【目标检测系列】CNN中的目标多尺度处理方法
关注上方“深度学习技术前沿”,选择“星标公众号”,
技术干货,第一时间送达!

【导读】本篇博文我们一起来讨论总结一下目标检测任务中用来处理目标多尺度的一些算法。视觉任务中处理目标多尺度主要分为两大类:
图像金字塔:经典的基于简单矩形特征(Haar)+级联Adaboost与Hog特征+SVM的DPM目标识别框架,均使用图像金字塔的方式处理多尺度目标,早期的CNN目标识别框架同样采用该方式,在image pyramid中,我们直接对图像进行不同尺度的缩放,然后将这些图像直接输入到detector中去进行检测。虽然这样的方法十分简单,但其效果仍然是最佳。特别地,随着图像金字塔尺度归一化(SNIP)的出现,解决了小目标和大目标在小尺度和大尺度下难以识别的问题。而且SNIP在COCO数据集上,AP最高可以达到48.3%,并且赢得了COCO2017挑战赛的“Best Student Entry”。基于SNIP后续便衍生出了一系列基于图像金字塔的多尺度处理。
特征金字塔:最具代表性的工作便是经典的FPN了,FPN网络通过将不同层的优势结合,使得每一层相比原来都有更丰富的语义特征和分辨率信息。这一类方法的思想是直接在feature层面上来近似image pyramid。
两者对比分析:image pyramid在测试时使用,会大大增加内存和计算复杂性,效率急剧下降。feature pyramid占用的内存和计算成本更少,而且便于嵌入到各类现有的检测算法中。
目标检测中存在不同目标实例之间的尺度跨度非常大,在多尺度的物体中,大尺度的物体由于面积大、特征丰富,通常来讲较为容易检测。难度较大的主要是小尺度的物体,而这部分小物体在实际工程中却占据了较大的比例。通常认为绝对尺寸小于32×32的物体,可以视为小物体或者物体宽高是原图宽高的1/10以下,可以视为小物体。
小物体由于其尺寸较小,可利用的特征有限,这使得其检测较为困难。当前的检测算法对于小物体并不友好,体现在以下4个方面:
过大的下采样率:假设当前小物体尺寸为15×15,一般的物体检测中卷积下采样率为16,这样在特征图上,过大的下采样率使得小物体连一个像素点都占据不到。
过大的感受野:在卷积网络中,特征图上特征点的感受野比下采样率大很多,导致在特征图上的一个点中,小物体占据的特征更少,会包含大量周围区域的特征,从而影响其检测结果。
语义与空间的矛盾:当前检测算法,如Faster RCNN,其Backbone大都是自上到下的方式,深层与浅层特征图在语义性与空间性上没有做到更好的均衡。
SSD一阶算法缺乏特征融合:SSD虽然使用了多层特征图,但浅层的特征图语义信息不足,没有进行特征的融合,致使小物体检测的结果较差。
多尺度的检测能力实际上体现了尺度的不变性,当前的卷积网络能够检测多种尺度的物体,很大程度上是由于其本身具有超强的拟合能力。
较为通用的提升多尺度检测的经典方法有:
降低下采样率与空洞卷积可以显著提升小物体的检测性能;
设计更好的Anchor可以有效提升Proposal的质量;
多尺度的训练可以近似构建出图像金字塔,增加样本的多样性;
特征融合可以构建出特征金字塔,将浅层与深层特征的优势互补。
接下来,我们主要将主要介绍U-shape/V-shape型多尺度处理、SNIP、TridentNet、FPN这四大多尺度解决方法。
U-shape/V-shape型多尺度处理
这种方式有点类似U-Net的结构,通过采用对称的encoder-decoder结构,将高层特征逐渐与低层特征融合,这样的操作类似于将多个感受野进行混合,使得输出的多尺度信息更为丰富;Face++团队在2018年COCO比赛上,在backbone最后加入gpooling操作,获得理论上最大的感受野,类似于V-shape结构,结果证明确实有效。该方法虽然比SSD的单层输出多尺度信息相比更好,但其也存在问题:
由于decoder使用的通道数与encoder相同,导致了大量的计算量;
上采样结构不可能完全恢复已经丢失的信息;
SNIP

