波士顿房价预测任务(线性回归模型)
写在前面: 我是「虐猫人薛定谔i」,一个不满足于现状,有梦想,有追求的00后
\quad
本博客主要记录和分享自己毕生所学的知识,欢迎关注,第一时间获取更新。
\quad
不忘初心,方得始终。
\quad❤❤❤❤❤❤❤❤❤❤
数据介绍
该数据集统计了13种可能影响房价的因素和该类型房屋的均价,我们期望构建一个基于13个因素进行房价预测的模型。

代码
import numpy as np
import matplotlib.pyplot as plt
def load_data():
# 从文件导入数据
datafile = './res/housing.data'
data = np.fromfile(datafile, sep=' ')
feature_names = [
'CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE', 'DIS', 'RAD', 'TAX',
'PTRATIO', 'B', 'LSTAT', 'MEDV'
]
feature_num = len(feature_names)
data = data.reshape([data.shape[0] // feature_num, feature_num])
ratio = 0.8
offset = int(data.shape[0] * ratio)
training_data = data[:offset]
maximums, minimums, avgs = training_data.max(axis=0), training_data.min(
axis=0), training_data.sum(axis=0) / training_data.shape[0]
for i in range(feature_num):
data[:, i] = (data[:, i] - avgs[i]) / (maximums[i] - minimums[i])
training_data = data[:offset]
test_data = data[offset:]
return training_data, test_data
class Network(object):
def __init__(self, num_of_weights):
np.random.seed(0)
self.w = np.random.randn(num_of_weights, 1)
self.b = 0
def forward(self, x):
z = np.dot(x, self.w) + self.b
return z
def loss(self, z, y):
error = z - y
num_samples = error.shape[0]
cost = error * error
cost = np.sum(cost) / num_samples
return cost
def gradient(self, x, y):
z = self.forward(x)
gradient_w = (z - y) * x
gradient_w = np.mean(gradient_w, axis=0)
gradient_w = gradient_w[:, np.newaxis]
gradient_b = (z - y)
gradient_b = np.mean(gradient_b)
return gradient_w, gradient_b
def update(self, gradient_w, gradient_b, eta=0.01):
self.w = self.w - eta * gradient_w
self.b = self.b - eta * gradient_b
def train(self, x, y, iterations=100, eta=0.01):
losses = []
for i in range(iterations):
z = self.forward(x)
L = self.loss(z, y)
gradient_w, gradient_b = self.gradient(x, y)
self.update(gradient_w, gradient_b, eta)
losses.append(L)
if (i + 1) % 10 == 0:
print("iter {}, loss {}".format(i, L))
return losses
# 加载数据
training_data, test_data = load_data()
x = training_data[:, :-1]
y = training_data[:, -1:]
# 创建网络
net = Network(13)
num_iterations = 1000
# 训练
losses = net.train(x, y, iterations=num_iterations, eta=0.01)
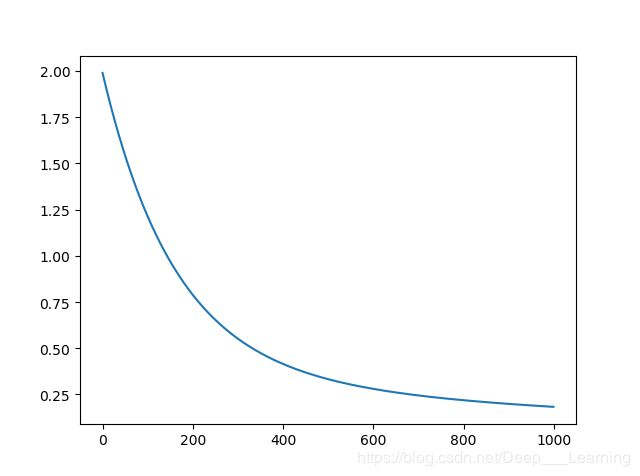
# 画出损失函数的变化趋势
plot_x = np.arange(num_iterations)
plot_y = np.array(losses)
plt.plot(plot_x, plot_y)
plt.show()
结果
iter 9, loss 1.898494731457622
iter 19, loss 1.8031783384598723
iter 29, loss 1.7135517565541092
iter 39, loss 1.6292649416831266
iter 49, loss 1.5499895293373234
iter 59, loss 1.4754174896452612
iter 69, loss 1.4052598659324693
iter 79, loss 1.3392455915676866
iter 89, loss 1.2771203802372915
iter 99, loss 1.218645685090292
iter 109, loss 1.1635977224791534
iter 119, loss 1.111766556287068
iter 129, loss 1.0629552390811503
iter 139, loss 1.0169790065644477
iter 149, loss 0.9736645220185994
iter 159, loss 0.9328491676343147
iter 169, loss 0.8943803798194311
iter 179, loss 0.8581150257549611
iter 189, loss 0.8239188186389671
