
DMOZ\xe4\xb8\xad\xe6\x96\x87\xe7\xbd\x91\xe7\xab\x99\xe5\x88\x86\xe7\xb1\xbb\xe7\x9b\xae\xe5\xbd\x95-\xe5\x85\x8d\xe8\xb4\xb9\xe6\x94\xb6\xe5\xbd\x95\xe5\x90\x84\xe7\xb1\xbb\xe4\xbc\x98\xe7\xa7\x80\xe7\xbd\x91\xe7\xab\x99\xe7\x9a\x84\xe4\xb8\xad\xe6\x96\x87\xe7\xbd\x91\xe7\xab\x99\xe7\x9b\xae\xe5\xbd\x95.
\r\n\t\t\t- \r\n\t\t\t\r\n\t\t\t\t
- \xe5\x85\x8d\xe8\xb4\xb9\xe6\xb3\xa8\xe5\x86\x8c \r\n\t\t\t\t
- \xe7\x99\xbb\xe5\xbd\x95\xe7\xae\xa1\xe7\x90\x86 \r\n\t\t\t\t
- \xe6\x8f\x90\xe4\xba\xa4\xe7\xbd\x91\xe7\xab\x99 \r\n\t\t\t\t
- \xe6\x82\xa8\xe5\xa5\xbd\xef\xbc\x8c\xe6\xac\xa2\xe8\xbf\x8e\xe6\x9d\xa5DMOZ\xe4\xb8\xad\xe6\x96\x87\xe7\xbd\x91\xe7\xab\x99\xe5\x88\x86\xe7\xb1\xbb\xe7\x9b\xae\xe5\xbd\x95\xef\xbc\x81 \r\n\t\t\t\r\n\t\t\t
- \r\n\t\t\t\t\t
- DmozDir\xe9\xa6\x96\xe9\xa1\xb5 \r\n\t\t\t\t\t
 \xe6\x8f\x90\xe4\xba\xa4\xe7\xbd\x91\xe7\xab\x99 \r\n\t\t\t\t\t
\xe6\x8f\x90\xe4\xba\xa4\xe7\xbd\x91\xe7\xab\x99 \r\n\t\t\t\t\t- | \r\n\t\t\t\t\t
- \xe6\x9c\x80\xe6\x96\xb0\xe6\x94\xb6\xe5\xbd\x95 \r\n\t\t\t\t\t
- | \r\n\t\t\t\t\t
- \xe5\x85\xa5\xe7\xab\x99\xe6\x8e\x92\xe8\xa1\x8c\xe6\xa6\x9c \r\n\t\t\t\t\t
- | \r\n\t\t\t\t\t
- \xe5\xbb\xba\xe7\xab\x99\xe8\xb5\x84\xe8\xae\xaf \r\n\t\t\t\t\t
- | \r\n\t\t\t\t\t
- \xe4\xba\x86\xe8\xa7\xa3\xe6\x9c\xac\xe7\xab\x99 \r\n\t\t\t\t
\r\n\t\t\t\t\xe7\x9b\xae\xe5\xbd\x95\xe5\x88\x86\xe7\xb1\xbb\r\n\t\t\t\t\r\n\t\t\t\t\t- \xe5\xa8\xb1\xe4\xb9\x90\xe4\xbc\x91\xe9\x97\xb2
- \xe5\xb7\xa5\xe5\x95\x86\xe4\xb8\x8e\xe7\xbb\x8f\xe6\xb5\x8e
- \xe7\x94\xb5\xe8\x84\x91\xe4\xb8\x8e\xe7\xbd\x91\xe7\xbb\x9c
- \xe5\x85\xac\xe5\x8f\xb8\xe4\xb8\x8e\xe4\xbc\x81\xe4\xb8\x9a
- \xe6\x95\x99\xe8\x82\xb2\xe4\xb8\x8e\xe5\x9f\xb9\xe8\xae\xad
- \xe6\x96\x87\xe5\xad\xa6
- \xe8\x89\xba\xe6\x9c\xaf
- \xe4\xbd\x93\xe8\x82\xb2\xe4\xb8\x8e\xe5\x81\xa5\xe8\xba\xab
- \xe6\x96\xb0\xe9\x97\xbb\xe4\xb8\x8e\xe5\xaa\x92\xe4\xbd\x93
- \xe5\x8d\xab\xe7\x94\x9f\xe4\xb8\x8e\xe5\x81\xa5\xe5\xba\xb7
- \xe7\xa7\x91\xe5\xad\xa6/\xe6\x96\x87\xe5\x8c\x96
- \xe7\x94\x9f\xe6\xb4\xbb\xe4\xb8\x8e\xe6\x9c\x8d\xe5\x8a\xa1
- \xe6\x97\x85\xe6\xb8\xb8\xe4\xb8\x8e\xe4\xba\xa4\xe9\x80\x9a
