ubuntu 18.04 安装nvidia K80驱动 +CUDA10+cuDNN7.4.1.5
首先注意几个坑:
1 不必先安装显卡驱动,cudaToolkit自带有驱动了。先安装反而报各种错误
2 cudaToolKit一定要选择runFile,不要选择deb,否则会报错,并且不能再安装时选择配置
3 安装gcc,ubuntu18.04默认安装版本7.3,在进行cuda和cudnn安装测试时不能make,需要将gcc降级,比如5.5
详细安装步骤(待完善)
准备工作,下载cuda和cudnn:
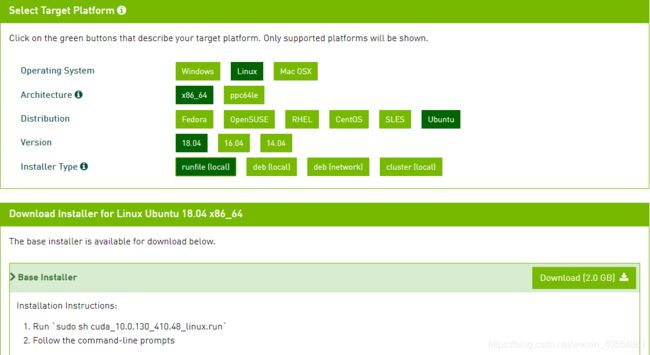
cuda10
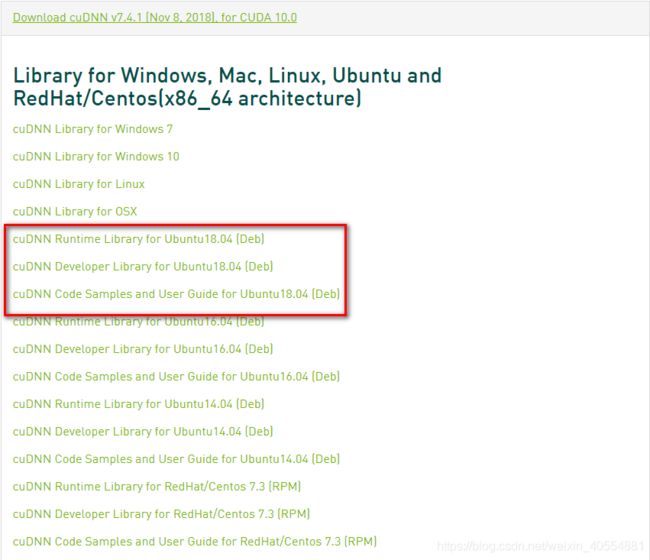
cudnn下载地址
1 禁用nouvea显卡驱动
sudo nano /etc/modprobe.d/blacklist-nouveau.conf在结尾添加
blacklist nouveau
接着执行
sudo update-initramfs -u
sudo reboot重启后执行:
lsmod | grep nouveau没有输出即屏蔽好了.
2 关闭图形界面(注意是关闭,不是切换),重启选择进入命令行界面
关闭图形界面:
sudo systemctl set-default multi-user.target
sudo reboot打开图形界面
sudo systemctl set-default graphical.target
sudo reboot3 先彻底删除原有nvidia驱动
sudo apt-get remove --purge nvidia* 4 安装cuda10, –no-opengl-files参数一定要加上,注意no前面‘--’
./cuda_10.0.130_410.48_linux.run –no-opengl-files设置环境变量
PATH=/usr/local/cuda/bin:$PATH
LD_LIBRARY_PATH=/usr/local/cuda/lib64:$LD_LIBRARY_PATH
export PATH
export LD_LIBRARY_PATH
sudo su #切换到root账户
echo "/usr/local/cuda/lib64" > /etc/ld.so.conf.d/cuda.conf
5 安装cudnn7
sudo dpkg -i libcudnn7_7.4.1.5-1+cuda10.0_amd64.deb
sudo dpkg -i libcudnn7-dev_7.4.1.5-1+cuda10.0_amd64.deb
sudo dpkg -i libcudnn7-doc_7.4.1.5-1+cuda10.0_amd64.deb6 降级gcc
首先查看自己的gcc版本,Ubuntu18.04上默认的是7.3版本:
>>gcc --version
gcc (Ubuntu 7.3.0-27ubuntu1~18.04) 7.3.0
Copyright (C) 2017 Free Software Foundation, Inc.
This is free software; see the source for copying conditions. There is NO
warranty; not even for MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE.
