROI池化的ROI Align。
Mask Representation
分割的分支并不像分类和回归的分支那样,通过全连接层,将特征映射图通过全连接层输出一个短的向量,而忽略了空间的信息。
主要是利用一个全卷积小网络通过特征图在ROI区域上预测一个mxm的模板,这就使得在分割的每一层都保留了明确的目标空间信息,而不是排序成一个向量。并且全卷积的小网络的参数非常少,因此检测速度依然十分快速。
ROI Align
对于 ROI 池化中有两次量化操作,比如说对于一幅 800x800 的图像中有 655x655 区域有一条狗,但在 25x25 的特征图上,这个区域大小就为 655/32=20.78,这个时候会被量化为 20,而如果 ROI 池化 7x7 时,则20/7=2.86,又被量化成 2,而这在特征图上0.8像素的误差,放大了原图上0.8x32就是25.6个像素误差,对于分类而言可能并没有多大影响,但对于分割就产生了较大困难。
因此,为了解决这个问题,采用了一种新的ROI Align来代替ROI池化。主要的方法就是为了要避免量化的过程,所以采用的第一是x/32,来代替rounding(x/32),取消四舍五入的操作,第二就是用双线性插值法对于每一个ROI区域取四个采样点才计算输入特征的精确值,并且采用最大值或者均值来组合结果。

ROIAlign如图所示,首先在特征映射的时候就没有采用四舍五入取整,而是精确的保留了小数点,因此图中ROI区域并不是正好包含了完整的像素点,其次要得到2x2的新特征,是通过精确的4等分,划分为4个区域,在每一个小格子区域再2x2平均划分找出每一个区域的中心点,也就是图中所说的四个采样点,通过双线性插值的方法算出每一个采样点的值,最后通过均值的方法来求得每一个小格子的新的数值,从而代替了池化的过程降低了特征的维度,并且整个过程没有量化的步骤,对于分割而言提供了很大的便利。
损失函数
由于Mask RCNN主要就是增加了一条分支,因此损失函数也就是在Faster RCNN的基础上增加了一个分割的损失函数,Loss=L_cls+L_box+L_mask,其中L_cls是分类的损失函数,L_box是边框回归的损失函数,L_mask是分割的损失函数。
Mask分支采用的FCN对于每一个ROI分割的输出是Km^2,也就是K个类别的mxm的二值掩模,采用sigmoid,用平均二值交叉熵损失来定义损失函数。
算法
Mask RCNN算法流程整体与Faster RCNN相似,首先是将一整张原始图像进行全卷积网络提取特征图,接着根据RPN来对特征图进行滑动窗口,提取出一系列的候选区域ROI,接着对每一个ROI区域进行分类以及边框位置的回归,除此以外,对于ROI的特征图再增加一个小的全卷积网络,卷积网络输出K个m x m维特征,来完成分割的任务。
优缺点
Mask RCNN不仅能检测出目标的类别,还能够对目标进行分割,从而能够完成对行人的姿态的评估,能够预测目标中人的行为动作,判定例如是否具有危险性等用途。
优点
在目标检测的基础上,完成了实例分割的任务,并且检测速度仍然达到了5fps(一帧图像的检测时间为200ms)。
缺点
由于增加了一条分割的分支,虽然分支上小的全卷积网络的参数很少,但仍然增加了少量的运算量,因此对于检测时间有些许影响。
Cascade RCNN
动机
在目标检测中,IOU(intersection over union)用来描述与真实目标边框的交集,而IOU阈值是用来划分训练中正样本以及负样本的参考。IOU阈值作为目标检测中的超参数,一直以来是依赖于经验而手工划分的,这就存在着一些问题。IOU阈值过低,就会造成检测器产生很多误检区域,也成为噪声目标;而如果IOU阈值设置过高,就会造成正样本的数量过少,容易引起过拟合从而影响检测器的准确率。
另外对于检测器中边框的修正,不同的设定阈值对于不同输入IOU修正的效果也不相同,

如图所示,当设定阈值为0.5时,回归器能将输入IOU为0.5的边框修正到0.75,而阈值为0.7时只能修正到0.6,但是当输入阈值为0.95时,阈值为0.7的回归器修正仍然为0.95,而阈值为0.5的回归器反而使得输出的IOU下降到了0.92。从图中我们可以看出,在低IOU时,低阈值的修正效果更好,IOU高时,高阈值的修正效果更好。
因此想到级联几个不同阈值的回归器和检测器,先通过低阈值的分类器和回归器,这样保证正样本的数量足够,也能对低IOU的位置修正效果够好,当修正输出的更高的IOU时再通过阈值更高的分类器和回归器,这样级联几个分类器和回归器,能够提高目标检测的准确率。
主要创新点

如图所示为Cascade RCNN的级联部分网络结构,其中I表示输入的图像,conv表示的主干网络部分例如ResNet,pool表示的是ROI区域的特征提取池化,B0表示的RPN提取的区域边框信息,H表示的特征提取之后的子网络部分,每个H之后接C和B分别为对应的分类器以及回归器。而每个H部分的IOU阈值不同,逐渐增加,文中分别为0.5,0.6,0.7。
对于一张原始的输入图像,先经过一个主干网络,也就是卷积层,将卷积层提取的特征图经过RPN提取一系列的候选区域,经过阈值为0.5的检测网络H1,当经过分类器和回归器之后,输出的IOU相较于之前有所提升,将修正后的新的候选区域重采样后再送入阈值为0.6的检测网络H2,再依次类推输入检测网络H3,最后H3得到的类别以及位置就是最终整个网络的输出结果。
算法
Cascade RCNN就是在Faster RCNN的基础上,级联了几个不同IOU阈值的检测网络的基于深度学习的目标检测算法。
部分网络结构如13.2所示,算法的前半部分同Faster RCNN,是将一张原始的输入图像经过一个主干的卷积网络,之后由RPN通过映射关系,生成一系列的可能存在目标的候选窗口,这时先将这些候选区域经过阈值为0.5的检测网络(包括分类器和回归器),将回归器修正后的新的区域再送入阈值为0.6的检测网络,(分类器如果识别的结果为不存在目标则不会有修正的位置),之后再讲H2(阈值为0.6的检测子网络)输出的新的区域位置送入阈值为0.7的检测子网络,最后该子网络的输出部分即为网络最后的输出结果。
由于采用的了多阈值检测子网络的级联的结构,级联顺序按照阈值由小到大排列,阈值为0.5时,正样本数量足够,保证模型不会过拟合,保障准确率。并且阈值为0.5时对于低IOU样本位置的修正效果最为显著,而当修正后的高IOU再由更高阈值的回归器进行修正,这样能够大大提高了位置的准确性。
通过级联机构,解决了传统单个网络设置阈值时对于高阈值正样本数量不够以及低阈值对于高IOU区域修正效果降低之间的矛盾。
优缺点
优点
通过级联结构,避免的单个模块检测网络设置阈值时的矛盾,大大提高了目标检测的准确率,在COCO数据集上,相较于传统的Faster RCNN由34.9%提高到了42.8%,加入了FPN的Faster RCNN由38.8%提高到了42.8%.
缺点
多个子检测网络的级联也增加了网络的结构,使得检测速度有了一定的影响,在主干网络为VGG时,检测速度由0.075s增加到了0.115s一张,而在ResNet-101上加入FPN结构的Faster RCNN由0.115s增加到了0.14s。