- \xe6\x94\xbf\xe6\xb2\xbb/\xe6\xb3\x95\xe5\xbe\x8b/\xe5\x86\x9b\xe4\xba\x8b
- \xe7\xa4\xbe\xe4\xbc\x9a\xe7\xa7\x91\xe5\xad\xa6
\r\n\t\t\t\t
\r\n\t\t\t
\r\n\t\t\t\r\n\t\t\t\t\xe5\x9c\xb0\xe5\x8c\xba\xe5\x88\x86\xe7\xb1\xbb\r\n\t\t\t\t\r\n\t\t\t\t\t- \xe5\x8c\x97\xe4\xba\xac
- \xe4\xb8\x8a\xe6\xb5\xb7
- \xe5\xa4\xa9\xe6\xb4\xa5
- \xe9\x87\x8d\xe5\xba\x86
- \xe6\xb5\x99\xe6\xb1\x9f\xe7\x9c\x81
- \xe5\xb9\xbf\xe4\xb8\x9c\xe7\x9c\x81
- \xe6\xb1\x9f\xe8\x8b\x8f\xe7\x9c\x81
- \xe6\xb2\xb3\xe5\x8c\x97\xe7\x9c\x81
- \xe5\xb1\xb1\xe8\xa5\xbf\xe7\x9c\x81
- \xe5\x9b\x9b\xe5\xb7\x9d\xe7\x9c\x81
- \xe6\xb2\xb3\xe5\x8d\x97\xe7\x9c\x81
- \xe8\xbe\xbd\xe5\xae\x81\xe7\x9c\x81
- \xe5\x90\x89\xe6\x9e\x97\xe7\x9c\x81
- \xe9\xbb\x91\xe9\xbe\x99\xe6\xb1\x9f\xe7\x9c\x81
- \xe5\xb1\xb1\xe4\xb8\x9c\xe7\x9c\x81
- \xe5\xae\x89\xe5\xbe\xbd\xe7\x9c\x81
- \xe7\xa6\x8f\xe5\xbb\xba\xe7\x9c\x81
- \xe6\xb9\x96\xe5\x8c\x97\xe7\x9c\x81
- \xe6\xb9\x96\xe5\x8d\x97\xe7\x9c\x81
- \xe6\xb5\xb7\xe5\x8d\x97\xe7\x9c\x81
- \xe6\xb1\x9f\xe8\xa5\xbf\xe7\x9c\x81
- \xe8\xb4\xb5\xe5\xb7\x9e\xe7\x9c\x81
- \xe4\xba\x91\xe5\x8d\x97\xe7\x9c\x81
- \xe9\x99\x95\xe8\xa5\xbf\xe7\x9c\x81
- \xe7\x94\x98\xe8\x82\x83\xe7\x9c\x81
- \xe5\xb9\xbf\xe8\xa5\xbf\xe5\x8c\xba
- \xe5\xae\x81\xe5\xa4\x8f\xe5\x8c\xba
- \xe9\x9d\x92\xe6\xb5\xb7\xe7\x9c\x81
- \xe6\x96\xb0\xe7\x96\x86\xe5\x8c\xba
- \xe8\xa5\xbf\xe8\x97\x8f\xe5\x8c\xba
- \xe5\x86\x85\xe8\x92\x99\xe5\x8f\xa4\xe5\x8c\xba
- \xe9\xa6\x99\xe6\xb8\xaf
- \xe6\xbe\xb3\xe9\x97\xa8
- \xe5\x8f\xb0\xe6\xb9\xbe
- \xe5\x9b\xbd\xe5\xa4\x96
\r\n\t\t\t\t
\r\n\t\t\t
\r\n\t\t- \r\n\xe5\xb0\x8f\xe5\x9e\x8b\xe9\x99\xa4\xe5\xb0\x98\xe5\x99\xa8 \xe8\x84\x89\xe5\x86\xb2\xe9\x99\xa4\xe5\xb0\x98\xe5\x99\xa8 \xe5\xb8\x83\xe8\xa2\x8b\xe9\x99\xa4\xe5\xb0\x98\xe5\x99\xa8 \xe9\x99\xa4\xe5\xb0\x98\xe5\x99\xa8\xe9\xaa\xa8\xe6\x9e\xb6 \xe9\x99\xa4\xe5\xb0\x98\xe5\x99\xa8\xe5\xb8\x83\xe8\xa2\x8b \xe7\x94\xb5\xe7\xa3\x81\xe8\x84\x89\xe5\x86\xb2\xe9\x98\x80 \xe5\x8d\x95\xe6\x9c\xba\xe9\x99\xa4\xe5\xb0\x98\xe5\x99\xa8 \xe6\x97\x8b\xe9\xa3\x8e\xe9\x99\xa4\xe5\xb0\x98\xe5\x99\xa8 \xe8\x84\x89\xe5\x86\xb2\xe5\xb8\x83\xe8\xa2\x8b\xe9\x99\xa4\xe5\xb0\x98\xe5\x99\xa8\r\n\t\t\t
