【论文笔记】:Cascade R-CNN: Delving into High Quality Object Detection
&Title:
- Cascade R-CNN: Delving into High Quality Object Detection
- Cascade R-CNN: Delving into High Quality Object Detection(中文翻译)
&Summary
本篇文章主要解决了在目标检测中,检测框不是特别准,容易出现噪声干扰的问题,即close false positive,为什么会有这个问题呢?
作者实验发现,因为在基于anchor的检测方法中,我们一般会设置训练的正负样本(用于训练分类以及对正样本进行坐标回归),选取正负样本的方式主要利用候选框与ground truth的IOU占比,常用的比例是50%,即IOU>0.5的作为正样本,IOU<0.3作为负样本等,但是这样就带来了一个问题,阈值取0.5是最好的吗?
作者通过实验发现,
- 设置不同阈值,阈值越高,其网络对准确度较高的候选框的作用效果越好。
- 不论阈值设置多少,训练后的网络对输入的proposal都有一定的优化作用。
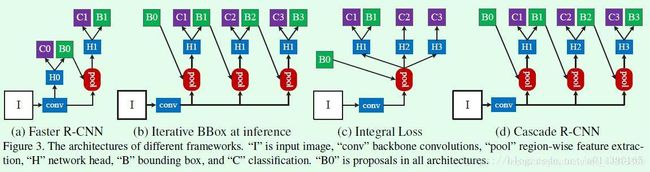
基于这两点,作者设计了Cascade R-CNN网络,如下面图Figure3(d)所示,即通过级联的R-CNN网络,每个级联的R-CNN设置不同的IOU阈值,这样每个网络输出的准确度提升一点,用作下一个更高精度的网络的输入,逐步将网络输出的准确度进一步提高。
一句话总结就是:Cascade R-CNN就是使用不同的IOU阈值,训练了多个级联的检测器。
&Research Objective
本文主要针对的是检测问题中的IoU阈值选取问题
&Problem Statement
目标检测其实主要干的就是两件事,一是对目标分类,二是标出目标位置。所以,为了实现这两个目标,在训练的时候,我们一般会首先提取候选proposal,然后对proposal进行分类,并且将proposal回归到与其对应的groud truth上面,但是这就带来了一个问题,因为我们做分类需要确定样本的标签,那么我们给什么样的proposal打一个标签呢?最常用的做法是利用IOU(proposal与ground truth的交并比),可是IOU阈值设置成多少可以作为我打标签的边界呢?常用的阈值是0.5,可是0.5是最好的吗?
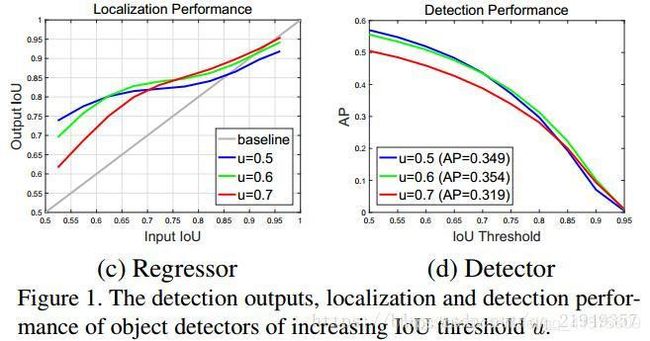
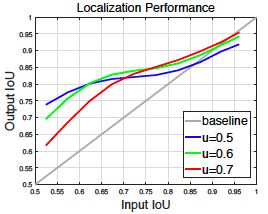
作者通过实验证实了不同IOU对于网络的影响,如图Figure 1
©所示。图c中3条线分别代表3个IOU的阈值,横轴是输入的IOU的proposal,纵轴是对应的proposal经过网络输出后的坐标框与ground
truth的IOU,我们观察可以发现,3条线,都在灰色对角线之上,说明3条线都有一定的优化效果,并且,3条线无一例外在自己设定的阈值周围优化较明显。
那么问题来了,我们是否可以将阈值提高,以达到优化输出精度的效果呢?
作者又做了不同阈值下网络精度的实验,结果如图figure1(d)所示,可以发现,对于阈值为0.5以及0.6的时候,网络精度差距不大,甚至提升了一点,但是将精度提升到0.7后,网络的精度就急速下降了,(COCO数据集上:AP:0.354->0.319),这个实验说明了,仅仅提高IoU的阈值是不行的,因为提高阈值以后,我们会发现,实际上网络的精度(AP)反而降低了。
为什么会下降呢?