iter 199, loss 0.7916657692169988
iter 209, loss 0.761237671346902
iter 219, loss 0.7325236194855752
iter 229, loss 0.7054195561163928
iter 239, loss 0.6798278472589763
iter 249, loss 0.6556568843183528
iter 259, loss 0.6328207106387195
iter 269, loss 0.6112386712285091
iter 279, loss 0.59083508421862
iter 289, loss 0.5715389327049418
iter 299, loss 0.5532835757100347
iter 309, loss 0.5360064770773407
iter 319, loss 0.5196489511849665
iter 329, loss 0.5041559244351539
iter 339, loss 0.48947571154034963
iter 349, loss 0.47555980568755696
iter 359, loss 0.46236268171965056
iter 369, loss 0.44984161152579916
iter 379, loss 0.43795649088328303
iter 389, loss 0.42666967704002257
iter 399, loss 0.41594583637124666
iter 409, loss 0.4057518014851036
iter 419, loss 0.3960564371908221
iter 429, loss 0.38683051477942226
iter 439, loss 0.3780465941011246
iter 449, loss 0.3696789129556087
iter 459, loss 0.36170328334131785
iter 469, loss 0.3540969941381648
iter 479, loss 0.3468387198244131
iter 489, loss 0.3399084348532937
iter 499, loss 0.33328733333814486
iter 509, loss 0.32695775371667785
iter 519, loss 0.32090310808539985
iter 529, loss 0.31510781591441284
iter 539, loss 0.30955724187078903
iter 549, loss 0.3042376374955925
iter 559, loss 0.29913608649543905
iter 569, loss 0.29424045342432864
iter 579, loss 0.2895393355454012
iter 589, loss 0.28502201767532415
iter 599, loss 0.28067842982626157
iter 609, loss 0.27649910747186535
iter 619, loss 0.2724751542744919
iter 629, loss 0.2685982071209627
iter 639, loss 0.26486040332365085
iter 649, loss 0.2612543498525749
iter 659, loss 0.2577730944725093
iter 669, loss 0.2544100986669443
iter 679, loss 0.2511592122380609
iter 689, loss 0.2480146494787638
iter 699, loss 0.24497096681926714
iter 709, loss 0.2420230418567801
iter 719, loss 0.23916605368251415
iter 729, loss 0.23639546442555456
iter 739, loss 0.23370700193813698
iter 749, loss 0.23109664355154746
iter 759, loss 0.2285606008362593
iter 769, loss 0.22609530530403904
iter 779, loss 0.2236973949936189
iter 789, loss 0.22136370188515428
iter 799, loss 0.21909124009208833
iter 809, loss 0.21687719478222933
iter 819, loss 0.21471891178284028
iter 829, loss 0.21261388782734392
iter 839, loss 0.2105597614038757
iter 849, loss 0.20855430416838638
iter 859, loss 0.20659541288730932
iter 869, loss 0.20468110187697833
iter 879, loss 0.2028094959090178
iter 889, loss 0.20097882355283644
iter 899, loss 0.19918741092814593
iter 909, loss 0.1974336758421087
iter 919, loss 0.1957161222872899
iter 929, loss 0.19403333527807176
iter 939, loss 0.19238397600456975
iter 949, loss 0.19076677728439415
iter 959, loss 0.18918053929381623
iter 969, loss 0.18762412556104593
iter 979, loss 0.18609645920539716
iter 989, loss 0.18459651940712488
iter 999, loss 0.18312333809366155
蒟蒻写博客不易,加之本人水平有限,写作仓促,错误和不足之处在所难免,谨请读者和各位大佬们批评指正。
如需转载,请署名作者并附上原文链接,蒟蒻非常感激
名称:虐猫人薛定谔i
博客地址:https://blog.csdn.net/Deep___Learning