 \r\n\r\n\t\t\t
\r\n\r\n\t\t\t\xe7\x94\x9f\xe6\xb4\xbb\xe4\xb8\x8e\xe6\x9c\x8d\xe5\x8a\xa1 > \xe5\xa9\x9a\xe6\x81\x8b\xe4\xba\xa4\xe5\x8f\x8b
\r\n\t\t\t\t\t\r\n\t\t\t\t\t- \r\n\t\t\t\t\t\t
- \xe6\x8e\x92\xe5\xba\x8f\xe6\x96\xb9\xe5\xbc\x8f: \r\n\t\t\t\t\t\t
- \xe5\x85\xa5\xe7\xab\x99\xe6\xb5\x81\xe9\x87\x8f \r\n\t\t\t\t\t\t
- \xe5\x87\xba\xe7\xab\x99\xe6\xb5\x81\xe9\x87\x8f \r\n\t\t\t\t\t\t
- \xe4\xba\xba\xe6\xb0\x94\xe6\x8c\x87\xe6\x95\xb0 \r\n
- \xe6\xa0\x87\xe9\xa2\x98\xe6\x8e\x92\xe5\xba\x8f \r\n\t\t\t\t\t
- \r\n\t\t\t\t\t\t
- \xe5\x90\x84\xe5\x9c\xb0\xe7\x94\x9f\xe6\xb4\xbb546
- \xe5\xa9\x9a\xe6\x81\x8b\xe4\xba\xa4\xe5\x8f\x8b176
- \xe5\x85\xac\xe5\x8f\xb8\xe4\xbc\x81\xe4\xb8\x9a400
- \xe7\x94\x9f\xe6\xb4\xbb\xe5\xb8\xb8\xe8\xaf\x86103
- \xe9\xa4\x90\xe9\xa5\xae/\xe8\x8f\x9c\xe8\xb0\xb1360
- \xe8\xb4\xad\xe7\x89\xa91192
- \xe7\xa7\x9f\xe6\x88\xbf127
- \xe7\xa7\x9f\xe8\xb5\x81/\xe5\x80\x9f\xe8\xb4\xb7112
- \xe5\xa4\xa9\xe6\xb0\x94\xe9\xa2\x84\xe6\x8a\xa519
- \xe5\xae\xb6\xe7\x94\xa8\xe7\x94\xb5\xe5\x99\xa8154
- \xe5\xb8\xb8\xe7\x94\xa8\xe6\x9f\xa5\xe8\xaf\xa265
- \xe5\x9c\xb0\xe5\x9b\xbe19
- \xe6\x89\x8b\xe6\x9c\xba\xe7\x9f\xad\xe4\xbf\xa139
- \xe9\xa2\x84\xe8\xae\xa2\xe6\x9c\x8d\xe5\x8a\xa133
- \xe6\x8b\x8d\xe5\x8d\x9611
- \xe5\xae\xb6\xe6\x94\xbf\xe6\x9c\x8d\xe5\x8a\xa1196
- \xe4\xb8\xaa\xe4\xba\xba\xe7\xbe\x8e\xe5\x8c\x96158
- \xe7\x94\x9f\xe6\xb4\xbb\xe6\x83\x85\xe8\xb6\xa352
- \xe8\xa3\x85\xe9\xa5\xb0/\xe8\xa3\x85\xe4\xbf\xae473
- \xe7\xb4\xa7\xe6\x80\xa5\xe6\x9c\x8d\xe5\x8a\xa115
- \xe7\xbb\xbc\xe5\x90\x88\xe7\xbd\x91\xe7\xab\x99516
- \xe6\x96\xb0\xe9\x97\xbb\xe5\xaa\x92\xe4\xbd\x9314
- \xe6\x88\x90\xe4\xba\xba\xe7\x94\xa8\xe5\x93\x817
- \xe7\xbd\x91\xe4\xb8\x8a\xe6\x95\x91\xe5\x8a\xa97
- \xe4\xbc\x9a\xe5\xb1\x95\xe6\xb4\xbb\xe5\x8a\xa823
- \xe6\xb1\x82\xe5\x8c\xbb\xe9\x97\xae\xe8\x8d\xaf75
- \xe4\xbd\x93\xe8\x82\xb2\xe5\x81\xa5\xe8\xba\xab10
- \xe8\xae\xba\xe5\x9d\x9b/\xe8\x81\x8a\xe5\xa4\xa9\xe5\xae\xa475
