搭建hadoop完全分布式环境详解
所需软件:VMWare11.0、linuxmint-17.1-mate-32bit.iso、jdk-7u7-linux-i586.tar.gz、hadoop-1.0.4.tar.gz(考虑到
搭建的系统稳定性,所以采用1.X系列的hadoop)
下载地址:链接: http://pan.baidu.com/s/1kTKiUk3 密码: csbg
一、安装VMWare11.0、linuxmint-17.1-mate-32,按提示安装即可。
二、在Linux下把jdk-7u7-linux-i586.tar.gz、hadoop-1.0.4.tar.gz解压到当前用户的目录下
2.1解压文件
假设已把文件拷到Linux系统的/home/wsd/software/路径下(关于如何在Linux mint和Windows共享文件,请查看安装samba服务器实现Linux mint和Windows共享文件)分别执行命令tar -zxvf software/hadoop-1.0.4.tar.gz -C .、tar -zxvf software/jdk-7u7-linux-i586.tar.gz -C .(.表示解压到当前用户目录下)
配置Java的环境变量:gedit .bashrc打开配置文件,加上以下内容(配置Java和hadoop的环境变量)
export JAVA_HOME=/home/wsd/jdk1.7.0_07
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export HADOOP_HOME=/home/wsd/hadoop-1.0.4
export PATH=${PATH}:${JAVA_HOME}/bin:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin
export HADOOP_HOME_WARN_SUPPRESS=1(要加上这一行,否则启动hadoop时会报Warning: $HADOOP_HOME is deprecated的警告)
保存退出,执行. .bashrc命令使配置信息立即生效。输入Java-version即可看到版本信息。
2.2配置主机名
创建文件目录sysconfig,mkdir /etc/sysconfig,创建文件network,mkdir /etc/sysconfig/network,修改权限
sudo chmod 777 /etc/sysconfig/network,打开network文件:gedit /etc/sysconfig/network,添加以下内容:
NETWORKING = yes
HOSTNAME = master
保存退出。
2.3配置静态IP
网络设置成NAT模式,IP地址:192.168.1.101,子网掩码:255.255.255.0,网关:192.168.1.1
2.4修改主机名和IP的映射关系
打开文件hosts:gedit /etc/hosts,添加以下内容:
::1localhost
127.0.0.1 localhost
192.168.1.101 master
192.168.1.102 slave1
192.168.1.103 slave2
保存退出。
2.5配置ssh,实现无密码登录
要先安装openssh-server:sudo apt-get install openssh-server
产生密钥对:ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
写到authorized_keys中:cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
将/home/wsd/目录赋予700权限:chmod 700 /homo/wsd/
2.6配置hadoop文件(hadoop2.x的配置文件$HADOOP_HOME/etc/hadoop)
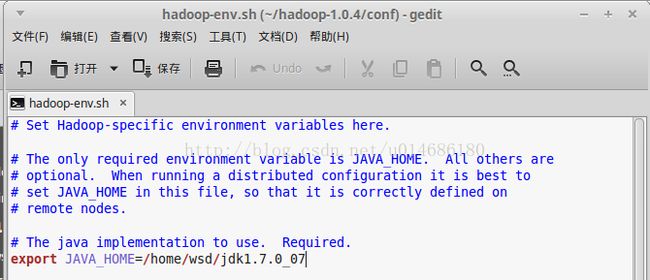
(1)打开hadoop-env.sh(/home/wsd/hadoop-1.0.4/conf/hadoop-env.sh)
修改JAVA_HOME环境变量,如下图所示
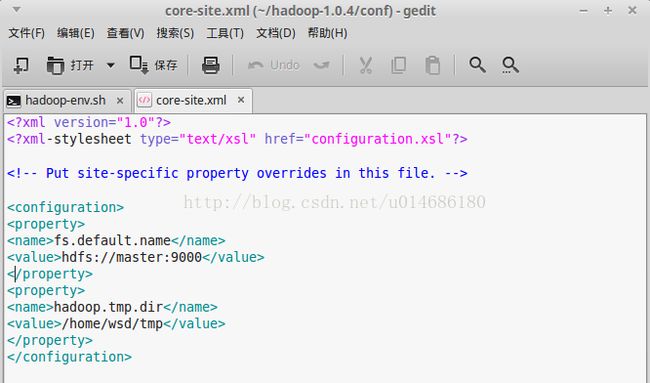
(2)打开core-site.xml(/home/wsd/hadoop-1.0.4/conf/core-site.xml),添加以下内容:
,如下图所示:
(3)打开hdfs-site.xml(/home/wsd/hadoop-1.0.4/conf/hdfs-site.xml),添加以下内容:

(4)打开mapred-site.xml(/home/wsd/hadoop-1.0.4/conf/mapred-site.xml),添加以下内容:

(4)打开master(/home/wsd/hadoop-1.0.4/conf/master),添加master,如下图所示:
(5)打开slaves(/home/wsd/hadoop-1.0.4/conf/slaves),添加以下内容:
slave1
slave2,如下图所示:

2.7将hadoop目录加入用户和组中:sudo chown -R wsd:wsd /home/wsd/hadoop-1.0.4
2.8用VMWare克隆两个系统(slave1和slave2),克隆好后分别在两台电脑修改相应的主机名和地址。
2.9格式化namenode:hadoop namenode -format
2.10启动hadoop:start-all.sh(若报错,应该是上面的某一步或几步设置错误了,可查看对应的日志文件,
分析是什么原因导致的,然后再有针对性的解决问题),jps验证启动成功,如下图:

分别在slave1和slave2上执行jps,可以看到如下图所示内容:
恭喜你,开启大数据之旅。。。