论文地址:https://arxiv.org/abs/1711.08189
代码地址:https://github.com/mahyarnajibi/SNIPER
motivation和创新点
用ImageNet预训练的模型在迁移到COCO数据集中时很可能产生一定的domain-shift偏差,什么是domain-shift呢?简单来说,ImageNet 是用来图像分类的,目标一般 scale 比较大,而 object detection 数据集中的目标的 scale 跨度很大。在 ImageNet 这种大目标数据集上 预训练的特征,如果直接用在检测那些小目标,这些特征是不能很好地匹配和对齐的,效果并不会很好,这就是 domain-shift 造成的。这篇论文首先分析了小尺度与预训练模型尺度之间的关系,作者认为要解决domian-shift问题,就要让输入分布接近模型预训练的分布,基于图像金字塔,提出了一种尺度归一化的训练机制,称为SNIP(Scale-Normalization for Image Pyramids)。
该论文的主要贡献在于:
(1)通过实验验证了upsampling对提高小目标检测的效果
(2)提出了一种Scale Normalization for Image Pyramids的方法
(3)提出一个思想:即要让输入的分布接近预训练模型的分布
SNIP的网络结构如下图所示:

具体的设计和实现细节:
(1)3个尺度分别拥有各自的RPN模块,并且各自预测指定范围内的物体。最后不同分支的proposal进行汇总。
(2)由于图像金字塔的应用,对于大尺度(高分辨率)的feature map,对应的RPN只负责预测被放大的小目标;对于小尺度(低分辨率)的feature map,对应的RPN只负责预测被缩小的大目标。这样真实的物体尺度分布在较小的区间内,避免了极大或者极小的物体。
(3)在RPN阶段,如果真实物体不在该RPN预测范围内,会被判定为无效,并且与该无效物体的IoU大于0.3的Anchor也被判定为无效的Anchor。
(4)在训练时,只对有效的Proposal进行反向传播。在测试阶段,对有效的预测Boxes先缩放到原图尺度,利用Soft NMS将不同分辨率的预测结果合并。
(5)实现时SNIP采用了可变形卷积的卷积方式,并且为了降低对于GPU的占用,将原图随机裁剪为1000×1000大小的图像。
总体来说,SNIP是多尺度训练(Multi-Scale Training)的改进版本。SNIP让模型更专注于物体本身的检测,剥离了多尺度的学习难题。在网络搭建时,SNIP也使用了类似于MST的多尺度训练方法,构建了3个尺度的图像金字塔。MST的思想是使用随机采样的多分辨率图像使检测器具有尺度不变特性。然而作者通过实验发现,在MST中,对于极大目标和过小目标的检测效果并不好,但是MST也有一些优点,比如对一张图片会有几种不同分辨率,每个目标在训练时都会有几个不同的尺寸,那么总有一个尺寸在指定的尺寸范围内。SNIP的做法是只对size在指定范围内的目标回传损失,即训练过程实际上只是针对某些特定目标进行,这样就能减少domain-shift带来的影响。
TridentNet