由于提高了阈值,导致正样本的数量呈指数减低,导致了训练的过拟合。
在inference阶段,输入的IOU与训练的IOU不匹配也会导致精度的下降。所以才会出现Figure1(d)中,u=0.7的曲线在IOU=0.5左右的时候,差距那么大。
实验证明了不能使用高的阈值来进行训练,但是实验也呈现出了另一个事实,那便是:回归器的输出IOU一般会好于输入的IOU,图figure1(c)所示。并且随着u的增大,对于在其阈值之上的proposal的优化效果还是有提升的。
那既然这样,我们是否可以采用级联的方式逐步提升呢?即首先利用u=0.5的网络,将输入的proposal提升一些,假如提升到了0.6,然后在用u=0.6的网络进一步提升,加入提升到0.7,然后再用u=0.7的网络再提升,这样岂不是精度越来越高了?
于是乎,作者设计了Cascade R-CNN网络。
&Method(s)
作者设计了Cascade R-CNN网络。
对IoU阈值设置的探索
早前VOC都是以 mAP50 作为唯一的性能衡量标准,为了overfit该数据集,算法的IoU阈值在train阶段和inference阶段常被简单地设定为 0.5,而这会导致train阶段对bbox的质量要求过低。
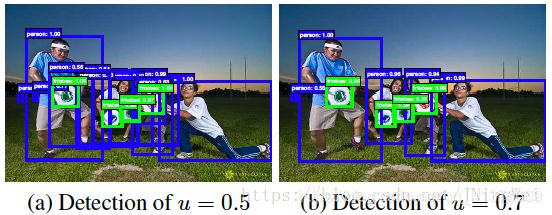
inference阶段,如果IoU阈值设为0.5,最终输出可能如下的左图所示,带有不少错分为object的bbox;如果我们把IoU阈值调高到0.7,如下右图所示,就可以把一堆IoU介于0.5~0.7之间的bbox给过滤掉:
那我们直接在train阶段就把IoU阈值改为0.7,test阶段依然为0.5,不就好了吗?
不行。
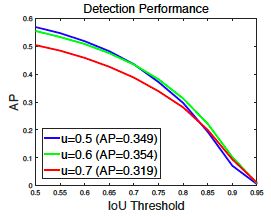
如上图,IoU=0.7训练出来的detector红线,在IoU=0.5的输入上定位效果甚至不如IoU=0.5训练出来的detector蓝线:
原因有二:
- train阶段IoU设为0.7会导致positive bbox的数量骤降,导致最终训出的模型overfit。
- inference阶段,RPN丢给roi-wise subnet的大多是low-quality proposal。单个regressor再强也只能稍微regress一点点location,那么最终的output还是得GG。
那我们train阶段为0.5,只在test阶段把IoU阈值改为0.7呢?
不行。
原因:
- train阶段 和 inference阶段 的 IoU阈值 设置得不一样,反而会影响性能。
那就同时把train阶段和test阶段都改为0.7呢?
还是不行。
原因:
- 自从更大更全的COCO数据集提出来后,评价标准变得“多IoU阈值化”了。在原先的mAP50基础上,又增加了mAP75等等一系列指标。也就是说,不管你怎么改,都会导致某些IoU阈值标准是你在train的阶段无法顾及到的。
对regressor数量的探索
作者发现,假设待输入regressor的bbox为Input,回归后的输出bbox为Output,则Output的IoU质量普遍优于Input:
等于证明了:
经过location regression的bbox明显更high-quality。
故而,多次叠加roi-wise subnet,就等于多regress几次bbox,自然可以获得更high-quality的output bbox,从而刷高COCO测评性能。
那么直接简单地在roi-wise subnet后面再叠加roi-wise subnet可以么?
