TCPIP协议族学习笔记(四):HTTP
TCP/IP协议族学习笔记(四)
一、体系结构
1.1 统一资源定位符(URL)
客户要访问Web页面就需要文件名称和地址。为了方便地访问世界范围内的文档,HTTP使用定位符。URL是在因特网上指明任何种类的信息的标准。URL定义了4样东西:协议、主机、端口和路径。

协议是客户-服务器程序,用来读取文档。许多不同的协议可用来读取文档,其中最常用的是HTTP。
主机是信息所存放的地点的域名。Web页面通常存放在计算机上,而这个计算机通常使用以字符www开始的域名别名。但这不是强制性的,因为主机可以使用任何域名。
URL可以有选择地包含服务器的端口号。如果包含了端口,那么端口就插入在主机和路径之间,和主机用冒号分隔开。
路径是信息存放的路径名。路径本身可以包含斜线。
二、HTTP
超文本传送协议(HTTP)是主要用在万维网上存取数据的协议。HTTP在80端口上使用TCP的服务。
2.1 HTTP特点
1、简单快速:客户向服务器请求服务时,只需传送请求方法和路径。由于HTTP协议简单,使得HTTP服务器的程序规模小,因而通信速度很快。
2、灵活:HTTP允许传输任意类型的数据对象。正在传输的类型由Content-Type加以标记。
3、无状态:HTTP协议是无状态协议。无状态是指协议对于事务处理没有记忆能力。缺少状态意味着如果后续处理需要前面的信息,则它必须重传,这样可能导致每次连接传送的数据量增大。另一方面,在服务器不需要先前信息时它的应答就较快。
2.2 HTTP事务
客户发送请求报文初始化事务,服务器也发送响应进行回答。 一次HTTP操作称为一个事务,其工作过程可分为四步:
1.首先客户机与服务器需要建立连接。只要单击某个超级链接,HTTP的工作开始。
2.建立连接后,客户机发送一个请求给服务器,请求方式的格式为:统一资源标识符(URL)、协议版本号,后边是MIME信息包括请求修饰符、客户机信息和可能的内容。
3.服务器接到请求后,给予相应的响应信息,其格式为一个状态行,包括信息的协议版本号、一个成功或错误的代码,后边是MIME信息包括服务器信息、实体信息和可能的内容。
4.客户端接收服务器所返回的信息通过浏览器显示在用户的显示屏上,然后客户机与服务器断开连接。
如果在以上过程中的某一步出现错误,那么产生错误的信息将返回到客户端,由显示屏输出。对于用户来说,这些过程是由HTTP自己完成的,用户只要用鼠标点击,等待信息显示就可以了。
2.2.1请求报文
请求报文格式如下所示。请求报文包括一个请求行、一个首部,有时候还有一个主体。
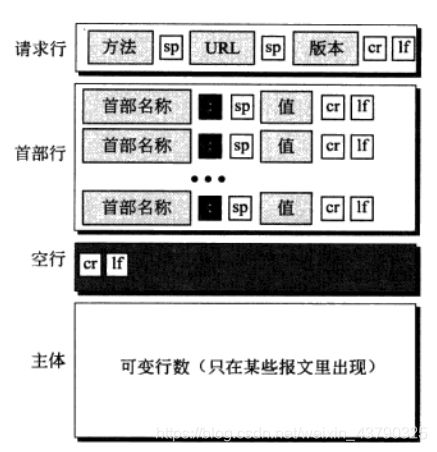
请求行:
在请求报文的第一行是请求行;请求行一共有三个字段,这三个字段分别称为方法、URL和版本。它们以空格符为分隔。在该行最后,以回车和换行这两个字符为结束。方法字段定义了请求类型。在HTTP版本1.1中定义了几种方法,如下所示。

请求报文首部行:
在请求行之后,可以有0到多个请求首部行。每个首部行从客户向服务器发送附加信息。例如,客户可以向服务器请求文档要以某种特殊格式发送。首部可以有一个或多个首部行。每一个首部行由一个首部名,一个冒号,一个空格和一个首部值组成。常见首部名如下