- \xe5\x8a\x9e\xe5\x85\xac\xe6\x9c\x8d\xe5\x8a\xa131 \r\n\t\t\t\t\t
\xe5\x90\x91\xe8\xaf\xa5\xe7\x9b\xae\xe5\xbd\x95\xe6\x8f\x90\xe4\xba\xa4\xe7\xbd\x91\xe7\xab\x99
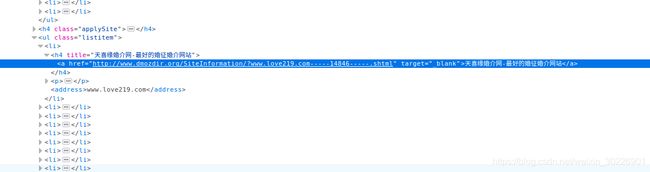
\r\n\t\t\t\t\t\xe5\xa4\xa9\xe5\x96\x9c\xe7\xbc\x98\xe5\xa9\x9a\xe4\xbb\x8b\xe7\xbd\x91-\xe6\x9c\x80\xe5\xa5\xbd\xe7\x9a\x84\xe5\xa9\x9a\xe5\xbe\x81\xe5\xa9\x9a\xe4\xbb\x8b\xe7\xbd\x91\xe7\xab\x99
\xe5\xa4\xa9\xe5\x96\x9c\xe7\xbc\x98\xe5\xa9\x9a\xe4\xbb\x8b\xe5\xa9\x9a\xe5\xba\x86\xe7\xbd\x91\xe6\x98\xaf\xe6\xb5\x8e\xe5\x8d\x97\xe6\x9c\x80\xe4\xb8\x93\xe4\xb8\x9a\xe7\x9a\x84\xe5\xa9\x9a\xe4\xbb\x8b\xe7\xbd\x91\xe7\xab\x99\xe3\x80\x81\xe5\xa9\x9a\xe5\xba\x86\xe7\xbd\x91\xe7\xab\x99\xef\xbc\x8c\xe4\xba\xa4\xe5\x8f\x8b\xe7\xbd\x91\xe7\xab\x99\xef\xbc\x8c\xe5\x8f\x8a\xe6\xb5\x8e\xe5\x8d\x97\xe5\xbe\x81\xe5\xa9\x9a\xe3\x80\x81\xe6\xb5\x8e\xe5\x8d\x97\xe4\xba\xa4\xe5\x8f\x8b\xe3\x80\x81\xe6\xb5\x8e\xe5\x8d\x97\xe5\xa9\x9a\xe4\xbb\x8b\xe3\x80\x81\xe6\xb5\x8e\xe5\x8d\x97\xe5\xba\x86\xe5\x85\xb8\xe3\x80\x81\xe6\xb5\x8e\xe5\x8d\x97\xe7\xa4\xbc\xe4\xbb\xaa\xe4\xba\x8e\xe4\xb8\x80\xe4\xbd\x93\xef\xbc\x8c\xe7\xbd\x91\xe4\xb8\x8b\xe6\x9c\x89\xe5\xae\x9e\xe4\xbd\x93\xe5\xba\x97\xe9\x9d\xa2-\xe6\xb5\x8e\xe5\x8d\x97\xe5\xb8\x82\xe5\xb8\x82\xe4\xb8\xad\xe5\x8c\xba\xe5\xa4\xa9\xe5\x96\x9c\xe7\xbc\x98\xe5\xa9\x9a\xe4\xbb\x8b\xe5\xa9\x9a\xe5\xba\x86\xe4\xb8\xad\xe5\xbf\x83\xef\xbc\x8c\xe4\xb8\x8d\xe5\xae\x9a\xe6\x9c\x9f\xe4\xb8\xbe\xe5\x8a\x9e\xe8\x81\x94\xe8\xb0\x8a\xe6\xb4\xbb\xe5\x8a\xa8\xef\xbc\x8c\xe4\xbf\x9d\xe8\xaf\x81\xe4\xbc\x9a\xe5\x91\x98\xe6\x88\x90\xe5\x8a\x9f\xe7\x8e\x87
www.love219.com\xe6\x88\x90\xe9\x83\xbd\xe7\x9b\x9b\xe4\xb8\x96\xe9\x98\xb3\xe5\x85\x89\xe5\xa9\x9a\xe5\xba\x86\xe7\xad\x96\xe5\x88\x92\xe6\x9c\x89\xe9\x99\x90\xe5\x85\xac\xe5\x8f\xb8
\xe8\xaf\x9a\xe4\xbf\xa1\xe6\x8a\x95\xe8\xb5\x84\xe6\x8e\xa7\xe8\x82\xa1\xe9\x9b\x86\xe5\x9b\xa2\xe5\xb1\x9e\xe4\xba\x8e\xe5\x9b\x9b\xe5\xb7\x9d\xe7\x9c\x81\xe5\xa4\xa7\xe5\x9e\x8b\xe4\xbc\x81\xe4\xb8\x9a\xe9\x9b\x86\xe5\x9b\xa2\xef\xbc\x8c\xe5\xb7\x9d\xe5\x86\x85\xe6\x8e\x92\xe4\xba\x8e\xe5\x89\x8d20\xe5\x90\x8d\xef\xbc\x8c\xe6\xb3\xa8\xe5\x86\x8c\xe8\xb5\x84\xe9\x87\x913.5\xe4\xba\xbf\xe5\x85\x83\xef\xbc\x8c\xe6\x8b\xa5\xe6\x9c\x89\xe5\x9b\xba\xe5\xae\x9a\xe8\xb5\x84\xe4\xba\xa746.5\xe4\xba\xbf\xe3\x80\x82\xe5\x85\xac\xe5\x8f\xb8\xe6\x80\xbb\xe9\x83\xa8\xe4\xbd\x8d\xe4\xba\x8e\xe6\x88\x90\xe9\x83\xbd\xe5\xb8\x82\xe8\x87\xb4\xe6\xb0\x91\xe4\xb8\x9c\xe8\xb7\xaf1\xe5\x8f\xb7\xe3\x80\x82\xe5\x9c\xa8\xe5\x8c\x97\xe4\xba\xac\xe3\x80\x81\xe4\xb8\x8a\xe6\xb5\xb7\xe3\x80\x81\xe6\x96\xb0\xe7\x96\x86\xe7\xad\x89\xe5\x9c\xb0\xe8\xae\xbe\xe6\x9c\x89\xe5\x88\x86\xe5\x85\xac\xe5\x8f\xb8\xe3\x80\x82\xe8\xaf\x9a\xe4\xbf\xa1\xe7\x9b\x9b\xe4\xb8\x96\xe9\x98\xb3\xe5\x85\x89\xe5\xa9\x9a\xe5\xba\x86\xe5\x85\xac\xe5\x8f\xb8\xe6\x98\xaf\xe5\x85\xb6\xe5\xad\x90\xe5\x85\xac\xe5\x8f\xb8\xe3\x80\x82
www.ssyg520.com\xe6\x83\x85\xe4\xba\xba\xe7\xbd\x91
\xe6\x83\x85\xe4\xba\xba\xe7\xbd\x91\xe4\xba\xa4\xe5\x8f\x8b\xe4\xb8\xad\xe5\xbf\x83\xe4\xb8\xba\xe4\xbd\xa0\xe6\x8f\x90\xe4\xbe\x9b\xe6\x9c\x80\xe4\xbd\xb3\xe7\x9a\x84\xe7\xbd\x91\xe4\xb8\x8a\xe6\x83\x85\xe4\xba\xba\xe4\xba\xa4\xe5\x8f\x8b\xe6\x9c\xba\xe4\xbc\x9a\xef\xbc\x8c\xe8\xb6\xb3\xe4\xb8\x8d\xe5\x87\xba\xe6\x88\xb7\xe4\xbe\xbf\xe8\x83\xbd\xe8\xae\xa9\xe4\xbd\xa0\xe6\x9c\x89\xe6\x9b\xb4\xe5\xa4\x9a\xe7\x9a\x84\xe9\x80\x89\xe6\x8b\xa9\xef\xbc\x81
www.591lover.net\xe5\x9b\xbd\xe9\x99\x85\xe5\x85\x8d\xe8\xb4\xb9\xe5\xa9\x9a\xe4\xbb\x8b\xe4\xba\xa4\xe5\x8f\x8b\xe7\xbd\x91\xe7\xab\x99-\xe7\x9b\xb8\xe7\xba\xa6100
\xe5\x9b\xbd\xe9\x99\x85\xe5\x85\x8d\xe8\xb4\xb9\xe5\xa9\x9a\xe4\xbb\x8b\xe4\xba\xa4\xe5\x8f\x8b\xe7\xbd\x91\xe7\xab\x99\xe6\x98\xaf\xe7\x9b\xb8\xe7\xba\xa6100\xe6\x8f\x90\xe4\xbe\x9b\xe7\x9a\x84\xe5\xae\x8c\xe5\x85\xa8\xe5\x85\x8d\xe8\xb4\xb9\xe7\x9a\x84\xe5\x9b\xbd\xe9\x99\x85\xe4\xba\xa4\xe5\x8f\x8b\xe7\xbd\x91\xe7\xab\x99\xe3\x80\x82\xe4\xbc\x9a\xe5\x91\x98\xe4\xbb\xa5\xe5\x8d\x8e\xe4\xba\xba\xe4\xb8\xba\xe4\xb8\xbb\xe9\x81\x8d\xe5\xb8\x83\xe4\xba\x94\xe6\xb9\x96\xe5\x9b\x9b\xe6\xb5\xb7,\xe6\x89\x80\xe6\x9c\x89\xe4\xbc\x9a\xe5\x91\x98\xe5\xae\x8c\xe5\x85\xa8\xe5\x85\x8d\xe8\xb4\xb9\xe3\x80\x82\xe6\x89\x80\xe6\x9c\x89\xe5\xaf\xbb\xe6\x89