删除某个gcc版本的选项的话,可以使用命令:
sudo update-alternatives --remove gcc /usr/bin/* #(*为gcc版本号,比如gcc-4.8)
sudo apt-get auto-remove gcc-4.8下载gcc/g++ 5:
sudo apt-get install -y gcc-5
sudo apt-get install -y g++-5
链接gcc/g++实现降级:
cd /usr/bin
sudo rm gcc
sudo ln -s gcc-5 gcc
sudo rm g++
sudo ln -s g++-5 g++
再次查看gcc版本,可以看到已经降级:
>>gcc --version
gcc (Ubuntu 5.5.0-12ubuntu1) 5.5.0 20171010
Copyright (C) 2015 Free Software Foundation, Inc.
This is free software; see the source for copying conditions. There is NO
warranty; not even for MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE.
7 测试cuda
cd /usr/local/cuda/samples/1_Utilities/deviceQuery #由自己电脑目录决定
sudo make
sudo ./deviceQuery
返回结果:
CUDA Device Query (Runtime API) version (CUDART static linking)
Detected 4 CUDA Capable device(s)
Device 0: "Tesla K80"
CUDA Driver Version / Runtime Version 10.0 / 10.0
CUDA Capability Major/Minor version number: 3.7
Total amount of global memory: 11441 MBytes (11996954624 bytes)
(13) Multiprocessors, (192) CUDA Cores/MP: 2496 CUDA Cores
GPU Max Clock rate: 824 MHz (0.82 GHz)
Memory Clock rate: 2505 Mhz
Memory Bus Width: 384-bit
L2 Cache Size: 1572864 bytes
Maximum Texture Dimension Size (x,y,z) 1D=(65536), 2D=(65536, 65536), 3D=(4096, 4096, 4096)
Maximum Layered 1D Texture Size, (num) layers 1D=(16384), 2048 layers
Maximum Layered 2D Texture Size, (num) layers 2D=(16384, 16384), 2048 layers
Total amount of constant memory: 65536 bytes
Total amount of shared memory per block: 49152 bytes
Total number of registers available per block: 65536
Warp size: 32
Maximum number of threads per multiprocessor: 2048
Maximum number of threads per block: 1024
Max dimension size of a thread block (x,y,z): (1024, 1024, 64)
Max dimension size of a grid size (x,y,z): (2147483647, 65535, 65535)
Maximum memory pitch: 2147483647 bytes
Texture alignment: 512 bytes
Concurrent copy and kernel execution: Yes with 2 copy engine(s)
Run time limit on kernels: No
Integrated GPU sharing Host Memory: No
Support host page-locked memory mapping: Yes
Alignment requirement for Surfaces: Yes
Device has ECC support: Enabled
Device supports Unified Addressing (UVA): Yes
Device supports Compute Preemption: No
Supports Cooperative Kernel Launch: No
Supports MultiDevice Co-op Kernel Launch: No
Device PCI Domain ID / Bus ID / location ID: 0 / 7 / 0
Compute Mode:
< Default (multiple host threads can use ::cudaSetDevice() with device simultaneously) >
Device 1: "Tesla K80"
CUDA Driver Version / Runtime Version 10.0 / 10.0
CUDA Capability Major/Minor version number: 3.7
Total amount of global memory: 11441 MBytes (11996954624 bytes)
(13) Multiprocessors, (192) CUDA Cores/MP: 2496 CUDA Cores
GPU Max Clock rate: 824 MHz (0.82 GHz)
Memory Clock rate: 2505 Mhz
Memory Bus Width: 384-bit
L2 Cache Size: 1572864 bytes
Maximum Texture Dimension Size (x,y,z) 1D=(65536), 2D=(65536, 65536), 3D=(4096, 4096, 4096)
Maximum Layered 1D Texture Size, (num) layers 1D=(16384), 2048 layers
Maximum Layered 2D Texture Size, (num) layers 2D=(16384, 16384), 2048 layers
Total amount of constant memory: 65536 bytes
Total amount of shared memory per block: 49152 bytes
Total number of registers available per block: 65536
Warp size: 32
Maximum number of threads per multiprocessor: 2048
Maximum number of threads per block: 1024
Max dimension size of a thread block (x,y,z): (1024, 1024, 64)
Max dimension size of a grid size (x,y,z): (2147483647, 65535, 65535)
Maximum memory pitch: 2147483647 bytes
Texture alignment: 512 bytes
Concurrent copy and kernel execution: Yes with 2 copy engine(s)
Run time limit on kernels: No
Integrated GPU sharing Host Memory: No
Support host page-locked memory mapping: Yes
Alignment requirement for Surfaces: Yes
Device has ECC support: Enabled
Device supports Unified Addressing (UVA): Yes
