并查集-用并查集判断图中是否有环(能够应用到kruskal的最小生成树)
先不介绍并查集的概念,先从它的应用说起吧,它有两个功能,第一就是判断给定的一个节点是否属于某一个集合,更确切的说是属于哪个集合。第二个功能就是合并两个集合。
给定一组数据,如:1, 2, 3, 4, 5, 6, 7, 8, 9,他们是一个大的集合,但是也可以将他们每一个数字看成一个独立的集合,然后我们通过合并来形成一个由他们所有组成的大集合。有的人很奇怪,他们已经是一个集合了,为什么还要重新把他们组织起来呢,而且如果要查找某一个元素我们直接遍历这个集合不就可以了吗,时间复杂度是线性的。熟悉并查集的人可能会马上说出:利用并查集的两种操作:并和查,我们就能够重新组织这些数字,当他们有一定的逻辑,在查找和合并的时候都能够在小于线性的时间内完成。用什么表示并查集呢,我们应用树的表示形式,但是我们不创建树的节点,而是应用一个parent数字来表示当前索引为index的元素的祖先是谁。
上述的例子: i = 1, 2, ..., 9, parent[i] = i, 说明对于拥有单个元素的集合来说,它的根就是它本身,接下来遍历一遍数组,建立并查集:
对于1, 2, 他们的parent[1] = 1, parent[2] = 2, 只要祖先不一样,说明他们属于不同的集合,那么就要合并他们,那让1,还是2来当做祖先呢,可以自由的选择,稍后我会讲述,这样的随便可能会造成最后并查集同于普通的集合,失去了快速超找的优势。合并之后,就会出现有两个元素的集合,他们以树的形式表示的时候祖先设定为1,然后合并另外两个集合{1, 2}和{3}, 首先判断他们是否在同一个集合内,很简单,就是判断这两个集合用树的形式表示的时候是不是有着共同的祖先,第一个集合的祖先是1, 第二个集合的祖先是3,很显然,不一样,所以就要进行合并。以此类推,直到所有单个集合被合并为止。上面有可能造成并查集同于普通集合的关键就是在于在合并两个集合的时候,根节点的选取,如果A, 始终是大的集合,B 始终是小的集合,例如:{1, 2}和{3}, {1, 2, 3}和{4}, {1, 2, 3, 4}和{5}, 那么如果始终把小的集合的根当做合并后集合的根的话,那么并查集最后用树的形式表示出来的时候就是像链表的形式。所以需要一种平衡策略,就是用上述相反的方法来做:把集合元素大的集合的根作为两个集合合并后的根。这样树的高度就会降低。同时还要应用路径压缩的方法,来降低树的高度。
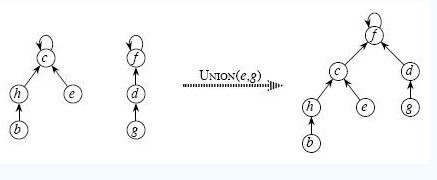
上图是并查集合并的例子。
给出查找和合并的基本代码:
int find(int x) {
int r = x;
while (parents[r] != r)
r = parents[r];
int i = x, j;
while (i != r) {
j = parents[i];
parents[i] = r;
i = j;
}
return i;
}初次可能看不明白这个代码,不要着急,给大家一个连接,看完这边,应该就能懂路径压缩了:http://blog.csdn.net/dellaserss/article/details/7724401
并查集合并的代码:
oid _union(int x, int y) {
int fx = find(x);
int fy = find(y);
if (fx == fy)
return;
if (rank[x] > rank[y]) {
parents[y] = x;
} else {
if (rank[x] == rank[y])
rank[y]++;
parents[x] = y;
}
}设定rank数组是为了降低树的高度。
上面的代码如果看不太懂,理解不太透彻,那就用一个例子来帮助大家理解吧,应用并查集来判断一个图中是否有环。
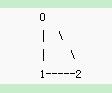
这个图有环是已知的吧,但是要用代码来判断,就很复杂,首先我们把每个点看成独立的集合{0} ,{1}, {2}, 然后规定如果两个点之间有边相连,如果这两个点不属于同一个集合,那就将他们所属的结合合并,看边0-1,直接将这两个点代表的集合合并{0, 1}, 其中让1来当父节点, 看边1-2, 它们分别属于不同的集合,合并集合之后是{1, 2},让2来当父节点,依照这种逻辑关系,0的祖先节点就是2, 然后在看边0-2,他们属于一个集合,因为他们有着共同的祖先2, 这就说明0-2之间在没有0-2这条边之前已经连通了,如果在加上这条边的话那从0到2就有两条路径可达,就说明存在一个环了,下面给出代码:
#include
#include
using namespace std;
typedef struct edge_s {
int src;
int dst;
}edge_t;
class Graph {
private:
int arc_num;
int vex_num;
int *parents;
int *rank;
edge_t *arcs;
public:
Graph(int _vex_num, int _arc_num) {
arc_num = _arc_num;
vex_num = _vex_num;
arcs = new edge_t[arc_num];
parents = new int[vex_num];
for (int i = 0; i < vex_num; i++)
parents[i] = i;
rank = new int[vex_num];
memset(rank, 0, vex_num * sizeof(int));
}
~Graph() {
delete []arcs;
delete []parents;
delete []rank;
}
void setEdge(int index, int src, int dst);
int getArcNum();
int getVexNum();
int getEdgeSrc(int index);
int getEdgeDst(int index);
int find(int x);
void _union(int x, int y);
};
void Graph::setEdge(int index, int src, int dst) {
if (index < arc_num) {
arcs[index].src = src;
arcs[index].dst = dst;
}
}
int Graph::getArcNum() {
return arc_num;
}
int Graph::getVexNum() {
return vex_num;
}
int Graph::getEdgeSrc(int index) {
return arcs[index].src;
}
int Graph::getEdgeDst(int index) {
return arcs[index].dst;
}
int Graph::find(int x) {
int r = x;
while (parents[r] != r)
r = parents[r];
int i = x, j;
while (i != r) {
j = parents[i];
parents[i] = r;
i = j;
}
return i;
}
void Graph::_union(int x, int y) {
int fx = find(x);
int fy = find(y);
if (fx == fy)
return;
if (rank[x] > rank[y]) {
parents[y] = x;
} else {
if (rank[x] == rank[y])
rank[y]++;
parents[x] = y;
}
}
bool isContainCycle(Graph &g) {
int i;
for (i = 0; i < g.getArcNum(); i++) {
int fx = g.find(g.getEdgeSrc(i));
int fy = g.find(g.getEdgeDst(i));
if (fx == fy)
return true;
g._union(fx, fy);
}
return false;
}
int main(int argc, char *argv[]) {
Graph g = Graph(3, 3);
g.setEdge(0, 0, 1);
g.setEdge(1, 1, 2);
g.setEdge(2, 0, 2);
if (isContainCycle(g))
cout << "yes" << endl;
else
cout << "non" << endl;
cin.get();
return 0;
}