Lucene基本使用和代码实现
目录
Lucene:全文检索技术
一、Lucene的介绍
1.1背景
1.2优点
1.3Lucene的缺点
1.4全文检索
二、Lucene的基本使用流程
2.1Lucene检索过程
2.2获取文档
2.3分析文档(分词)
2.4创建索引
2.5查询索引
三、Lucene具体实现
3.1下载
3.2实际开发要使用的jar包
3.3代码实现
3.4使用Luke工具查看索引文件
3.5分析器
3.6索引库的维护(增删改)
Lucene:全文检索技术
一、Lucene的介绍
1.1背景
Lucene是apache软件基金会4 jakarta项目组的一个子项目,是一个开放源代码的全文检索引擎工具包,但它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎,部分文本分析引擎(英文与德文两种西方语言)。Lucene的目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能,或者是以此为基础建立起完整的全文检索引擎。Lucene是一套用于全文检索和搜寻的开源程式库,由Apache软件基金会支持和提供。Lucene提供了一个简单却强大的应用程式接口,能够做全文索引和搜寻。在Java开发环境里Lucene是一个成熟的免费开源工具。就其本身而言,Lucene是当前以及最近几年最受欢迎的免费Java信息检索程序库。人们经常提到信息检索程序库,虽然与搜索引擎有关,但不应该将信息检索程序库与搜索引擎相混淆。
Lucene['lusen]的原作者是Doug Cutting,他是一位资深全文索引/检索专家,曾经是V-Twin搜索引擎的主要开发者,后在Excite担任高级系统架构设计师,当前从事于一些Internet底层架构的研究。早先发布在作者自己的博客上,他贡献出Lucene的目标是为各种中小型应用程式加入全文检索功能。后来发布在SourceForge,2001年年底成为apache软件基金会jakarta的一个子项目。
1.2优点
作为一个开放源代码项目,Lucene从问世之后,引发了开放源代码社群的巨大反响,程序员们不仅使用它构建具体的全文检索应用,而且将之集成到各种系统软件中去,以及构建Web应用,甚至某些商业软件也采用了Lucene作为其内部全文检索子系统的核心。apache软件基金会的网站使用了Lucene作为全文检索的引擎,IBM的开源软件eclipse[9]的2.1版本中也采用了Lucene作为帮助子系统的全文索引引擎,相应的IBM的商业软件Web Sphere[10]中也采用了Lucene。Lucene以其开放源代码的特性、优异的索引结构、良好的系统架构获得了越来越多的应用。
Lucene是一个高性能、可伸缩的信息搜索(IR)库。它可以为你的应用程序添加索引和搜索能力。Lucene是用java实现的、成熟的开源项目,是著名的Apache Jakarta大家庭的一员,并且基于Apache软件许可 [ASF, License]。同样,Lucene是当前非常流行的、免费的Java信息搜索(IR)库。
(1)索引文件格式独立于应用平台。Lucene定义了一套以8位字节为基础的索引文件格式,使得兼容系统或者不同平台的应用能够共享建立的索引文件。
(2)在传统全文检索引擎的倒排索引的基础上,实现了分块索引,能够针对新的文件建立小文件索引,提升索引速度。然后通过与原有索引的合并,达到优化的目的。
(3)优秀的面向对象的系统架构,使得对于Lucene扩展的学习难度降低,方便扩充新功能。
(4)设计了独立于语言和文件格式的文本分析接口,索引器通过接受Token流完成索引文件的创立,用户扩展新的语言和文件格式,只需要实现文本分析的接口。
