基于Huffman和LZ77的压缩(四)LZ77压缩原理分析
点我查看上一篇
上一篇分析中,我们遇到了两个问题:
问题1: 64K的哈希表必然存在哈希冲突
问题2: 大于64K的文件仍无法进行压缩
下面我们来接着探索分析:
为什么给32K的查找缓冲区Head?
为什么给32K个位置,理论计算为 2^24个才能计算完这些组合呀,那这样必然存在哈希冲突,那么LZ77怎么解决冲突?
我们先不考虑大于64K的文件
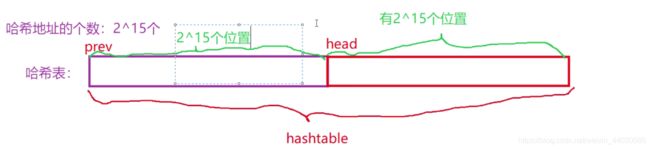
将哈希表分为2部分 Prev和Head
Prev空间专门解决哈希冲突,第一个地址的下标先存在prev【addr】
Head存放当前待匹配链的头的下标,出现过即存在 冲突
哈希冲突具体怎么解决
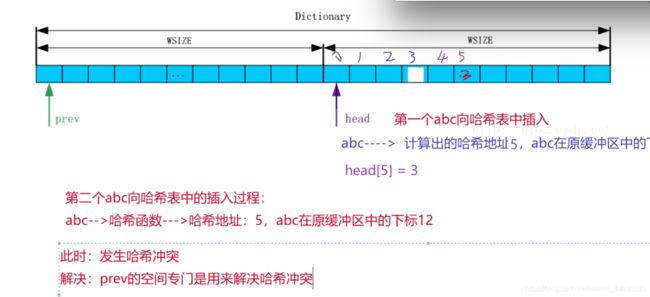
下面这张图诠释了发生哈希冲突的做法
:1 将当前位置保存在哈希函数计算出来的Head下标位置
2 该位置若为0 ,则直接放入
3 该位置若非0 ,则存在冲突,接着向前找最远的距离,并将地址的指向依次更改。

那么大于64K的文件,必然会破坏原有的链的指向
64K以上的文件下标大于2个字节的存储范围了
取出的字符串的首字母的下标大于prev的最大空间,岂不是越界了,那怎么办?
处理方式将 pos & (pos-1)
pos & (pos-1)
pos-1 称为掩码Vmask
引入新问题:
Pos & Vmask虽然能解决越界问题,但却引入了新问题。当文件大于64K时可能破坏原有环链而形成死循环。
注意:此处的链指的是下标关系形成的指向。我们称为链。
1形成环状链

环状链肯定会在查找时形成死循环。
怎么解决死循环?
设置最大匹配次数为255,再多默认找不到了,放弃本次匹配,为什么设置255,再长就说明距离太远了
问题2 :搭到别的链上
这种情况发生后, 下一次相同串到时候也找不到,那么到时候会将该字符串计算出来地址 ,直接插入到哈希表中就可。
假设 待压缩文件大小超过64K,则不能一次将其加载到程序缓冲区中:
因为每次可以匹配的最大字符串的长度为255, 当当前剩余的带匹配的字符串不足255时,另一部分文件还未加载到缓冲区中,则本次匹配暂时不进行,即 :线性缓冲区中剩余数据到一定数量时暂不进行匹配 :
MIN_LOOKAHEAD >= MAX_MATCH + 1
即先行缓冲区中剩余字符大于258
MAX_MATCH 是为了能够保证本次匹配能够达到最大258
为什么 + 1:+1 是为了保证完本词匹配后,还能保证下次匹配

当匹配暂停时(先行缓冲区中剩余的数据不能给保证本次匹配到最大长度+和下次匹配开始)
1 将WSIZE2 中的数据 导入(memcpy)到WSIZE1中
2 再从文件向WSIZE2(先行缓冲区)中接着加载数据
3 更新哈希表(之前的匹配数据实效),此时真正的匹配距离不是WSIZE,而是 WSIZE - LOOKAHEAD。
开始压缩
从文件中每次读取然后一句哈希函数计算哈希地址,插入即可,遇到冲突则进行冲突处理。
直到压缩进行结束。
存在问题:压缩的时候能进行,那么如何解压缩?
换句话说:解压缩时,怎么知道是原字符串还是压缩后的长度距离对呢?
遇到凡事不要慌~
我们在压缩文件的时候制作一份标记文件即可。
什么是标记文件?
将原有的字符每次写入标记为0,而替换成的长度距离对我们将其标记为1
那么就是说标记文件到时候就是一串0101010的数字。
我们又想到了位图,节省空间还很巧妙。
位图的思想:将原文件与压缩后的长度距离对标记为 每个比特位存1个字符串
在解压缩时:
遇到0,便直接获取
遇到1,则知道是长度距离对了,则向前查找,第一字节是长度,接下来2-3字节是距离,
获取距离后
获取长度
就可以找到原串的样子,便可以解压缩了。
两个文件的合并:
交给用户时我们应该给一份压缩文件就行了,所以应该将标记文件和压缩文件进行合并:
所以我们还应该应该将标记文件写入到压缩文件中去。
写入时在文件默认加上原文件的大小,可以防止解压缩出现细小的差异。
小结:
当前虽然解决了哈希冲突的问题 ,
但是对于大于64K的文件,还是不能进行压缩,下一篇我们再来解决
点我跳转至最后一篇