Device supports Compute Preemption: No
Supports Cooperative Kernel Launch: No
Supports MultiDevice Co-op Kernel Launch: No
Device PCI Domain ID / Bus ID / location ID: 0 / 8 / 0
Compute Mode:
< Default (multiple host threads can use ::cudaSetDevice() with device simultaneously) >
Device 2: "Tesla K80"
CUDA Driver Version / Runtime Version 10.0 / 10.0
CUDA Capability Major/Minor version number: 3.7
Total amount of global memory: 11441 MBytes (11996954624 bytes)
(13) Multiprocessors, (192) CUDA Cores/MP: 2496 CUDA Cores
GPU Max Clock rate: 824 MHz (0.82 GHz)
Memory Clock rate: 2505 Mhz
Memory Bus Width: 384-bit
L2 Cache Size: 1572864 bytes
Maximum Texture Dimension Size (x,y,z) 1D=(65536), 2D=(65536, 65536), 3D=(4096, 4096, 4096)
Maximum Layered 1D Texture Size, (num) layers 1D=(16384), 2048 layers
Maximum Layered 2D Texture Size, (num) layers 2D=(16384, 16384), 2048 layers
Total amount of constant memory: 65536 bytes
Total amount of shared memory per block: 49152 bytes
Total number of registers available per block: 65536
Warp size: 32
Maximum number of threads per multiprocessor: 2048
Maximum number of threads per block: 1024
Max dimension size of a thread block (x,y,z): (1024, 1024, 64)
Max dimension size of a grid size (x,y,z): (2147483647, 65535, 65535)
Maximum memory pitch: 2147483647 bytes
Texture alignment: 512 bytes
Concurrent copy and kernel execution: Yes with 2 copy engine(s)
Run time limit on kernels: No
Integrated GPU sharing Host Memory: No
Support host page-locked memory mapping: Yes
Alignment requirement for Surfaces: Yes
Device has ECC support: Enabled
Device supports Unified Addressing (UVA): Yes
Device supports Compute Preemption: No
Supports Cooperative Kernel Launch: No
Supports MultiDevice Co-op Kernel Launch: No
Device PCI Domain ID / Bus ID / location ID: 0 / 139 / 0
Compute Mode:
< Default (multiple host threads can use ::cudaSetDevice() with device simultaneously) >
Device 3: "Tesla K80"
CUDA Driver Version / Runtime Version 10.0 / 10.0
CUDA Capability Major/Minor version number: 3.7
Total amount of global memory: 11441 MBytes (11996954624 bytes)
(13) Multiprocessors, (192) CUDA Cores/MP: 2496 CUDA Cores
GPU Max Clock rate: 824 MHz (0.82 GHz)
Memory Clock rate: 2505 Mhz
Memory Bus Width: 384-bit
L2 Cache Size: 1572864 bytes
Maximum Texture Dimension Size (x,y,z) 1D=(65536), 2D=(65536, 65536), 3D=(4096, 4096, 4096)
Maximum Layered 1D Texture Size, (num) layers 1D=(16384), 2048 layers
Maximum Layered 2D Texture Size, (num) layers 2D=(16384, 16384), 2048 layers
Total amount of constant memory: 65536 bytes
Total amount of shared memory per block: 49152 bytes
Total number of registers available per block: 65536
Warp size: 32
Maximum number of threads per multiprocessor: 2048
Maximum number of threads per block: 1024
Max dimension size of a thread block (x,y,z): (1024, 1024, 64)
Max dimension size of a grid size (x,y,z): (2147483647, 65535, 65535)
Maximum memory pitch: 2147483647 bytes
Texture alignment: 512 bytes
Concurrent copy and kernel execution: Yes with 2 copy engine(s)
Run time limit on kernels: No
Integrated GPU sharing Host Memory: No
Support host page-locked memory mapping: Yes
Alignment requirement for Surfaces: Yes
Device has ECC support: Enabled
Device supports Unified Addressing (UVA): Yes
Device supports Compute Preemption: No
Supports Cooperative Kernel Launch: No
Supports MultiDevice Co-op Kernel Launch: No
Device PCI Domain ID / Bus ID / location ID: 0 / 140 / 0
Compute Mode:
< Default (multiple host threads can use ::cudaSetDevice() with device simultaneously) >
> Peer access from Tesla K80 (GPU0) -> Tesla K80 (GPU1) : Yes
> Peer access from Tesla K80 (GPU0) -> Tesla K80 (GPU2) : No
> Peer access from Tesla K80 (GPU0) -> Tesla K80 (GPU3) : No
> Peer access from Tesla K80 (GPU1) -> Tesla K80 (GPU0) : Yes