(5)已经默认实现了一套强大的查询引擎,用户无需自己编写代码即可使系统可获得强大的查询能力,Lucene的查询实现中默认实现了布尔操作、模糊查询(Fuzzy Search[11])、分组查询等等。
面对已经存在的商业全文检索引擎,Lucene也具有相当的优势。
首先,它的开发源代码发行方式(遵守Apache Software License[12]),在此基础上程序员不仅仅可以充分的利用Lucene所提供的强大功能,而且可以深入细致的学习到全文检索引擎制作技术和面向对象编程的实践,进而在此基础上根据应用的实际情况编写出更好的更适合当前应用的全文检索引擎。在这一点上,商业软件的灵活性远远不及Lucene。
其次,Lucene秉承了开放源代码一贯的架构优良的优势,设计了一个合理而极具扩充能力的面向对象架构,程序员可以在Lucene的基础上扩充各种功能,比如扩充中文处理能力,从文本扩充到HTML、PDF[13]等等文本格式的处理,编写这些扩展的功能不仅仅不复杂,而且由于Lucene恰当合理的对系统设备做了程序上的抽象,扩展的功能也能轻易的达到跨平台的能力。
最后,转移到apache软件基金会后,借助于apache软件基金会的网络平台,程序员可以方便的和开发者、其它程序员交流,促成资源的共享,甚至直接获得已经编写完备的扩充功能。最后,虽然Lucene使用Java语言写成,但是开放源代码社区的程序员正在不懈的将之使用各种传统语言实现(例如.net framework[14]),在遵守Lucene索引文件格式的基础上,使得Lucene能够运行在各种各样的平台上,系统管理员可以根据当前的平台适合的语言来合理的选择。
1.3Lucene的缺点
1、Lucene 的内建不支持群集。 Lucene是作为嵌入式的工具包的形式出现的,在核心代码上没有提供对群集的支持。实现对Lucene的群集有三种方式:1、继承实现一个 Directory;2、使用Solr 3、使用 Nutch+Hadoop;使用Solr你不得不用他的Index Server ,而使用Nutch你又不得不集成抓取的模块;
2、区间范围搜索速度非常缓慢; Lucene的区间范围搜索,不是一开始就提供的是后来才加上的。对于在单个文档中term出现比较多的情况,搜索速度会变得很慢。因此作者称Lucene是一个高效的全文搜索引擎,其高效仅限于提供基本布尔查询 boolean queries; 3、排序算法的实现不是可插拔的;
因为贯穿Lucene的排序算法的tf/idf 的实现,尽管term是可以设置boost或者扩展Lucene的Query类,但是对于复杂的排序算法定制还是有很大的局限性; 4、Lucene的结构设计不好; Lucene的OO设计的非常糟,尽管有包package和类class,但是Lucene的设计基本上没有设计模式的身影。这是不是c或者c++程序员写java程序的通病? A、Lucene中没有使用接口Interface,比如Query 类( BooleanQuery, SpanQuery, TermQuery...) 大都是从超类中继承下来的; B、Lucene的迭代实现不自然: 没有hasNext() 方法, next() 返回一个布尔值 boolean然后刷新对象的上下文; 5、封闭设计的API使得扩展Lucene变得很困难; 参考第3点; 6、Lucene的搜索算法不适用于网格计算;
1.4全文检索
1.4.1数据分类
我们生活中的数据总体分为两种:结构化数据和非结构化数据。
结构化数据:指具有固定格式或有限长度的数据,如数据库,元数据等。
非结构化数据:指不定长或无固定格式的数据,如邮件,word文档等磁盘上的文件。
1.4.2结构化数据搜索
常见的结构化数据也就是数据库中的数据。在数据库中搜索很容易实现,通常都是使用sql语句进行查询,而且能很快的得到查询结果。
为什么数据库搜索很容易?
