22-C++基础-浮点数
浮点数
了解各种C++整型后,来看看浮点类型,它们是C++的第二组基本类型。浮点数能够表示带小数部分的数字,如MI油箱的汽油是里程数(0.56MPG),它们提供的值范围也更大,如果数字很大,无法表示为long类型,如人体的细菌数(估计超过100兆),则可以使用浮点类型来表示。
使用浮点类型可以表示诸如2.5、3.14159和122442.32这样的数字,即带小数部分的数字。计算机将这样的值分成两部分存储,一部分表示值,另一部分用于对值进行放大或缩小。下面打个比方,对于数字34.1245和34124.5,它们除了小数点的位置不同外,其他都是相同的。可以把第一个数表示为0.341245(基准值)和100(缩放因子),而将第二个数表示为0.341245(基准值相同)和10000(缩放因子更大)。缩放因子的作用是移动小数点的位置,术语浮点因此而得名。C++内部表示浮点数的方法与此相同,只不过它给予的是二进制,因此缩放因子是2的幂,不是10的幂。幸运的是,程序员不必详细了解内部表示。重要的是,浮点数能够表示小数值、非常大和非常小的值,它们的内部表示方法与整数有天壤之别。
3.3.1 书写浮点数
C++有两种书写浮点数的方式。第一种是使用常用的标准小数点表示法:
12.34
939001.32
0.00023
8.0
即使小数部分为0(如8.0),小数点也将确保该数字以浮点格式(而不是整数格式)表示。(C++标准允许实现表示不同的区域:例如,提供了使用欧洲方法的机制,即将逗号而不是句点用作小数点。然而,这些选择控制的是数字在输入和输出中的外观,而不是数字在代码中的外观。)
第二种表示浮点值的方法叫做E表示法,其外观是像这样的:3.45E6,这指的是3.45与1000000相乘的结果;E6指的是10的6次方,即1后面6个0.一次,3.45E6表示的是3450000,6被称为指数,3.45被称为尾数,下面是一些例子:
2.52e+8
8.33E-4
7E5
-18.32e13
1.69e12
5.98E24
9.11e-31
读者可能注意到了,E表示法最适合于非常大和非常小的数。
E表示法确保数字以浮点格式存储,即使没有小数点。注意,既可以使用E也可以使用e,指数可以是正数也可以是负数。然而,数字中不能有空格,因此7.2 E6是非法的。
指数为负数意味着除以10的乘方,而不是乘以10的乘方。因此,8.33E-4表示8.33/10^4,即0.000833。同样,电子质量9.11e-31kg表示0.0000000000000000000000000000000911。可以按照自己喜欢的方式表示数字(911是美国报警电话,而电话信息通过电子传输,这是巧合还是科学阴谋呢?读者可以自己作出评判)。注意,-8.33E4指的是-93300。前面的符号用于数值,而指数的符号用于缩放。
记住:d.dddE+n指的是将小数点向右移n位,而dddE-n指的是将小数点向左移n位。之所以称为“浮点”,就是因为小数点可移动。
3.3.2 浮点类型
和ANSI C一样,C++也有3种浮点类型:float、double和long double。这些类型是按它们可以表示的有效位和允许的指数最小范围来描述的。有效位是数字种有意义的位。例如,加利福尼亚的Shasta山脉的高度为14179英尺,该数字使用了5个有效位,指出了最接近的英尺数。然而,将Shasta山脉的高度写成约14000英尺而已。有效位数为2为,因为结果经过四舍五入精确的了千位。在这种情况下,其余的3位只不过是占位符而已。有效位数不依赖与小数点的位置。例如,可以将高度写成14.162千英尺。这样仍有五个有效位,因为这个值精确到了第五位。
事实上,C和C++对于有效位数的要求是,float至少32位,double至少48位,且不少于float、long double至少和double 一样多。然而,通常,float为32位,double为64位,long double为80、96或128位。另外,这3种类型的指数范围至少是-37到37。可以从头文件cfloat或float.h中找到系统的限制。(cfloat是C语言的float.h文件的C++版本。)下面是Borland C++ Builder 的float.h文件中的一些批注项;
//the following are the minimum number of significant digits
#define DBL_DIG 15 //double
#define FLT_DIG 6 //float
#define LDBL_DIG 18 //long double
//the following are the number of bits used to represent the mantissa
#define DBL_MANT_DIG 53
#define FLT_MANT_DIG 24
#define LDBL_MAXT_DIG 64
//the following are the maximum anf minimum exponent values