\xbe\xe5\x9b\xbd\xe9\x99\x85\xe5\x85\x8d\xe8\xb4\xb9\xe5\xa9\x9a\xe4\xbb\x8b\xe4\xba\xa4\xe5\x8f\x8b\xe7\xbd\x91\xe7\xab\x99\xe7\x9a\x84\xe6\x9c\x8b\xe5\x8f\x8b\xe9\x83\xbd\xe8\x83\xbd\xe5\x9c\xa8\xe5\x9b\xbd\xe9\x99\x85\xe4\xba\xa4\xe5\x8f\x8b\xe7\xbd\x91\xe7\xab\x99\xe5\x9c\xa8\xe6\x89\xbe\xe5\x88\xb0\xe5\xae\x8c\xe5\x85\xa8\xe5\x85\x8d\xe8\xb4\xb9\xe7\x9a\x84\xe5\x9b\xbd\xe9\x99\x85\xe5\x85\x8d\xe8\xb4\xb9\xe5\xa9\x9a\xe4\xbb\x8b\xe4\xba\xa4\xe5\x8f\x8b\xe7\xbd\x91\xe7\xab\x99\xe6\x9c\x8d\xe5\x8a\xa1
www.free-onlinedating.me\xe5\xae\x89\xe5\xbe\xbd\xe5\xa9\x9a\xe5\xba\x86\xe7\xbd\x91
\xe5\xae\x89\xe5\xbe\xbd\xe5\xa9\x9a\xe5\xba\x86\xe7\xbd\x91
www.ahhqw.com\xe8\x81\x9a\xe7\xbc\x98\xe5\x8c\x97\xe6\xb5\xb7\xe4\xba\xa4\xe5\x8f\x8b\xe7\xbd\x91
\xe8\x81\x9a\xe7\xbc\x98\xe5\x8c\x97\xe6\xb5\xb7\xe4\xba\xa4\xe5\x8f\x8b\xe7\xbd\x91\xe6\x98\xaf\xe5\x8c\x97\xe6\xb5\xb7\xe5\x9c\xb0\xe5\x8c\xba\xe8\xbe\x83\xe8\xa7\x84\xe8\x8c\x83\xe7\x9a\x84\xe5\xa9\x9a\xe6\x81\x8b\xe4\xba\xa4\xe5\x8f\x8b\xe7\xbd\x91\xe7\xab\x99\xef\xbc\x8c\xe8\x87\xb4\xe5\x8a\x9b\xe4\xba\x8e\xe8\x90\xa5\xe9\x80\xa0\xe6\x9c\x89\xe8\xb6\xa3\xe8\x80\x8c\xe5\xae\x89\xe5\x85\xa8\xe7\x9a\x84\xe7\xbd\x91\xe7\xbb\x9c\xe4\xba\xa4\xe5\x8f\x8b\xe7\xa4\xbe\xe5\x8c\xba\xef\xbc\x8c\xe6\x8f\x90\xe4\xbe\x9b\xe6\x90\x9c\xe7\xb4\xa2\xe3\x80\x81\xe7\xbe\x8e\xe6\x96\x87\xe3\x80\x81\xe7\xba\xa6\xe4\xbc\x9a\xe3\x80\x81\xe6\x97\xa5\xe8\xae\xb0\xe3\x80\x81\xe8\x81\x8a\xe5\xa4\xa9\xe3\x80\x81\xe7\xad\x89\xe5\xa4\x9a\xe9\xa1\xb9\xe4\xba\xa4\xe5\x8f\x8b\xe6\x9c\x8d\xe5\x8a\xa1\xe3\x80\x82\xe5\xb9\xb6\xe4\xb8\x8e\xe5\x9c\xb0\xe6\x96\xb9\xe5\xa9\x9a\xe4\xbb\x8b\xe9\x83\xa8\xe9\x97\xa8\xe5\xbb\xba\xe7\xab\x8b\xe4\xba\x86\xe8\x89\xaf\xe5\xa5\xbd\xe7\x9a\x84\xe5\x90\x88\xe4\xbd\x9c\xe5\x85\xb3\xe7\xb3\xbb\xe3\x80\x82
www.jyjjyy.com\xe7\x88\xb1\xe6\x88\x91\xe5\x90\xa7\xe5\xa9\x9a\xe6\x81\x8b\xe7\xbd\x91