> Peer access from Tesla K80 (GPU1) -> Tesla K80 (GPU2) : No
> Peer access from Tesla K80 (GPU1) -> Tesla K80 (GPU3) : No
> Peer access from Tesla K80 (GPU2) -> Tesla K80 (GPU0) : No
> Peer access from Tesla K80 (GPU2) -> Tesla K80 (GPU1) : No
> Peer access from Tesla K80 (GPU2) -> Tesla K80 (GPU3) : Yes
> Peer access from Tesla K80 (GPU3) -> Tesla K80 (GPU0) : No
> Peer access from Tesla K80 (GPU3) -> Tesla K80 (GPU1) : No
> Peer access from Tesla K80 (GPU3) -> Tesla K80 (GPU2) : Yes
deviceQuery, CUDA Driver = CUDART, CUDA Driver Version = 10.0, CUDA Runtime Version = 10.0, NumDevs = 4
Result = PASS
8 测试cudnn
cd /usr/src/cudnn_samples_v7/mnistCUDNN
sudo make clean
sudo make
./mnistCUDNN
返回结果:
cudnnGetVersion() : 7401 , CUDNN_VERSION from cudnn.h : 7401 (7.4.1)
Host compiler version : GCC 5.5.0
There are 4 CUDA capable devices on your machine :
device 0 : sms 13 Capabilities 3.7, SmClock 823.5 Mhz, MemSize (Mb) 11441, MemClock 2505.0 Mhz, Ecc=1, boardGroupID=0
device 1 : sms 13 Capabilities 3.7, SmClock 823.5 Mhz, MemSize (Mb) 11441, MemClock 2505.0 Mhz, Ecc=1, boardGroupID=0
device 2 : sms 13 Capabilities 3.7, SmClock 823.5 Mhz, MemSize (Mb) 11441, MemClock 2505.0 Mhz, Ecc=1, boardGroupID=2
device 3 : sms 13 Capabilities 3.7, SmClock 823.5 Mhz, MemSize (Mb) 11441, MemClock 2505.0 Mhz, Ecc=1, boardGroupID=2
Using device 0
Testing single precision
Loading image data/one_28x28.pgm
Performing forward propagation ...
Testing cudnnGetConvolutionForwardAlgorithm ...
Fastest algorithm is Algo 2
Testing cudnnFindConvolutionForwardAlgorithm ...
^^^^ CUDNN_STATUS_SUCCESS for Algo 1: 0.043840 time requiring 100 memory
^^^^ CUDNN_STATUS_SUCCESS for Algo 0: 0.047456 time requiring 0 memory
^^^^ CUDNN_STATUS_SUCCESS for Algo 2: 0.105408 time requiring 57600 memory
^^^^ CUDNN_STATUS_SUCCESS for Algo 4: 0.179744 time requiring 207360 memory
^^^^ CUDNN_STATUS_SUCCESS for Algo 5: 0.343424 time requiring 203008 memory
Resulting weights from Softmax:
0.0000000 0.9999399 0.0000000 0.0000000 0.0000561 0.0000000 0.0000012 0.0000017 0.0000010 0.0000000
Loading image data/three_28x28.pgm
Performing forward propagation ...
Resulting weights from Softmax:
0.0000000 0.0000000 0.0000000 0.9999288 0.0000000 0.0000711 0.0000000 0.0000000 0.0000000 0.0000000
Loading image data/five_28x28.pgm
Performing forward propagation ...
Resulting weights from Softmax:
0.0000000 0.0000008 0.0000000 0.0000002 0.0000000 0.9999820 0.0000154 0.0000000 0.0000012 0.0000006
Result of classification: 1 3 5
Test passed!
Testing half precision (math in single precision)
Loading image data/one_28x28.pgm
Performing forward propagation ...
Testing cudnnGetConvolutionForwardAlgorithm ...
Fastest algorithm is Algo 2
Testing cudnnFindConvolutionForwardAlgorithm ...
^^^^ CUDNN_STATUS_SUCCESS for Algo 1: 0.038560 time requiring 100 memory
^^^^ CUDNN_STATUS_SUCCESS for Algo 0: 0.042656 time requiring 0 memory
^^^^ CUDNN_STATUS_SUCCESS for Algo 2: 0.084736 time requiring 28800 memory
^^^^ CUDNN_STATUS_SUCCESS for Algo 4: 0.156704 time requiring 207360 memory
^^^^ CUDNN_STATUS_SUCCESS for Algo 5: 0.351232 time requiring 203008 memory
Resulting weights from Softmax:
0.0000001 1.0000000 0.0000001 0.0000000 0.0000563 0.0000001 0.0000012 0.0000017 0.0000010 0.0000001
Loading image data/three_28x28.pgm
Performing forward propagation ...
Resulting weights from Softmax:
0.0000000 0.0000000 0.0000000 1.0000000 0.0000000 0.0000714 0.0000000 0.0000000 0.0000000 0.0000000
Loading image data/five_28x28.pgm
Performing forward propagation ...
Resulting weights from Softmax:
0.0000000 0.0000008 0.0000000 0.0000002 0.0000000 1.0000000 0.0000154 0.0000000 0.0000012 0.0000006
Result of classification: 1 3 5
Test passed!
参考链接:
Ubuntu 18.04 将gcc版本降级为5.5版本
【解决】Ubuntu安装NVIDIA驱动(咨询NVIDIA工程师的解决方案)