论文地址:https://arxiv.org/abs/1901.01892
代码地址:https://github.com/TuSimple/simpledet/tree/master/models/tridentnet
motivation和创新点
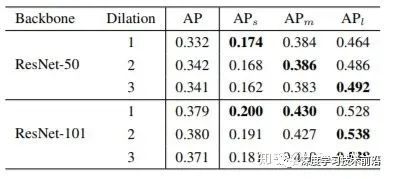
对于一个detector本身而言,影响backbone的主要有以下三个因素:network depth(structure),downsample rate和receptive field。对于网络深度而言,ResNet证明了一般网络越深(网络的表达能力就越强),相应的结果会越好。下采用率方面,由于下采样次数过多对于小物体有负面影响。那么有没有可能单独分离出receptive field,保持其他变量不变,来验证它对detector性能的影响。所以,该论文做了一个验证性实验,分别使用ResNet50和ResNet101作为backbone,改变最后一个stage中每个3*3 conv的dilation rate。通过这样的方法,我们便可以固定同样的网络结构,同样的参数量以及同样的downsample rate,只改变网络的receptive field。我们很惊奇地发现,不同尺度物体的检测性能和dilation rate正相关!也就是说,更大的receptive field对于大物体性能会更好,更小的receptive field对于小物体更加友好。
总结一下,TridentNet主要在原始的backbone上做了以下三点变化:
第一点是构造了不同receptive field的parallel multi-branch,3个不同的分支使用了空洞数不同的空洞卷积,感受野由小到大,可以更好地覆盖多尺度的物体分布。
第二点是对于trident block中每一个branch的weight是share的。这样既充分利用了样本信息,学习到更本质的目标检测信息,也减少了参数量与过拟合的风险。
第三点是对于每个branch,借鉴了SNIP的思想,训练和测试都只负责一定尺度范围内的样本,也就是所谓的scale-aware。避免了过大与过小的样本对于网络参数的影响。
 TridentNet网络结构
TridentNet网络结构
论文中还做了非常详尽的ablation analyses,包括有几个branch性能最好;trident block应该加在网络的哪个stage;trident block加多少个性能会饱和。这些就不展开在这里介绍了,有兴趣的读者可以参照原文。
FPN
论文地址:https://arxiv.org/abs/1612.03144
代码地址:https://github.com/jwyang/fpn.pytorch
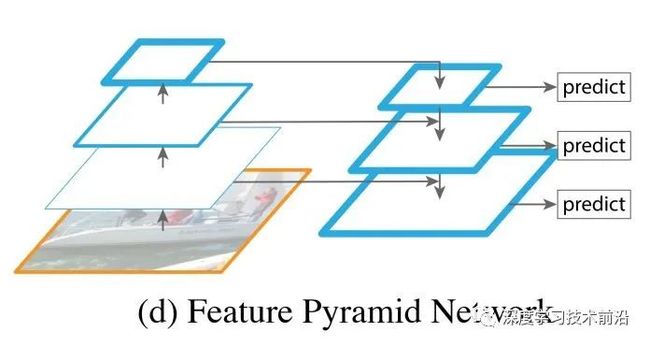
FPN将深层信息上采样,与浅层信息逐元素地相加,从而构建了尺寸不同的特征金字塔结构,性能优越,FPN如今已成为Detecton算法的标准组件,不管是one-stage(RetinaNet、DSSD)、two-stage(Faster R-CNN、Mask R-CNN)还是four-stage(Cascade R-CNN)都可用;
如下图所示,FPN把低分辨率、高语义信息的高层特征和高分辨率、低语义信息的低层特征进行自上而下的侧边连接,使得所有尺度下的特征都有丰富的语义信息。

算法结构可以分为三个部分:自下而上的卷积神经网络(上图左),自上而下过程(上图右)和特征与特征之间的侧边连接。
自下而上:最左侧为卷积神经网络的前向过程,这里默认使用ResNet结构,用作提取语义信息。在前向过程中,特征图的大小在经过某些层后会改变,而在经过其他一些层的时候不会改变,作者将不改变特征图大小的层归为一个阶段,因此每次抽取的特征都是每个阶段的最后一个层的输出,这样就能构成特征金字塔。具体来说,对于ResNets,作者使用了每个阶段的最后一个残差结构的特征激活输出。将这些残差模块输出表示为{C2, C3, C4, C5},对应于conv2,conv3,conv4和conv5的输出。