因为数据库中的数据存储是有规律的,有行有列而且数据格式、数据长度都是固定的。
1.4.3非结构化数据搜索
(1)顺序扫描法
所谓顺序扫描,比如要找内容包含某一个字符串的文件,就是一个文档一个文档的看,对于每一个文档,从头看到尾,如果此文档包含此字符串,则此文档为我们要找的文件,接着看下一个文件,直到扫描完所有的文件。如利用windows的搜索也可以搜索文件内容,只是相当的慢。
(2)全文检索
将非结构化数据中的一部分信息提取出来,重新组织,使其变得有一定结构,然后对此有一定结构的数据进行搜索,从而达到搜索相对较快的目的。这部分从非结构化数据中提取出的然后重新组织的信息,我们称之索引。
例如:字典。字典的拼音表和部首检字表就相当于字典的索引,对每一个字的解释是非结构化的,如果字典没有音节表和部首检字表,在茫茫辞海中找一个字只能顺序扫描。然而字的某些信息可以提取出来进行结构化处理,比如读音,就比较结构化,分声母和韵母,分别只有几种可以一一列举,于是将读音拿出来按一定的顺序排列,每一项读音都指向此字的详细解释的页数。我们搜索时按结构化的拼音搜到读音,然后按其指向的页数,便可找到我们的非结构化数据——也即对字的解释。
这种先建立索引,再对索引进行搜索的过程就叫全文检索(Full-text Search)。
虽然创建索引的过程也是非常耗时的,但是索引一旦创建就可以多次使用,全文检索主要处理的是查询,所以耗时间创建索引是值得的。
1.4.4全文检索应用
对于数据量大、数据结构不固定的数据可采用全文检索方式搜索,比如百度、Google等搜索引擎、论坛站内搜索、电商网站站内搜索等。
二、Lucene的基本使用流程
2.1Lucene检索过程

2.2获取文档
获取原始内容的目的是为了索引,在索引前需要将原始内容创建成文档(Document),文档中包括一个一个的域(Field),域中存储内容。
这里我们可以将磁盘上的一个文件当成一个document,Document中包括一些Field(file_name文件名称、file_path文件路径、file_size文件大小、file_content文件内容),如下图:

注意:每个Document可以有多个Field,不同的Document可以有不同的Field,同一个Document可以有相同的Field(域名和域值都相同)
每个文档都有一个唯一的编号,就是文档id。
2.3分析文档(分词)
将原始内容创建为包含域(Field)的文档(document),需要再对域中的内容进行分析。
分析的过程:
原始文档提取单词、
将字母转为小写、
去除标点符号、
去除停用词
等过程生成最终的语汇单元,可以将语汇单元理解为一个一个的单词。
比如下边的文档经过分析如下:
原文档内容:
Lucene is a Java full-text search engine. Lucene is not a complete
application, but rather a code library and API that can easily be used
to add search capabilities to applications.
分析后得到的语汇单元:
lucene、java、full、search、engine。。。。
每个单词叫做一个Term,不同的域中拆分出来的相同的单词是不同的term。term中包含两部分一部分是文档的域名,另一部分是单词的内容。
例如:文件名中包含apache和文件内容中包含的apache是不同的term。
2.4创建索引
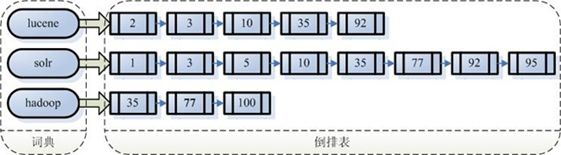
注意:创建索引是对语汇单元索引,通过词语找文档,这种索引的结构叫倒排索引结构。
倒排索引结构也叫反向索引结构,包括索引和文档两部分,索引即词汇表,它的规模较小,而文档集合较大。
传统方法是根据文件找到该文件的内容,在文件内容中匹配搜索关键字,这种方法是顺序扫描方法,数据量大、搜索慢。
倒排索引结构是根据内容(词语)找文档,如下图:
2.5查询索引
Lucene不提供制作用户搜索界面的功能,需要根据自己的需求开发搜索界面。
搜索索引过程:
-
根据查询语法在倒排索引词典表中分别找出对应搜索词的索引,从而找到索引所链接的文档链表。
-
比如搜索语法为“fileName:lucene”表示搜索出fileName域中包含Lucene的文档。
-
搜索过程就是在索引上查找域为fileName,并且关键字为Lucene的term,并根据term找到文档id列表。
三、Lucene具体实现
3.1下载
可以去官网下载:Lucene:https://lucene.apache.org/
3.2实际开发要使用的jar包
lucene-analyzers-common-8.2.0.jar
lucene-core-8.2.0.jar
lucene-queryparser-8.2.0.jar
3.3代码实现
准备好要搜索的原始文档,本博主使用的是本机:

import org.apache.commons.io.FileUtils;
import org.apache.lucene.document.*;
import org.apache.lucene.index.*;
import org.apache.lucene.search.*;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.store.RAMDirectory;
import org.junit.Test;
import org.wltea.analyzer.lucene.IKAnalyzer;
import java.io.File;
/**
* 使用索引
*/
public class TestLucene1 {
@Test
/**
* 创建索引
* @throws Exception
*/
public void createIndex() throws Exception{
//1.创建一个目录对象指定索引存放位置
//把索引存放在内存
//Directory directory=new RAMDirectory();
//把索引存放在硬盘上
Directory directory= FSDirectory.open(new File("D:\\Java\\2018JavaEE传智播客IDEA版\\阶段4 1.Lucene\\index").toPath());
//2.基于Directory对象创建一个IndexWriter对象
IndexWriterConfig indexWriterConfig=new IndexWriterConfig(new IKAnalyzer()); //指定使用哪种分析器
IndexWriter indexWriter=new IndexWriter(directory,indexWriterConfig);