不行。
原因:
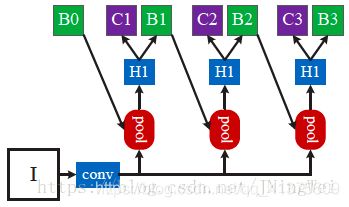
- 因为如果这么做的话,对bbox的回归公式就变成了如下所示:
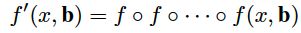
- 此时对应的网络结构就会不能很好地挖掘多级roi-wise subnet的作用:
作者的Idea,是设计cascade的bbox cls/reg机制:

总共有三个roi-wise subnet相cascade (级联) ,每个roi-wise subnet采用不同的IoU阈值。依次为0.5、0.6、0.7。
对应的网络结构如下:
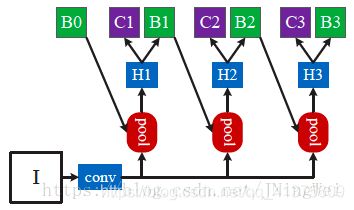
该设计有如下四大优势:
- 实现起来简单;
- 可以end-to-end训练;
- 适用于任何two-stage的检测算法;
- 普遍都能涨点2~4。
网络结构:
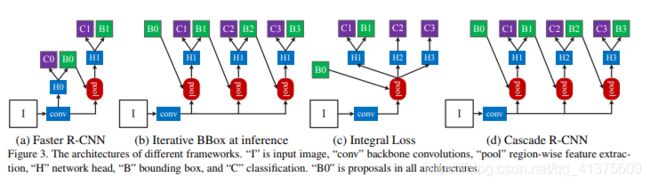
图figure 3(d)是Cascade R-CNN的网络结构对比图,Figure 3(a)是Faster R-CNN的网络结构图,其中H0代表的是RPN网络,H1代表的是Faster R-CNN进行检测与分类的head,C1代表最终的分类结果,B1代表最终的bounding box回归结果。那么Cascade R-CNN有什么不同呢?H1那一部分是一样的,但是Cascade R-CNN得到B1回归后的检测框后,将其输入到H2部分,继续回归,以此类推到H3部分,使得每次对bounding box都提高一定的精度,已达到提高检测框准确度的作用。
注:级联的方式,不再是为了找到hard negatives,而是通过调整bounding boxes,给下一阶段找到一个IoU更高的正样本来训练。SSD等利用hard negatives方法进行优化。即对负样本loss排序,取loss较大的部分。
最后总结一下,作者最终确定的结构一共是4个stages: 1个RPN+3个检测器(阈值设定分别为0.5/0.6/0.7)……其中RPN的实现想必大家都很清楚了,而后面三个检测器,则按照之前介绍的那样,每个检测器的输入都是上一个检测器进行了边框回归后的结果,实现思路应该类似于Faster RCNN等二阶段检测器的第二阶段。
&Evaluation
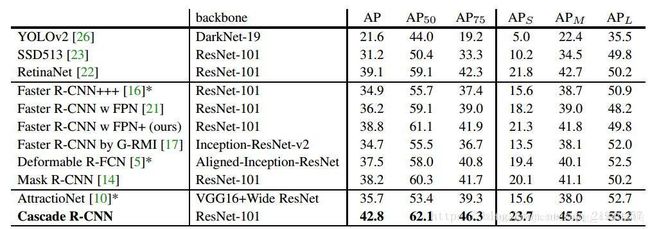
可以看出,提升还是相当好的。特别需要说明的一点是,对于目前流行的检测结构来说,特征提取是耗时最多的,因此尽管Cascade R-CNN增加了比较多的参数,但是速度的影响并没有想象中的大,具体可以参考下表:
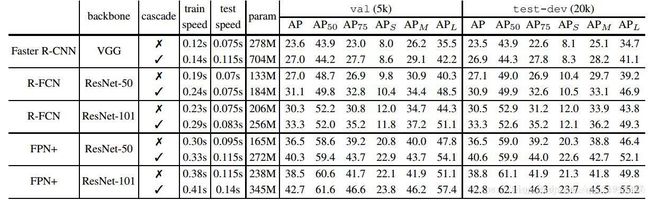
这篇文章还做了大量的对比实验,例如通过添加ground truth来提高proposal的质量从而验证mismatch问题;通过添加stages来分析适合的级联阶段数等等;包括一些和第2部分中提到的两种思路的对比等等,可直接看论文。
&Conclusion
本文提出了一种多级目标检测框架-Cascade R-CNN,用于设计高质量的目标检测器。该体系结构避免了训练中的过度拟合和推理时的质量不匹配等问题。Cascade R-CNN对具有挑战性的COCO数据集的可靠和一致的检测改进表明,为了推进目标检测,需要对各种并发因素进行建模和理解。Cascade R-CNN被证明适用于许多目标检测体系结构。
参考
- 论文阅读: Cascade R-CNN