自上而下:首先对C5进行1×1卷积降低通道数,然后依次进行上采样。上采样几乎都是采用内插值方法,即在原有图像像素的基础上在像素点之间采用合适的插值算法插入新的元素,从而扩大原图像的大小。通过对特征图进行上采样,使得上采样后的特征图具有和下一层的特征图相同的大小。
横向连接(Lateral Connection):目的是为了将上采样后的高语义特征与浅层的定位细节特征进行融合。根本上来说,是将上采样的结果和自下而上生成的特征图进行融合。我们将卷积神经网络中生成的对应层的特征图进行1×1的卷积操作,将之与经过上采样的特征图融合,得到一个新的特征图,这个特征图融合了不同层的特征,具有更丰富的信息。这里1×1的卷积操作目的是改变channels,要求和后一层的channels相同。在融合之后还会再采用3*3的卷积核对每个融合结果进行卷积,目的是消除上采样的混叠效应,如此就得到了一个新的特征图。这样一层一层地迭代下去,就可以得到多个新的特征图。假设生成的特征图结果是P2,P3,P4,P5,它们和原来自底向上的卷积结果C2,C3,C4,C5一一对应。金字塔结构中所有层级共享分类层(回归层)。
卷积融合:在得到相加后的特征后,利用3×3卷积对生成的P2至P4再进行融合,目的是消除上采样过程带来的重叠效应,以生成最终的特征图。
FPN对于不同大小的RoI,使用不同的特征图,大尺度的RoI在深层的特征图上进行提取,小尺度的RoI在浅层的特征图上进行提取。FPN的代码实现如下:
# Build the shared convolutional layers.
# Bottom-up Layers
# Returns a list of the last layers of each stage, 5 in total.
# 扔掉了C1
_, C2, C3, C4, C5 = resnet_graph(input_image, "resnet101", stage5=True)
# Top-down Layers
# TODO: add assert to varify feature map sizes match what's in config
P5 = KL.Conv2D(256, (1, 1), name='fpn_c5p5')(C5) # C5卷积一下就当做P5
P4 = KL.Add(name="fpn_p4add")([ # P4 开始有了对应元素add操作
KL.UpSampling2D(size=(2, 2), name="fpn_p5upsampled")(P5),
KL.Conv2D(256, (1, 1), name='fpn_c4p4')(C4)])
P3 = KL.Add(name="fpn_p3add")([
KL.UpSampling2D(size=(2, 2), name="fpn_p4upsampled")(P4),
KL.Conv2D(256, (1, 1), name='fpn_c3p3')(C3)])
P2 = KL.Add(name="fpn_p2add")([
KL.UpSampling2D(size=(2, 2), name="fpn_p3upsampled")(P3),
KL.Conv2D(256, (1, 1), name='fpn_c2p2')(C2)])
# Attach 3x3 conv to all P layers to get the final feature maps.
P2 = KL.Conv2D(256, (3, 3), padding="SAME", name="fpn_p2")(P2)
P3 = KL.Conv2D(256, (3, 3), padding="SAME", name="fpn_p3")(P3)
P4 = KL.Conv2D(256, (3, 3), padding="SAME", name="fpn_p4")(P4)
P5 = KL.Conv2D(256, (3, 3), padding="SAME", name="fpn_p5")(P5)
# P6 is used for the 5th anchor scale in RPN. Generated by
# subsampling from P5 with stride of 2.
# P6是P5的极大值池化
P6 = KL.MaxPooling2D(pool_size=(1, 1), strides=2, name="fpn_p6")(P5)
# Note that P6 is used in RPN, but not in the classifier heads.
rpn_feature_maps = [P2, P3, P4, P5, P6]
mrcnn_feature_maps = [P2, P3, P4, P5]优缺点分析:
底层feature map位置信息多但语义信息少,FPN为其增强了语义信息,提升了对小物体的检测效果;
提升检测精度,包括加强对小物体的检测效果和对大物体的检测效果。一般来说,顶层feature map是检测大物体的关键,因为容易框出大物体;底层feature map是检测小物体的关键,因为容易框出小物体;
FPN只是给底层featue map提供了福利,所以仅仅提升了对小物体的检测效果;
顶层feature map语义信息多但位置信息少,还是对检测大物体不利。后来者PAN在FPN的基础上再加了一个bottom-up方向的增强,使得顶层feature map也可以享受到底层带来的丰富的位置信息,从而把大物体的检测效果也提上去了。
参考链接:
https://zhuanlan.zhihu.com/p/70523190
https://zhuanlan.zhihu.com/p/54334986
https://zhuanlan.zhihu.com/p/74415602
https://zhuanlan.zhihu.com/p/61536443
https://blog.csdn.net/weixin_40683960/article/details/79055537
推荐阅读:
干货|最全面的卷积神经网络入门教程
【CV中的Attention机制】基础篇-视觉注意力机制和SENet
Yolov3&Yolov4核心基础知识完整讲解
【目标检测基础积累】常用的评价指标
一文详解深度学习中的Normalization:BN/LN/WN
深度思考:从头开始训练目标检测
重磅!DLer-目标检测交流群已成立!
为了能给大家提供一个更好的交流学习平台!针对特定研究方向,我建立了目标检测微信交流群,目前群里已有百余人!本群旨在交流目标检测、密集人群检测、关键点检测、人脸检测、人体姿态估计等内容。
进群请备注:研究方向+地点+学校/公司+昵称(如目标检测+上海+上交+小明)

???? 长按识别添加,邀请您进群!
原创不易,在看鼓励!比心哟!