请求报文实体:
实体可以出现在请求报文中。请求报文的实体部分通常是一些需要发送的备注信息。
2.2.2 响应报文:
响应报文的格式如下所示。响应报文包含一个状态行,一些首部行、一个空行,有时也包含一个实体。
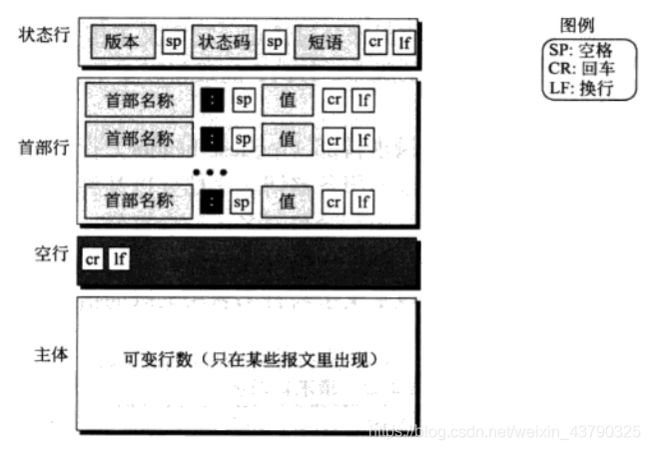
状态行:
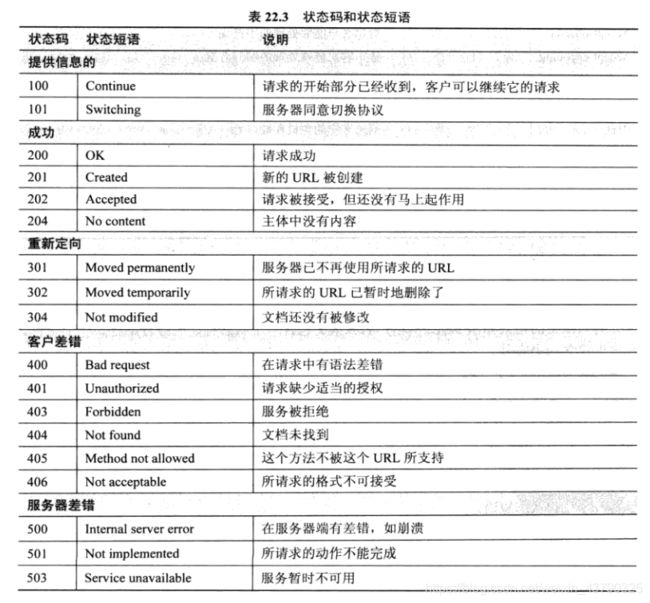
响应报文的第一行被称为状态行。该行共有三个字段,第一个字段定义HTTP协议的版本。状态码字段定义了请求的状态。它由3个数字组成。100系列的代码代码指示提供信息,200系列的代码则指示成功的请求。300系列代码是把客户重新定向到另一个URL,400系列代码指示在客户端的差错。最后500系列代码指示在服务器的差错。常用状态码如下:
响应报文的首部行:
在状态行之后,可以有0到多个响应首部行。每个首部行从服务器向客户发送附加信息。每一个首部行由一个首部名,一个冒号,一个空格和一个首部值组成。常见首部名如下