\xe7\x88\xb1\xe6\x88\x91\xe5\x90\xa7\xe5\xa9\x9a\xe6\x81\x8b\xe7\xbd\x91\xe6\x98\xaf\xe4\xb8\x80\xe4\xb8\xaa\xe7\x9c\x9f\xe5\xae\x9e\xe3\x80\x81\xe4\xb8\xa5\xe8\x82\x83\xe3\x80\x81\xe9\xab\x98\xe5\x93\x81\xe4\xbd\x8d\xe7\x9a\x84\xe5\xa9\x9a\xe6\x81\x8b\xe5\xb9\xb3\xe5\x8f\xb0\xef\xbc\x8c\xe6\x8f\x90\xe4\xbe\x9b\xe7\xa7\x91\xe5\xad\xa6\xe3\x80\x81\xe9\xab\x98\xe6\x95\x88\xe7\x9a\x84\xe5\x85\xa8\xe7\xa8\x8b\xe6\x9c\x8d\xe5\x8a\xa1\xef\xbc\x8c\xe5\xb8\xae\xe5\x8a\xa9\xe7\x9c\x9f\xe5\xbf\x83\xe5\xaf\xbb\xe6\x89\xbe\xe7\xbb\x88\xe8\xba\xab\xe4\xbc\xb4\xe4\xbe\xa3\xe7\x9a\x84\xe4\xba\xba\xe5\xa3\xab\xe5\xae\x9e\xe7\x8e\xb0\xe5\x92\x8c\xe8\xb0\x90\xe5\xa9\x9a\xe6\x81\x8b\xef\xbc\x8c\xe5\x8a\xaa\xe5\x8a\x9b\xe8\x90\xa5\xe9\x80\xa0\xe5\x9b\xbd\xe5\x86\x85\xe6\x9c\x80\xe4\xb8\x93\xe4\xb8\x9a\xe3\x80\x81\xe4\xb8\xa5\xe8\x82\x83\xe7\x9a\x84\xe5\xa9\x9a\xe6\x81\x8b\xe4\xba\xa4\xe5\x8f\x8b\xe5\xb9\xb3
www.lovemeba.com77\xe5\x9b\xbd\xe9\x99\x85\xe4\xba\xa4\xe5\x8f\x8b\xe7\xbd\x91
\xe7\xba\xaf\xe5\x85\xac\xe7\x9b\x8a\xe6\x80\xa7\xef\xbc\x8c\xe7\x88\xb1\xe5\xbf\x83\xe7\xa4\xbe\xe4\xba\xa4\xe7\xbd\x91\xe7\xab\x99\xef\xbc\x8c\xe4\xb8\xba\xe5\xb9\xbf\xe5\xa4\xa7\xe9\x9d\x92\xe5\xb9\xb4\xe5\x8f\x8a\xe5\x8d\x95\xe8\xba\xab\xe4\xba\xba\xe5\xa3\xab\xe6\x8f\x90\xe4\xbe\x9b\xe7\x9a\x84\xe5\x85\xa8\xe5\x85\x8d\xe8\xb4\xb9\xe4\xba\xa4\xe5\x8f\x8b\xe5\xb9\xb3\xe5\x8f\xb0\xe3\x80\x82
www.77lds.com\xe4\xb8\x9c\xe8\x8e\x9e\xe9\x9f\xa9\xe9\xa3\x8e\xe5\xb0\x9a\xe5\xa9\x9a\xe7\xba\xb1\xe6\x91\x84\xe5\xbd\xb1\xe5\xb7\xa5\xe4\xbd\x9c\xe5\xae\xa4
\xe4\xb8\x9c\xe8\x8e\x9e\xe9\x9f\xa9\xe9\xa3\x8e\xe5\xb0\x9a\xe5\xa9\x9a\xe7\xba\xb1\xe6\x91\x84\xe5\xbd\xb1\xe5\xb7\xa5\xe4\xbd\x9c\xe5\xae\xa4\xe6\x98\xaf\xe5\x85\xb7\xe6\x9c\x89\xe7\x8b\xac\xe7\x89\xb9\xe7\x9a\x84\xe9\x9f\xa9\xe5\x9b\xbd\xe9\xa3\x8e\xe6\xa0\xbc\xe7\x9a\x84\xe4\xb8\x9c\xe8\x8e\x9e\xe5\xa9\x9a\xe7\xba\xb1\xe6\x91\x84\xe5\xbd\xb1\xe5\xb7\xa5\xe4\xbd\x9c\xe5\xae\xa4\xef\xbc\x8c\xe9\x9f\xa9\xe9\xa3\x8e\xe5\xb0\x9a\xe4\xbd\x8d\xe4\xba\x8e\xe4\xb8\x9c\xe8\x8e\x9e\xe4\xb8\x9c\xe5\x9f\x8e\xe5\x8c\xba\xe6\x97\x97\xe5\xb3\xb0\xe8\xb7\xaf\xe5\x9b\xbd\xe6\xb3\xb0\xe5\xa4\xa7\xe5\x8e\xa610\xe5\x8f\xb7,\xe6\x88\x91\xe4\xbb\xac\xe6\xb0\xb8\xe8\xbf\x9c\xe6\xbb\xa1\xe6\x80\x80\xe5\x88\x9b\xe6\x84\x8f\xe4\xb8\x8e\xe6\xb8\xa9\xe6\x83\x85,\xe9\x80\x9a\xe8\xbf\x87\xe4\xb8\x80\xe5\xaf\xb9\xe4\xb8\x80\xe7\x9a\x84\xe6\x9c\x8d\xe5\x8a\xa1\xe4\xb8\xba\xe6\x82\xa8\xe6\x8f\x90\xe4\xbe\x9b\xe8\xb6\x85\xe8\xb6\x8a\xe6\x82\xa8\xe6\x9c\x9f\xe6\x9c\x9b