//3.读取硬盘上的文件,对应每个文件创建一个文档对象
File fileDir=new File("D:\\Java\\2018JavaEE传智播客IDEA版\\阶段4 1.Lucene\\Lucene\\02.参考资料\\searchsource");
File[] files=fileDir.listFiles();
for (File file:files
) {
//读取文件名
String fileName=file.getName();
//读取路径
String filePath=file.getPath();
//读取文件内容
String fileContent= FileUtils.readFileToString(file,"UTF-8");
//读取文件大小
long fileSize=FileUtils.sizeOf(file);
//创建Filed
//参数:域的名称、域的内容、是否存储
Field fieldName=new TextField("name",fileName,Field.Store.YES);
//Field fieldPath=new TextField("path",filePath,Field.Store.YES);
Field fieldPath=new StoredField("path",filePath); //默认存储
Field fieldContent=new TextField("content",fileContent,Field.Store.YES);
//Field fieldSize=new TextField("size",fileSize+"",Field.Store.YES);
Field fieldSizeValue=new LongPoint("size",fileSize); //只是作为值使用
Field fieldSizeStore=new StoredField("size",fileSize); //存储
//创建文档对象
Document document=new Document();
//向文档对象中添加域
document.add(fieldName);
document.add(fieldPath);
document.add(fieldContent);
document.add(fieldSizeValue);
document.add(fieldSizeStore);
//5.把文档对象写入索引库
indexWriter.addDocument(document);
}
//6.关闭IndexWriter
indexWriter.close();
}
/**
* 查询索引
* @throws Exception
*/
@Test
public void searchIndex() throws Exception{
//1.创建一个Directory对象,指定索引库的位置
Directory directory=FSDirectory.open(new File("D:\\Java\\2018JavaEE传智播客IDEA版\\阶段4 1.Lucene\\index").toPath());
//2.创建一个IndexReader对象
IndexReader indexReader= DirectoryReader.open(directory);
//3.创建一个IndexSearcher对象
IndexSearcher indexSearcher=new IndexSearcher(indexReader);
//4.创建一个Query对象
Query query=new TermQuery(new Term("name","Lucene"));
//5.执行查询得到一个TopDocs对象
//参数:查询对象、返回最大记录数
TopDocs topDocs=indexSearcher.search(query,10);
//6.取查询结果总记录数
System.out.println("查询结果总记录数:"+topDocs.totalHits);
//7.取文档列表
ScoreDoc[] scoreDocs=topDocs.scoreDocs;
//8.打印文档内容
for (ScoreDoc doc:scoreDocs
) {
//获取文档ID
int docId=doc.doc;
//根据ID获取文档对象
Document document=indexSearcher.doc(docId);
System.out.println("文件名:"+document.get("name"));
System.out.println("文件路径:"+document.get("path"));
System.out.println("文件大小:"+document.get("size"));
System.out.println("文件内容:"+document.get("content"));
System.out.println("-------------------------");
}
indexReader.close();
}
}
3.4使用Luke工具查看索引文件

3.5分析器
3.5.1标准分析器
-
StandardAnalyzer:
单字分词:就是按照中文一个字一个字地进行分词。如:“我爱中国”, 效果:“我”、“爱”、“中”、“国”。
-
SmartChineseAnalyzer:
对中文支持较好,但扩展性差,扩展词库,禁用词库和同义词库等不好处理
3.5.2中文分析器
IKAnalyzer
使用方法:
第一步:把jar包添加到工程中
第二步:把配置文件和扩展词典和停用词词典添加到classpath下

注意:hotword.dic和ext_stopword.dic文件的格式为UTF-8,注意是无BOM 的UTF-8 编码。
也就是说禁止使用windows记事本编辑扩展词典文件
代码:
package com.xy;
/**
* 中文分析器
*/
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.TokenStream;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.analysis.tokenattributes.CharTermAttribute;
import org.junit.Test;
import org.wltea.analyzer.lucene.IKAnalyzer;
public class TestLucene2 {
/**
* 使用标准分析器
* @throws Exception
*/
@Test
public void testTokenStream() throws Exception{
//1.创建一个Analyzer对象,使用它的子类StandardAnalyzer对象
Analyzer analyzer=new StandardAnalyzer();
//2.使用分析器的tokenStream方法,获得一个TokenStream对象
TokenStream tokenStream=analyzer.tokenStream("","Apache是世界使用排名第一的Web服务器软件。它可以运行在几乎所有广泛使用的计算机平台上,由于其跨平台和安全性被广泛使用,是最流行的Web服务器端软件之一。它快速、可靠并且可通过简单的API扩充,将Perl/Python等解释器编译到服务器中。同时Apache音译为阿帕奇,是北美印第安人的一个部落,叫阿帕奇族,在美国的西南部。也是一个基金会的名称、一种武装直升机等等。");
//3.向TokenStream对象中设置一个引用,相当于一个指针
CharTermAttribute charTermAttribute=tokenStream.addAttribute(CharTermAttribute.class);
//4.调用TokenStream对象的reset方法,如果不调用会抛出异常
tokenStream.reset();
//5.使用while循环遍历TokenStream对象
while (tokenStream.incrementToken()){
System.out.println(charTermAttribute.toString());
}
//6.关闭TokenStream对象
tokenStream.close();
}
/**
* 使用中文分析器
* @throws Exception
*/
@Test
public void testIkAnalyzer() throws Exception{
//1.创建一个Analyzer对象,使用它的子类StandardAnalyzer对象
Analyzer analyzer=new IKAnalyzer();
//2.使用分析器的tokenStream方法,获得一个TokenStream对象
TokenStream tokenStream=analyzer.tokenStream("","Apache是世界使用排名第一的Web服务器软件。它可以运行在几乎所有广泛使用的计算机平台上,由于其跨平台和安全性被广泛使用,是最流行的Web服务器端软件之一。它快速、可靠并且可通过简单的API扩充,将Perl/Python等解释器编译到服务器中。同时Apache音译为阿帕奇,是北美印第安人的一个部落,叫阿帕奇族,在美国的西南部。也是一个基金会的名称、一种武装直升机等等。");
//3.向TokenStream对象中设置一个引用,相当于一个指针
CharTermAttribute charTermAttribute=tokenStream.addAttribute(CharTermAttribute.class);
//4.调用TokenStream对象的reset方法,如果不调用会抛出异常
tokenStream.reset();
//5.使用while循环遍历TokenStream对象
while (tokenStream.incrementToken()){
System.out.println(charTermAttribute.toString());
}
//6.关闭TokenStream对象
tokenStream.close();
}
}
3.6索引库的维护(增删改)
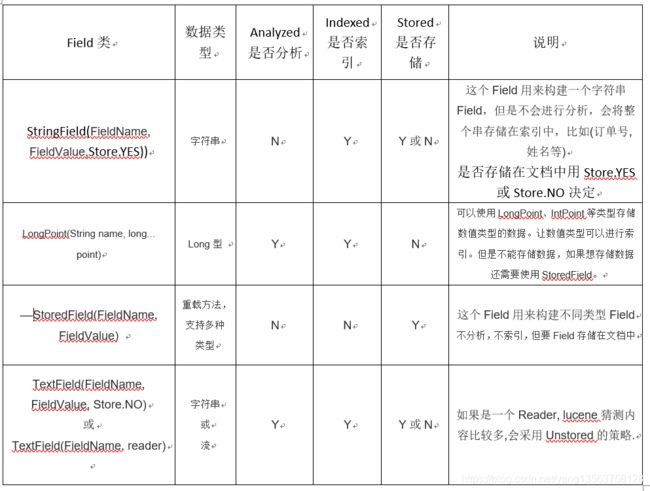
3.6.1Field域的属性
是否分析:是否对域的内容进行分词处理。前提是我们要对域的内容进行查询。
是否索引:将Field分析后的词或整个Field值进行索引,只有索引方可搜索到。
比如:商品名称、商品简介分析后进行索引,订单号、身份证号不用分析但也要索引,这些将来都要作为查询条件。
是否存储:将Field值存储在文档中,存储在文档中的Field才可以从Document中获取
比如:商品名称、订单号,凡是将来要从Document中获取的Field都要存储。
3.6.2添加文档代码
import org.apache.lucene.document.*;
import org.apache.lucene.index.*;
import org.apache.lucene.queryparser.classic.ParseException;
import org.apache.lucene.queryparser.classic.QueryParser;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.store.FSDirectory;
import org.junit.Before;
import org.junit.Test;
import org.wltea.analyzer.lucene.IKAnalyzer;
import java.io.File;
import java.io.IOException;
/**
* 维护索引
*/
public class TestLucene3 {
private IndexWriter indexWriter;
private IndexReader indexReader;
private IndexSearcher indexSearcher;
@Before
public void init() throws IOException {
indexReader= DirectoryReader.open(FSDirectory.open(new File("D:\\Java\\2018JavaEE传智播客IDEA版\\阶段4 1.Lucene\\index").toPath()));
indexSearcher=new IndexSearcher(indexReader);
}
/**
* 声明IndexWriter对象
*/
@Before
public void indexWriter() throws IOException {
//1.创建一个IndexWriter对象,指定分析所用的分析器
indexWriter=new IndexWriter(FSDirectory.open(new File("D:\\Java\\2018JavaEE传智播客IDEA版\\阶段4 1.Lucene\\index").toPath()),
new IndexWriterConfig(new IKAnalyzer()));
}
/**
* 添加文档
*/
@Test
public void addDocument() throws IOException {
//1.创建一个IndexWriter对象,指定分析所用的分析器
IndexWriter indexWriter=new IndexWriter(FSDirectory.open(new File("D:\\Java\\2018JavaEE传智播客IDEA版\\阶段4 1.Lucene\\index").toPath()),
new IndexWriterConfig(new IKAnalyzer()));
//2.创建一个Document对象
Document document=new Document();
//3.向文档中添加域
document.add(new TextField("name","新添加的文件", Field.Store.YES));
document.add(new TextField("content","新添加的文件内容", Field.Store.NO));
document.add(new StoredField("path","D:\\Java\\2018JavaEE传智播客IDEA版\\阶段4 1.Lucene\\temp"));
//4.把文档写入索引库
indexWriter.addDocument(document);
//5.关闭索引库
indexWriter.close();
}
}
3.6.3删除索引库
package com.xy;
import org.apache.lucene.document.*;
import org.apache.lucene.index.*;
import org.apache.lucene.queryparser.classic.ParseException;
import org.apache.lucene.queryparser.classic.QueryParser;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.store.FSDirectory;
import org.junit.Before;
import org.junit.Test;
import org.wltea.analyzer.lucene.IKAnalyzer;
import java.io.File;
import java.io.IOException;
/**
* 维护索引
*/
public class TestLucene3 {
private IndexWriter indexWriter;
private IndexReader indexReader;
private IndexSearcher indexSearcher;
@Before
public void init() throws IOException {
indexReader= DirectoryReader.open(FSDirectory.open(new File("D:\\Java\\2018JavaEE传智播客IDEA版\\阶段4 1.Lucene\\index").toPath()));
indexSearcher=new IndexSearcher(indexReader);
}
/**
* 声明IndexWriter对象
*/
@Before
public void indexWriter() throws IOException {
//1.创建一个IndexWriter对象,指定分析所用的分析器
indexWriter=new IndexWriter(FSDirectory.open(new File("D:\\Java\\2018JavaEE传智播客IDEA版\\阶段4 1.Lucene\\index").toPath()),
new IndexWriterConfig(new IKAnalyzer()));
}
/**
* 删除文档
*/
@Test
public void deleteDocument() throws IOException {
//删除全部文档
indexWriter.deleteAll();
//关闭索引库
indexWriter.close();
}
/**
* 通过查询删除文档
* @throws IOException
*/
@Test
public void deleteByQuery() throws IOException {
indexWriter.deleteDocuments(new Term("name","Lucene"));
}
@Test
public void updateDocument() throws IOException {
//创建一个新的文档对象
Document document=new Document();
//向文档中添加域
document.add(new TextField("name","更新之后的文档",Field.Store.YES));
document.add(new TextField("name1","更新之后的文档2",Field.Store.YES));
document.add(new TextField("name2","更新之后的文档3",Field.Store.YES));
//更新操作
indexWriter.updateDocument(new Term("name","Lucene"),document);
//关闭索引库
indexWriter.close();
}
private void printResults(Query query) throws IOException {
//执行查询
TopDocs topDocs=indexSearcher.search(query,10);
System.out.println("总记录数:"+topDocs.totalHits);
ScoreDoc[] scoreDocs=topDocs.scoreDocs;
//打印文档内容
for (ScoreDoc doc:scoreDocs
) {
//获取文档ID
int docId=doc.doc;
//根据ID获取文档对象
Document document=indexSearcher.doc(docId);
System.out.println("文件名:"+document.get("name"));
System.out.println("文件路径:"+document.get("path"));
System.out.println("文件大小:"+document.get("size"));
System.out.println("文件内容:"+document.get("content"));
System.out.println("-------------------------");
}
indexReader.close();
}
}
3.6.4索引库的修改
package com.xy;
import org.apache.lucene.document.*;
import org.apache.lucene.index.*;
import org.apache.lucene.queryparser.classic.ParseException;
import org.apache.lucene.queryparser.classic.QueryParser;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.store.FSDirectory;
import org.junit.Before;
import org.junit.Test;
import org.wltea.analyzer.lucene.IKAnalyzer;
import java.io.File;
import java.io.IOException;
/**
* 维护索引
*/
public class TestLucene3 {
private IndexWriter indexWriter;
private IndexReader indexReader;
private IndexSearcher indexSearcher;
@Before
public void init() throws IOException {
indexReader= DirectoryReader.open(FSDirectory.open(new File("D:\\Java\\2018JavaEE传智播客IDEA版\\阶段4 1.Lucene\\index").toPath()));
indexSearcher=new IndexSearcher(indexReader);
}
/**
* 声明IndexWriter对象
*/
@Before
public void indexWriter() throws IOException {
//1.创建一个IndexWriter对象,指定分析所用的分析器
indexWriter=new IndexWriter(FSDirectory.open(new File("D:\\Java\\2018JavaEE传智播客IDEA版\\阶段4 1.Lucene\\index").toPath()),
new IndexWriterConfig(new IKAnalyzer()));
}
@Test
public void updateDocument() throws IOException {
//创建一个新的文档对象
Document document=new Document();
//向文档中添加域
document.add(new TextField("name","更新之后的文档",Field.Store.YES));
document.add(new TextField("name1","更新之后的文档2",Field.Store.YES));
document.add(new TextField("name2","更新之后的文档3",Field.Store.YES));
//更新操作
indexWriter.updateDocument(new Term("name","Lucene"),document);
//关闭索引库
indexWriter.close();
}
}
3.6.5索引库的查询
对要搜索的信息创建Query查询对象,Lucene会根据Query查询对象生成最终的查询语法,类似关系数据库Sql语法一样Lucene也有自己的查询语法,比如:“name:lucene”表示查询Field的name为“lucene”的文档信息。
可通过两种方法创建查询对象:
1)使用Lucene提供Query子类
2)使用QueryParse解析查询表达式
1.TermQuery
TermQuery,通过项查询,TermQuery不使用分析器所以建议匹配不分词的Field域查询,比如订单号、分类ID号等。
指定要查询的域和要查询的关键词。
2.数值范围查询
code:
package com.xy;
import org.apache.lucene.document.*;
import org.apache.lucene.index.*;
import org.apache.lucene.queryparser.classic.ParseException;
import org.apache.lucene.queryparser.classic.QueryParser;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.store.FSDirectory;
import org.junit.Before;
import org.junit.Test;
import org.wltea.analyzer.lucene.IKAnalyzer;
import java.io.File;
import java.io.IOException;
/**
* 维护索引
*/
public class TestLucene3 {
private IndexWriter indexWriter;
private IndexReader indexReader;
private IndexSearcher indexSearcher;
@Before
public void init() throws IOException {
indexReader= DirectoryReader.open(FSDirectory.open(new File("D:\\Java\\2018JavaEE传智播客IDEA版\\阶段4 1.Lucene\\index").toPath()));
indexSearcher=new IndexSearcher(indexReader);
}
/**
* 声明IndexWriter对象
*/
@Before
public void indexWriter() throws IOException {
//1.创建一个IndexWriter对象,指定分析所用的分析器
indexWriter=new IndexWriter(FSDirectory.open(new File("D:\\Java\\2018JavaEE传智播客IDEA版\\阶段4 1.Lucene\\index").toPath()),
new IndexWriterConfig(new IKAnalyzer()));
}
private void printResults(Query query) throws IOException {
//执行查询
TopDocs topDocs=indexSearcher.search(query,10);
System.out.println("总记录数:"+topDocs.totalHits);
ScoreDoc[] scoreDocs=topDocs.scoreDocs;
//打印文档内容
for (ScoreDoc doc:scoreDocs
) {
//获取文档ID
int docId=doc.doc;
//根据ID获取文档对象
Document document=indexSearcher.doc(docId);
System.out.println("文件名:"+document.get("name"));
System.out.println("文件路径:"+document.get("path"));
System.out.println("文件大小:"+document.get("size"));
System.out.println("文件内容:"+document.get("content"));
System.out.println("-------------------------");
}
indexReader.close();
}
/**
* 测试查询
*/
@Test
public void searchDocument() throws IOException {
//创建一个Query对象
Query query= LongPoint.newRangeQuery("size",0l,10000l);
//查询结果
printResults(query);
}
}
3.QueryParser查询
通过QueryParser也可以创建Query,QueryParser提供一个Parse方法,此方法可以直接根据查询语法来查询。Query对象执行的查询语法可通过System.out.println(query);查询。
需要使用到分析器。建议创建索引时使用的分析器和查询索引时使用的分析器要一致。
需要加入queryParser依赖的jar包。
lucene-queryparser-8.2.0.jar
code:
package com.xy;
import org.apache.lucene.document.*;
import org.apache.lucene.index.*;
import org.apache.lucene.queryparser.classic.ParseException;
import org.apache.lucene.queryparser.classic.QueryParser;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.store.FSDirectory;
import org.junit.Before;
import org.junit.Test;
import org.wltea.analyzer.lucene.IKAnalyzer;
import java.io.File;
import java.io.IOException;
/**
* 维护索引
*/
public class TestLucene3 {
private IndexWriter indexWriter;
private IndexReader indexReader;
private IndexSearcher indexSearcher;
@Before
public void init() throws IOException {
indexReader= DirectoryReader.open(FSDirectory.open(new File("D:\\Java\\2018JavaEE传智播客IDEA版\\阶段4 1.Lucene\\index").toPath()));
indexSearcher=new IndexSearcher(indexReader);
}
/**
* 声明IndexWriter对象
*/
@Before
public void indexWriter() throws IOException {
//1.创建一个IndexWriter对象,指定分析所用的分析器
indexWriter=new IndexWriter(FSDirectory.open(new File("D:\\Java\\2018JavaEE传智播客IDEA版\\阶段4 1.Lucene\\index").toPath()),
new IndexWriterConfig(new IKAnalyzer()));
}
private void printResults(Query query) throws IOException {
//执行查询
TopDocs topDocs=indexSearcher.search(query,10);
System.out.println("总记录数:"+topDocs.totalHits);
ScoreDoc[] scoreDocs=topDocs.scoreDocs;
//打印文档内容
for (ScoreDoc doc:scoreDocs
) {
//获取文档ID
int docId=doc.doc;
//根据ID获取文档对象
Document document=indexSearcher.doc(docId);
System.out.println("文件名:"+document.get("name"));
System.out.println("文件路径:"+document.get("path"));
System.out.println("文件大小:"+document.get("size"));
System.out.println("文件内容:"+document.get("content"));
System.out.println("-------------------------");
}
indexReader.close();
}
@Test
public void searchDocumentByQueryParse() throws ParseException, IOException {
//创建一个QueryParse对象
//参数:默认搜索域、分析器对象
QueryParser queryParser=new QueryParser("name",new IKAnalyzer());
//使用后一个QueryParse对象创建一个Query对象
Query query=queryParser.parse("Spring框架");
//执行查询
printResults(query);
}
}