#define DBL_MAX_10_EXP +308
#define FLT_MAX_10_EXP +38
#define LDBL_MAX_10_EXP +4932
#define DBL_MIN_10_EXP -307
#define FLT_MIN_10_EXP -37
#define LDBL_MIN_10_EXP -4932注意:有些C++实现尚未添加头文件cfloat,有些基于ANSI C之前的编译器的C++实现没有提供头文件float.h。
//floatnum.cpp——floating-point types
#include
int main()
{
using namespace std;
cout.setf(ios_base::fixed,ios_base::floatfield);
float tub = 10.0/3.0;
double mint = 10.0/3.0;
const float million = 1.0e6;
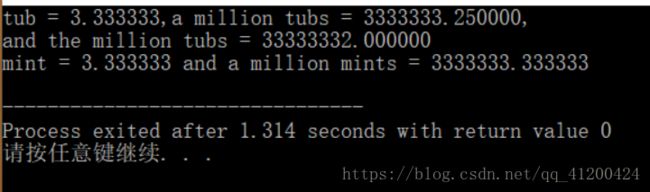
cout<<"tub = "<下面是该程序的输出:
1、程序说明
通常cout会删除结尾的零。例如,将3333333.250000显示为3333333.25。调用cout.setf()将覆盖这种行为,至少在新的实现中是这样的。这里要注意的是,为何float的精度比double低。tub和mint都被初始化为10.0/3.0——3.333333333333333……由于cout打印6位小数,因此tub和mint都是精确的。但当程序将每个数乘以一百万后,tub在第7个3之后就与正确的值有了误差。tub在7位有效位上还是精确的(该系统确保float至少6位有效位,但是最糟糕的情况)。然而,double类型的变量显示了13个3,因此它至少有13位是精确的。由于系统确保15位有效位,因此这就没有什么好奇怪的了。另外,将tub乘以一百万,在乘以10后,得到的结果不正确,这再一次指出了float的精度限制。
cout所属的ostream类有一个类成员函数,能够精确地控制输出的格式——字段宽度、小数位数、采用小数格式还是E格式等。第十七章将介绍这些选项,为简单起见,本书的例子通常只使用<<运算符。
读取包含文件
C++源文件开头的包含编译指令总是有一种魔咒的力量,新手C++程序员通过阅读和体验来了解哪个头文件添加哪些功能,再一一包含它们,以便程序能够运行。不要将包含文件作为神秘的知识而依赖;可以随便打开、阅读它们。它们都是文本文件,因此可以很轻松地阅读它们。被包含在程序中的所有文件都存在于计算机中,或位于计算机可以使用的地方。找到那些要使用的包含文件,看看它们包含的内容。您将很快的知道,所使用的源文件和头文件都是知识和信息的很好来源——在有些情况下,它们都是最好的文档。当使用更复杂的包含文件,并开始在应用程序中使用其他非标准库时,这种习惯将非常有帮助。
3.3.3 浮点常量
在程序中书写浮点常量的时候,程序将把它存储为哪种浮点类型呢?在默认情况下,像8.24和8.4E8这样的浮点常量都术语double类型。如果希望常量为float类型,请使用f或F后缀。对于long double类型,可使用l或L后缀(由于l看起来很像数字1,因此L是更好的选择),下面是一些示例:
1.234f
2.45E20F
2.345324E28
2.2L
3.3.2 浮点数的优缺点
与整数相比,浮点数有两大优点,首先,它们可以表示整数之间的值。其次,由于有缩放因子,它们可以表示的范围大得多,另一方面,浮点运算的速度通常比整数运算慢,且精度将降低。程序3.9说明了最后一点。
程序 3.9 fitadd.cpp
//fitadd.cpp——precision problems with float
#include
int main()
{
using namespace std;
float a= 2.34E+22f;
float b= a+1.0f;
cout<<"a= "<注意:有些基于ANSIC之前的编译器的老式C++实现不支持浮点常量后缀f。如果出现这样的问题,可以用2.34E+22替代2.34E+22f,用(float)1.0代替1.0f.
该程序将数字加1,然后减去原来的数字。结果应该为1。下面是运行结果。

如果显示为0,那么问题在于,2.34E+22是一个小数点左边有23位的数字,加上1,就是在第23位加1。但float类型只能表示数字中的前6位或前7位,因此修改第23位对这个值不会有任何影响。
将类型分类
C++对基本类型进行分类,形成了若干个族。类型signed char、short、int和long统称为符号整型;它们的无符号版本通常位无符号整型;C++11新增了long long 、bool、char、wchar_t、符号整数和无符号整型称为整型;C++11新增了char16_t和char32_t。float、double、和long double统称位浮点型。整数和浮点型统称算术类型