www.dg-hfs.com\xe7\x99\xbe\xe5\x90\x88\xe5\xa9\x9a\xe7\xa4\xbc\xe7\xa4\xbe\xe5\x8c\xba
\xe7\x99\xbe\xe5\x90\x88\xe5\xa9\x9a\xe7\xa4\xbc\xe7\xa4\xbe\xe5\x8c\xba\xe8\xae\xa8\xe8\xae\xba\xe8\xaf\x9d\xe9\xa2\x98\xe6\xb6\xb5\xe7\x9b\x96\xe5\xa9\x9a\xe7\xba\xb1\xe7\x85\xa7\xe3\x80\x81\xe5\xa9\x9a\xe7\xba\xb1\xe6\x91\x84\xe5\xbd\xb1\xe3\x80\x81\xe5\xa9\x9a\xe7\xa4\xbc\xe7\xad\xb9\xe5\xa4\x87\xe3\x80\x81\xe5\xa9\x9a\xe7\xba\xb1\xe7\xa4\xbc\xe6\x9c\x8d\xe3\x80\x81\xe5\xa9\x9a\xe5\xba\x86\xe7\xad\x89\xe6\x96\xb9\xe9\x9d\xa2
www.lilywed.cn
\r\n\t\t\t\t\t\xe6\x88\x91\xe4\xb9\x9f\xe8\xa6\x81\xe5\x87\xba\xe7\x8e\xb0\xe5\x9c\xa8\xe8\xbf\x99\xe9\x87\x8c | \xe6\x9b\xb4\xe5\xa4\x9a\r\n\t\t\t\t\t\xe6\x9c\x80\xe6\x96\xb0\xe6\x8e\xa8\xe8\x8d\x90\r\n\t\t\t\t
\r\n\t\t\t\t- \r\n

\xe8\xa2\x8b\xe5\xbc\x8f\xe8\x84\x89\xe5\x86\xb2\xe9\x99\xa4\xe5\xb0\x98\xe5\x99\xa8
\r\n\xe7\x94\x9f\xe4\xba\xa7\xe9\x99\xa4\xe5\xb0\x98\xe5\x99\xa8,\xe9\x99\xa4\xe5\xb0\x98\xe9\x85\x8d\xe4\xbb\xb6,\xe9\x99\xa4\xe5\xb0\x98\xe9\xaa\xa8\xe6\x9e\xb6,\xe9\x99\xa4\xe5\xb0\x98\xe5\xb8\x83\xe8\xa2\x8b,\xe8\x84\x89\xe5\x86\xb2\xe7\x94\xb5\xe7\xa3\x81\xe9\x98\x80,\xe6\x8e\xa7\xe5\x88\xb6\xe4\xbb\xaa,\xe6\xb0\x94\xe7\xbc\xb8\xe7\x9a\x84\xe4\xbc\x81\xe4\xb8\x9a\xe3\x80\x82
\r\nwww.chb01.cn\r\n \r\n - \r\n

\xe9\x99\xa4\xe5\xb0\x98\xe5\x99\xa8\xe9\x99\xa4\xe5\xb0\x98\xe5\xb8\x83\xe8\xa2\x8b\xe9\x99\xa4\xe5\xb0\x98\xe9\xaa\xa8\xe6\x9e\xb6-\xe5\xae\x8f\xe5\xae\x87\xe7\x8e\xaf\xe4\xbf\x9d
\r\n\xe9\x99\xa4\xe5\xb0\x98\xe5\x99\xa8,\xe9\x99\xa4\xe5\xb0\x98\xe9\x85\x8d\xe4\xbb\xb6,\xe9\x99\xa4\xe5\xb0\x98\xe9\xaa\xa8\xe6\x9e\xb6,\xe9\x99\xa4\xe5\xb0\x98\xe5\xb8\x83\xe8\xa2\x8b,\xe8\x84\x89\xe5\x86\xb2\xe7\x94\xb5\xe7\xa3\x81\xe9\x98\x80,\xe6\x8e\xa7\xe5\x88\xb6\xe4\xbb\xaa,\xe6\xb0\x94\xe7\xbc\xb8\xe7\x9a\x84\xe4\xb8\x93\xe4\xb8\x9a\xe7\x94\x9f\xe4\xba\xa7\xe4\xbc\x81\xe4\xb8\x9a\xe3\x80\x82
\r\nwww.chuchenhb.com\r\n \r\n