主体:主体包含从服务器向客户发送的文档。如果响应不是错误报文,则主体将出现在响应报文中
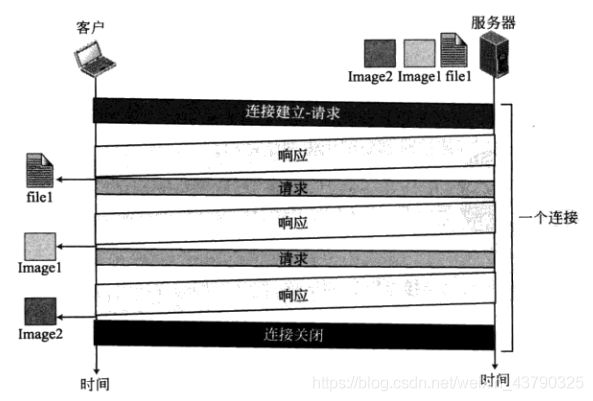
2.3 持续连接
在版本1.1以前的HTTP指明的是非持续连接,而在版本1.1中,持续连接是默认的连接。
在使用持续连接时,服务器在发送响应后,让连接继续打开以服务更多的请求。服务器可以在客户请求时或超时的时限到时关闭这个连接。发送端通常在每一个响应中都发送数据的长度。但是,在某些情况下,发送端并不知道数据的长度。当文档是动态文档或活动文档时就属于这些情况。在这些情况下,服务器把长度未知这件事通知客户,并在发送数据后关闭 这个连接,因此客户就知道数据结束的地方到了。
2.4 Cookie
2.4.1 Cookie的创建和存储
1.当服务器收到来自客户的请求后,它就把有关客户的信息存储在一个文件或字符串中。这个信息可以包含客户的域名、Cookie的内容(服务器已经收集到的客户信息,如名字、注册号等等)、时间戳,以及其他与实现有关的信息。
2.服务器向客户发送的响应包含这个Cookie。
3.当客户受到响应时,浏览器把这个Cookie存储在Cookie目录中,它是按照域名服务器的名字来分类的。
2.4.2 Cookie的使用
当一个客户向服务器发送请求时,浏览器就查找在Cookie目录中是否有那个服务器发送的Cookie。如果找到了,就把这个Cookie包含在请求中。当服务器收到这个请求时,它就知道这是一个老客户,而不是一个新客户。注意,这个Cookie的内容从来没有被浏览器读过,也没有暴露给用户。Cookie是服务器制作的,也是被服务器吃掉的。
2.5 HTTP1.1和HTTP2.0的区别
**1. 多路复用 **
HTTP1.1中,若干个请求排队串行化单线程处理,后面的请求等待前面请求的返回才能获得执行机会,一旦有某请求超时等,后续请求只能被阻塞,毫无办法。
HTTP2.0中多个请求可以同时在一个连接上并行执行,某个请求任务耗时严重,不会影响其他连接的正常执行。

2. 二进制分帧
HTTP1.x的解析是基于文本。基于文本协议的格式解析存在天然缺陷,文本的表现形式有多样性,要做到健壮性考虑的场景必然很多,二进制则不同,只认0和1的组合。基于这种考虑HTTP2.0的协议解析决定采用二进制格式,实现方便且健壮。
3. 首部压缩
HTTP1.x的header带有大量信息,而且每次都要重复发送,HTTP2.0使用encoder来减少需要传输的header大小,通讯双方各自cache一份header fields表,既避免了重复header的传输,又减小了需要传输的大小。
4. 服务端推送
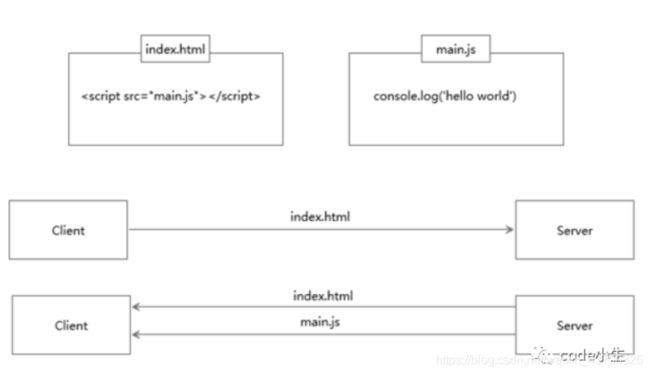
服务端推送能把客户端所需要的资源伴随着index.html一起发送到客户端,省去了客户端重复请求的步骤。正因为没有发起请求,建立连接等操作,所以静态资源通过服务端推送的方式可以极大地提升速度。具体如下:
普通的客户端请求过程:

服务端推送的过程: