在docker上部署centos+hadoop3.0分布式集群
完整步骤的思维导图
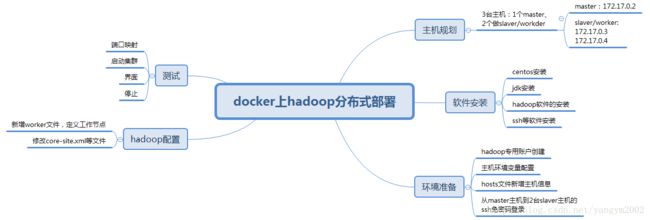
一、主机规划
3台主机:1个master、2个slaver/worker
ip地址使用docker默认的分配地址:
master:
主机名: hadoop2、ip地址: 172.17.0.2
slaver1:
主机名: hadoop3、ip地址: 172.17.0.3
主机名: hadoop4、ip地址: 172.17.0.4
二、软件安装
1、在docker中安装centos镜像,并启动centos容器,安装ssh。
--详见"docker上安装centos镜像"一文。
2、通过ssh连接到centos容器,安装jdk1.8、hadoop3.0
可以按照传统linux安装软件的方法,通过将jdk和hadoop的tar包上传到主机进行安装。
三、环境准备
1、创建hadoop专属账户
a、创建用户 useradd -m -s /bin/bash hadoop
b、修改密码 passwd hadoop
2、环境变量配置
前提:完成上一步骤,并使用hadoop用户登录
a、JAVA_HOME环境变量设置
修改用户根目录下的.bash_profile文件添加jdk的跟目录
b、HADOOP_HOME环境变量设置
修改用户根目录下的.bash_profile文件添加hadoop安装的根目录
c、将jdk和hadoop的bin、sbin目录添加到PATH环境变量中

3、在/etc/hosts文件中添加3台主机的主机名和ip地址对应信息
172.17.0.2 hadoop2
172.17.0.3 hadoop3
172.17.0.4 hadoop4
172.17.0.3 hadoop3
172.17.0.4 hadoop4
在docker中直接修改/etc/hosts文件,在重启容器后会被重置、覆盖。因此需要通过容器启动脚本docker run的--add-host参数将主机和ip地址的对应关系传入,容器在启动后会写入hosts文件中。如:
docker run --name hadoop2
--add-host hadoop2:172.17.0.2 --add-host hadoop3:172.17.0.3 --add-host hadoop4:172.17.0.4 -it centos
4、配置ssh免密码登录
$ ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
$ chmod 0600 ~/.ssh/authorized_keys
四、hadoop部署
1、在workers文件中定义工作节点
在hadoop根目录下的etc/hadoop目录下新建workers文件,并添加工作节点主机信息。
按照步骤一中的主机规划,工作节点主机为hadoop3和hadoop4两台主机。如:
[hadoop@2e1b5caaf225 ~]$ cat hadoop-3.0.0/etc/hadoop/workers
hadoop3
hadoop4
2、修改配置文件信息
a、在hadoop-env.sh中,添加JAVA_HOME信息
# JAVA_HOME=/usr/java/testing hdfs dfs -ls
JAVA_HOME=/usr/local/jdk1.8.0_131/
b、core-site.xml
c、hdfs-site.xml
d、yarn-site.xml
e、mapred-site.xml
注意:
以上步骤完成以后停止当前容器,并使用docker命令保持到一个新的镜像。使用新的镜像重新启动集群,这样集群每台机器都有相同的账户、配置和软件,无需再重新配置。如:
a、停止容器
docker stop hadoop2
b、保存镜像
docker commit hadoop2 centos_me:v1.0
五、测试
1、端口映射
集群启动后,需要通过web界面观察集群的运行情况,因此
需要将容器的端口映射到宿主主机的端口上,可以通过docker run命令的-p选项完成。比如:
将yarn任务调度端口映射到宿主主机8088端口上:
docker run -it -p 8088:8088 centos
2、从新镜像启动3个容器
docker run --name hadoop2 --add-host hadoop2:172.17.0.2 --add-host hadoop3:172.17.0.3 --add-host hadoop4:172.17.0.4 -d -p 5002:22 -p 9870:9870 -p 8088:8088 -p 19888:19888 centos_me:v1.0 /usr/sbin/sshd -D
docker run --name hadoop3 --add-host hadoop2:172.17.0.2 --add-host hadoop3:172.17.0.3 --add-host hadoop4:172.17.0.4 -d -p 5003:22 centos_me:v1.0 /usr/sbin/sshd -D
docker run --name hadoop4 --add-host hadoop2:172.17.0.2 --add-host hadoop3:172.17.0.3 --add-host hadoop4:172.17.0.4 -d -p 5004:22 centos_me:v1.0 /usr/sbin/sshd -D
3、在master主机上执行start-all.sh脚本启动集群
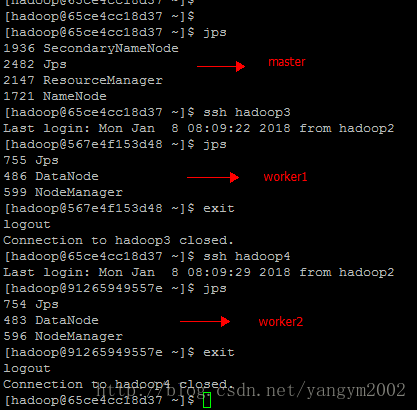
4、在3个容器中依次使用jps命令查看进程是否启动
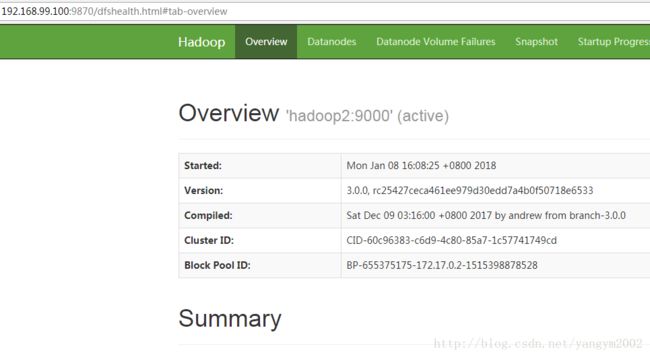
4、通过web页面访问
遇到的问题:
1、启动hadoop报没有which命令
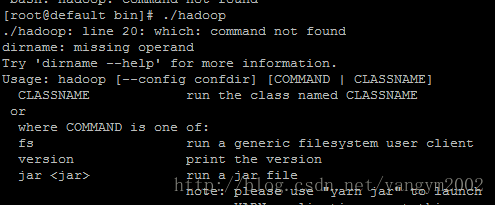
a、查找which命令所在的包
使用yum search 命令查找
b、安装which包
2、ssh登录指定端口
ssh -p端口 用户@ip
3、修改/etc/hosts文件添加主机名和ipd地址映射后,重启容器新加配置丢失的解决
在启动run脚本中通过--add-host添加主机和ip的映射关系,如:
docker run --name hadoop2 --add-host hadoop2:172.17.0.2 --add-host hadoop3:172.17.0.3 --add-host hadoop4:172.17.0.4 -d -p 5002:22 centos_me:v1.0 /usr/sbin/sshd -D
4、执行wordcount例子报异常
异常一:
2018-01-09 02:50:43,320 INFO mapreduce.Job: Job job_1515466125577_0002 failed with state FAILED due to: Application application_1515466125577_0002 failed 2 times due to AM Container for appattempt_1515466125577_0002_000002 exited with exitCode: 127
Failing this attempt.Diagnostics: [2018-01-09 02:50:42.706]Exception from container-launch.
Container id: container_1515466125577_0002_02_000001
Exit code: 127
[2018-01-09 02:50:42.750]Container exited with a non-zero exit code 127. Error file: prelaunch.err.
Last 4096 bytes of prelaunch.err :
Last 4096 bytes of stderr :
/bin/bash: /bin/java: No such file or directory
解决方法:在中添加adoop-3.0.0/libexec/hadoop-config.sh文件中添加JAVA_HOME环境变量
异常二:
2018-01-09 03:25:37,250 INFO mapreduce.Job: Job job_1515468264727_0001 failed with state FAILED due to: Application application_1515468264727_0001 failed 2 times due to AM Container for appattempt_1515468264727_0001_000002 exited with exitCode: 1
Failing this attempt.Diagnostics: [2018-01-09 03:25:36.447]Exception from container-launch.
Container id: container_1515468264727_0001_02_000001
Exit code: 1
[2018-01-09 03:25:36.499]Container exited with a non-zero exit code 1. Error file: prelaunch.err.
Last 4096 bytes of prelaunch.err :
Last 4096 bytes of stderr :
Error: Could not find or load main class org.apache.hadoop.mapreduce.v2.app.MRAppMaster
Please check whether your etc/hadoop/mapred-site.xml contains the below configuration:
解决方法:按错误提示,在mapred-site.xml配置文件中添加hadoop根目录
异常三:
2018-01-09 03:55:18,863 INFO mapreduce.Job: Job job_1515470038765_0001 failed with state FAILED due to: Application application_1515470038765_0001 failed 2 times due to AM Container for appattempt_1515470038765_0001_000002 exited with exitCode: -103
Failing this attempt.Diagnostics: [2018-01-09 03:55:17.480]Container [pid=728,containerID=container_1515470038765_0001_02_000001] is running beyond virtual memory limits. Current usage: 146.5 MB of 1 GB physical memory used; 2.7 GB of 2.1 GB virtual memory used. Killing container.
Dump of the process-tree for container_1515470038765_0001_02_000001 :
|- PID PPID PGRPID SESSID CMD_NAME USER_MODE_TIME(MILLIS) SYSTEM_TIME(MILLIS) VMEM_USAGE(BYTES) RSSMEM_USAGE(PAGES) FULL_CMD_LINE
|- 741 728 728 728 (java) 634 19 2852925440 37258 /usr/local/jdk1.8.0_131/bin/java -Djava.io.tmpdir=/home/hadoop/tmp/nm-local-dir/usercache/hadoop/appcache/application_1515470038765_0001/container_1515470038765_0001_02_000001/tmp -Dlog4j.configuration=container-log4j.properties -Dyarn.app.container.log.dir=/home/hadoop/hadoop-3.0.0/logs/userlogs/application_1515470038765_0001/container_1515470038765_0001_02_000001 -Dyarn.app.container.log.filesize=0 -Dhadoop.root.logger=INFO,CLA -Dhadoop.root.logfile=syslog -Xmx1024m org.apache.hadoop.mapreduce.v2.app.MRAppMaster
解决方法:在yarn-site.xml中添加以下配置
for containers. Container allocations are expressed in terms of physical memory, and
virtual memory usage is allowed to exceed this allocation by this ratio.
参考
https://stackoverflow.com/questions/14110428/am-container-is-running-beyond-virtual-memory-limits